近期必读的5篇顶会CVPR 2021【图像分类】相关论文和代码
1. A Realistic Evaluation of Semi-Supervised Learning for Fine-Grained Classification
作者:Jong-Chyi Su, Zezhou Cheng, Subhransu Maji
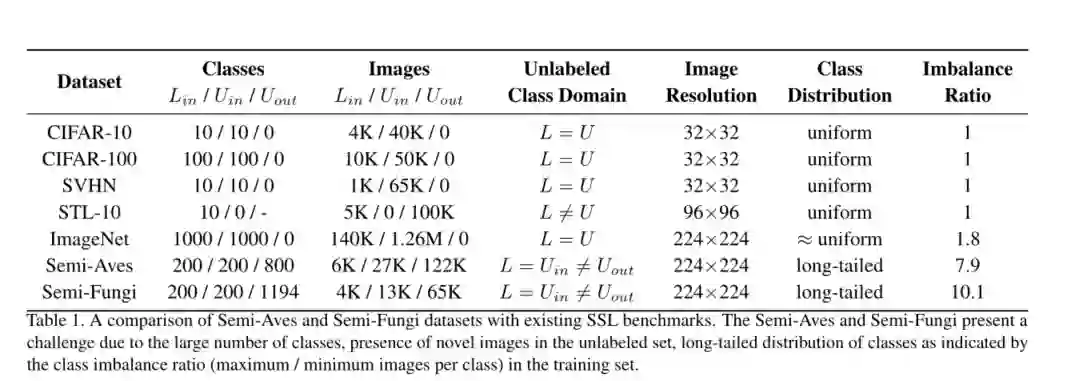
摘要:我们在一个现实的基准上评估半监督学习(SSL)的有效性,在该基准上,数据表现出明显的类别失衡并包含来自新类别的图像。我们的基准测试由两个细粒度的分类数据集组成,这些数据集是通过从Aves和Fungi分类中对类进行抽样而获得的。我们发现,最近提出的SSL方法具有显着的优势,并且当从头开始训练深度网络时,可以有效地使用类外(out-of-class)数据来提高性能。然而,与迁移学习基准相比,这部分表现却差强人意。另外,尽管现有的SSL方法提供了一些改进,但是类外数据的存在通常对模型的性能反而有害。在这种情况下,微调后再进行基于蒸馏的自训练反而是最可靠的。我们的实验表明,在现实数据集上的基于专家的半监督学习可能需要一些不同的策略,这部分策略与现在流行的方法可能不同。
网址:
https://www.zhuanzhi.ai/paper/d76543074cacef9895afe0f4b57e995e
2. Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification
作者:Peng Wang, Kai Han, Xiu-Shen Wei, Lei Zhang, Lei Wang
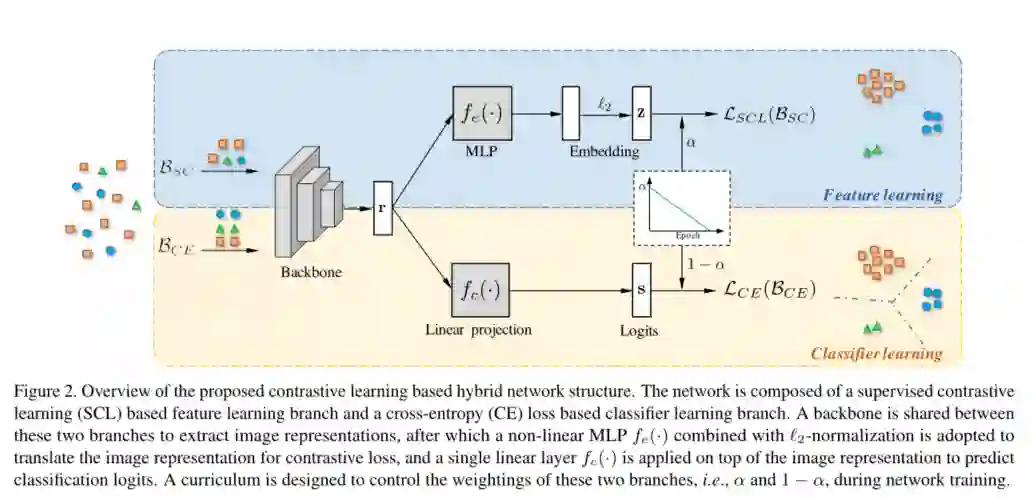
摘要:学习得到图像的判别性表示在长尾(long-tailed)图像分类中起着至关重要的作用,因为它可以缓解分类器在数据不平衡情况下的学习。鉴于最近对比学习的表现,在这项工作中,我们探讨了有效的监督对比学习策略,并定制了他们从不平衡数据学习更好的图像表示的方法,以提高其上的分类精度。具体来说,我们提出了一种新颖的混合网络结构,该结构由监督的对比损失(用于学习图像表示)和交叉熵损失(用于学习分类器)组成,其中学习逐渐从特征学习过渡到分类器学习,以体现更好的特征训练更好的分类器。我们探索了用于特征学习的两种对比损失形式,它们的形式各不相同,但有一个共同的想法,即在归一化嵌入空间中将同一类别的样本拉在一起,然后将不同类别的样本推开。