机器学习(ML)的最新进展改变了世界。过去是人类主宰规则,现在是机器储存数据并做出决定。虽然这一变化带来了真正的好处,但它已经实现了大量基于人类的交互自动化,使其易于操作。研究已经确定,机器学习模型非常容易受到对抗性扰动,特别是对其输入的更改,这些更改对人类来说是无法察觉的,但会迫使它们以意想不到的方式作业。在本文中,我们采取了一种相当非正统的方法来研究机器学习安全,并通过计算机安全的角度来研究机器学习的现状。我们发现了大量潜伏在系统安全和机器学习交叉领域的新攻击和问题。接下来,我们描述了文献的现状,强调了我们仍然缺少重要知识的地方,并描述了该领域的几个新的贡献。该领域的一些特征使当前的安全方法变得不太适用,使现代机器学习系统容易受到各种各样的攻击。我们的主要贡献是对机器学习的可用性攻击——针对推理或模型训练延迟的攻击。我们还解释了攻击者如何利用与模型环境的许多其他交集。一个重要的见解是,必须理解、承认机器学习模型的固有局限性,并通过在更大系统中使用组件来补偿控制进行缓解。
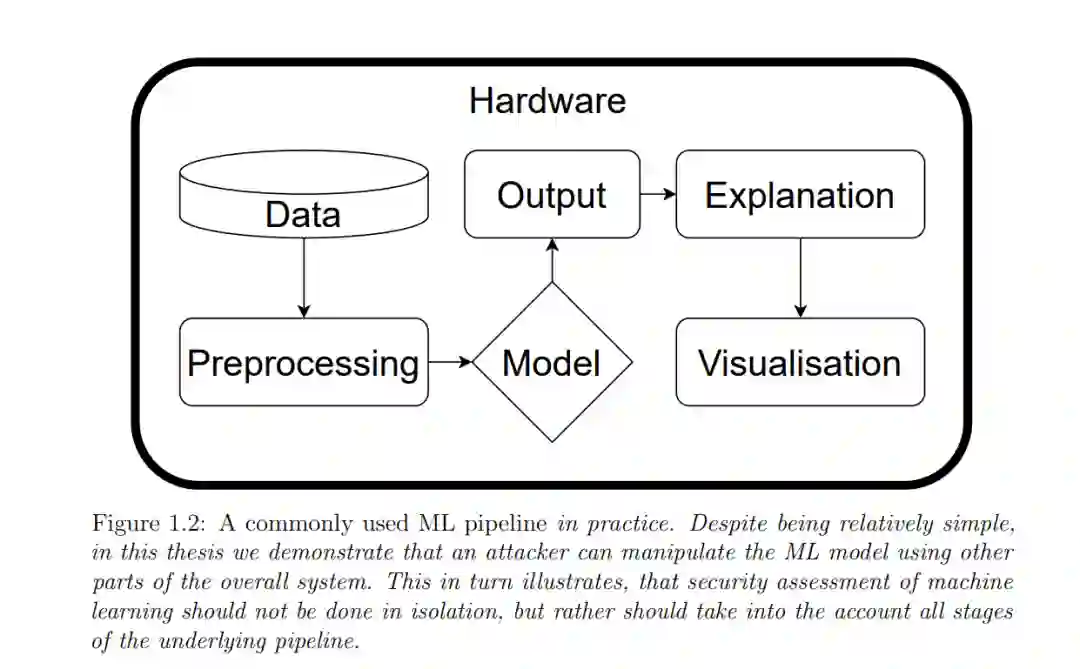
机器学习(ML)彻底改变了现代计算机系统,因此,更多的任务现在是完全自动化和模型驱动的。尽管深度神经网络的性能令人印象深刻,但人们很快发现,底层模型是极其敏感的,攻击者可以找到微小的,有时甚至无法察觉的扰动,以控制底层模型的行为。图1 - 1展示了这种对抗性示例的一个例子——一个输入样本,旨在迫使模型将鸟瞰图视为一辆汽车。(每个像素颜色的微小扰动被放大,使它们在这些图像中可见。)这一发现导致了对抗性机器学习领域的诞生,在那里我们研究如何攻击和防御ML模型。起初,这主要是由对基础数学的研究和构建不太敏感的函数(如对抗性训练)驱动的。然而,令人惊讶的是,这对嵌入模型的大型系统的安全性影响甚微,因为相同的模型仍然容易受到其他攻击者的攻击,也容易受到减少效用的影响。在实践中,使用不那么敏感的近似函数并不一定会提高或降低安全性。攻击者很少受到扰动大小的限制,并且可能更喜欢获得模型的控制权,而不是根据某些学术指标保持攻击不可察觉。
https://www.repository.cam.ac.uk/handle/1810/338197
这种认识导致了一个新领域的创建——机器学习的安全性——在这里,我们不是孤立地观察ML,而是在其环境、依赖项和需求的上下文中分析它。我们在博士期间一直在做的工作对这一文献做出了早期贡献,特别是开创了三种新的攻击和防御类型。