其中之一是最近提出的监督对比(SC)损失,它是通过合并来自同一类别的正样本在最先进的无监督对比损失之上设计的。另一种是原型监督对比(PSC)学习策略,该策略解决了标准SC丢失中的大量内存消耗问题,因此在有限的内存预算下显示出更多的希望。在三个长尾分类数据集上的广泛实验证明了在长尾分类中所提出的基于对比学习的混合网络的优势。
网址:
https://www.zhuanzhi.ai/paper/f490837015ae6d717962f68e4d7a9176
3. Fine-grained Angular Contrastive Learning with Coarse Labels
作者:Guy Bukchin, Eli Schwartz, Kate Saenko, Ori Shahar, Rogerio Feris, Raja Giryes, Leonid Karlinsky
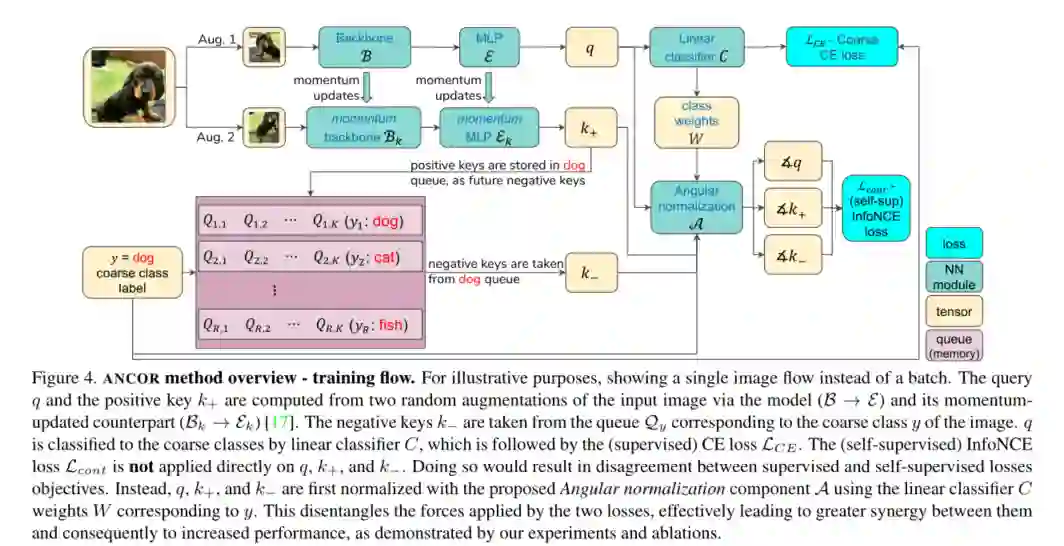
摘要:少样本学习方法会提供经过优化的预训练技术,以便使用一个或几个示例轻松地将模型适应新类别(在训练过程中看不见)。这种对看不见类别的适应性对于许多实际应用尤为重要,在这些实际应用中,预训练的标签空间无法保持固定以有效使用,并且模型需要“专业化”以支持动态的新类别。Coarseto-Fine Few-Shot(C2FS)是一种特别有趣的场景,但被鲜为人知的文献所忽略,其中训练类(例如动物)比目标(测试)类(例如品种)具有“更粗糙的粒度”。C2FS的一个非常实际的示例是目标类是训练类的子类。直观地讲,这是特别具有挑战性的,因为(规律和少样本)监督的预训练往往会学会忽略类内变异性,这对于分离子类至关重要。在本文中,我们介绍了一个新颖的“角度归一化”模块,该模块可以有效地结合监督和自监督的对比预训练来解决提出的C2FS任务,从而在对多个基准和数据集的广泛研究中显示出显着的收益。我们希望这项工作将有助于为有关C2FS分类这一新的,具有挑战性且非常实用的主题的未来研究铺平道路。
网址:
https://www.zhuanzhi.ai/paper/ada7a9bfd94611fbd9059e6809a3c222
4. MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
作者:Shuang Li, Kaixiong Gong, Chi Harold Liu, Yulin Wang, Feng Qiao, Xinjing Cheng
摘要:现实世界中的训练数据通常呈现长尾分布,其中几个多数类的样本数量明显多于其余少数类。这种不平衡会降低被设计用于平衡训练集的典型监督学习算法的性能。在本文中,我们通过使用最近提出的隐式语义数据增强(ISDA)算法来增强少数类,以解决该问题,该算法通过沿着语义有意义的方向平移深层特征来产生多样化的增强样本。重要的是,鉴于ISDA估计了分类条件统计信息以获得语义指导,由于训练数据不足,我们发现在少数群体分类中这样做是无效的。为此,我们提出了一种新颖的方法,可通过元学习自动学习转换后的语义方向。具体来说,训练过程中的扩充策略是动态优化的,旨在最大程度地减少通过平衡更新步骤近似的小的平衡验证集上的损失。在CIFAR-LT-10 / 100,ImageNet-LT和iNaturalist 2017/2018的广泛经验结果验证了我们方法的有效性。

网址:
https://www.zhuanzhi.ai/paper/514c70f2f02b3937431e6f85749cceeb
5. Model-Contrastive Federated Learning
作者:Qinbin Li, Bingsheng He, Dawn Song
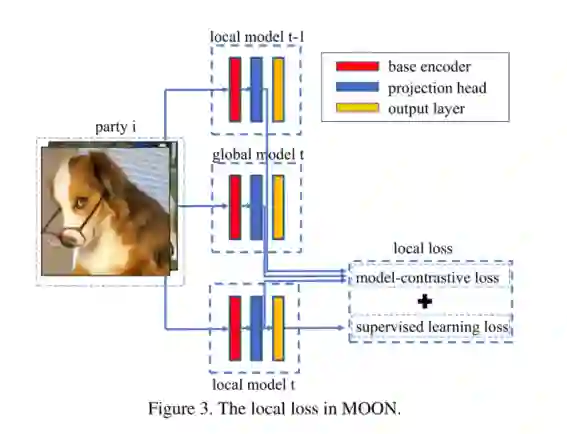
摘要:联邦学习使多方可以协作训练机器学习模型,而无需传达他们的本地数据。联合学习中的一个关键挑战是处理各方之间本地数据分布的异质性。尽管已经提出了许多研究来应对这一挑战,但我们发现它们在具有深度学习模型的图像数据集中无法实现高性能。在本文中,我们提出了MOON:模型对比联合学习。MOON是一种简单有效的联合学习框架。MOON的关键思想是利用模型表示之间的相似性来校正单个方面的本地训练,即在模型级别进行对比学习。我们广泛的实验表明,MOON在各种图像分类任务上明显优于其他最新的联邦学习算法。
网址:
https://www.zhuanzhi.ai/paper/a39ce7b356a570e49f85be1feccef7b9
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2021IC” 就可以获取《5篇顶会CVPR 2021图像分类(Image Classification)相关论文》的pdf下载链接~








