最近的技术进步增强了我们收集和分析丰富多模态数据(如语音、视频和眼动)的能力,以更好地改进学习和训练体验。尽管之前的综述已经关注了多模态处理流程的部分内容(如概念模型和数据融合),但尚未有关于多模态学习和训练环境方法的全面文献综述。本文提供了对这些环境中的研究方法的深入分析,提出了一个涵盖该领域最新方法进展的分类法和框架,并根据五个模态组对多模态领域进行了描述:自然语言、视频、传感器、人本中心和环境日志。我们引入了一种新的数据融合类别——中级融合(mid fusion),以及一种用于优化文献综述的基于图的技术,称为引文图剪枝。我们的分析表明,利用多种模态可以更全面地理解学习者和受训者的行为和结果。即使多模态未能提高预测准确性,它通常也能揭示模式,以情境化和解释单模态数据,揭示单一模态可能遗漏的细微差别。然而,仍需进一步研究以弥合多模态学习和训练研究与基础AI研究之间的差距。
1 引言与背景
1.1 简史
随着技术进步推动学习科学的发展,教育和训练课程的个性化正在不断推进,以满足学习者和受训者的独特需求。这种转变由数据驱动的方法支撑,这些方法已被整合到学习分析领域[61]。学习分析专注于收集和评估学习者和受训者的行为数据——特别是他们在学习和训练任务中的表现[94, 166]。例如,智能辅导系统如Practical Algebra Tutor [78]专注于诊断学生错误,开放式环境如Betty’s Brain [84]自适应地支架学习,而教师反馈工具(如[72, 124])则通过提供学生行为的洞察来帮助教育者改进教学。 学习分析中的一个核心研究问题是,哪些类型的数据对于深入了解学习者的行为和表现,以及在不同情境下促进学生学习和训练提供有意义的支持是必要的?[108, 151]。最初,数据收集和分析的范围受到教育环境中可用技术和计算方法的限制。早期的学习分析主要分析基于计算机环境的日志数据,将学生的行为与其数字交互建立关联,从而为该领域的许多现代理论和方法奠定了基础[71, 108]。 传感器和数据收集技术的进步正将学习分析扩展到传统的基于日志的分析之外[108]。在实际的学习空间中,日志数据不足以捕捉所有学习者的行为、情感状态和协作行为。研究人员现在整合了额外的数据收集设备,如用于捕捉物理互动的视频、用于记录对话的麦克风、用于检测压力水平的生物传感器和用于跟踪注意力的眼动仪[151]。这种丰富的数据收集提供了对学生情感、认知、心理运动和元认知状态的更全面理解,推进了多模态学习分析(MMLA)[12, 13, 158]。经过十年的研究,MMLA已经成熟,并通过期刊专题[52, 96, 109]、会议[60]、编辑书籍[64]和系统综述[4, 22, 39, 50, 100, 130, 158]得到了广泛传播。本文基于这一坚实的基础,重点关注MMLA中的应用研究方法。1.2 相关工作最近的MMLA研究、调查和综述通过不同的视角探索了MMLA的全貌:多模态数据融合[22]、概念模型和分类法[50]、统计和定性评估[121, 131]、虚拟现实[118]、技术和数据工程[26]以及伦理考量[4]。我们的综述集中在多模态学习和训练环境中支持数据收集和分析的应用方法,特别关注使用学习理论收集、融合、分析和解释多模态数据的方法。我们扩展和修改了现有的分类法,以反映MMLA的最新进展。 Di Mitri等人[50]提出了多模态学习分析模型(MLeAM),这是一个概念框架,概述了MMLA中行为、数据、机器学习和反馈之间的关系。该框架提供了一种分类法,并引入了数据可观测性(data observability)的概念,将可量化的输入证据与推断的注释(如情感、认知)区分开来。可观测性线划分了这些领域,对于MMLA研究中从输入到假设的AI介导转化至关重要。Chango等人[22]调查了MMLA中的融合方法,将研究按融合类型和在多模态管道中的应用阶段进行分类。他们提出了三种融合类型:早期融合(特征级整合)、后期融合(决策级整合)和混合融合(两者的结合)。这一分类澄清了融合方法及其在教育数据挖掘中的相关性。 整合了这两项调查的见解后,我们提出了一种聚焦于特征可观测性的分类法,区分感官数据和人类推断的注释。这一改进的分类方案精炼了我们对MMLA中数据融合的理解,并在第2节中展示了一个精细的分类法。
1.3 本综述的范围
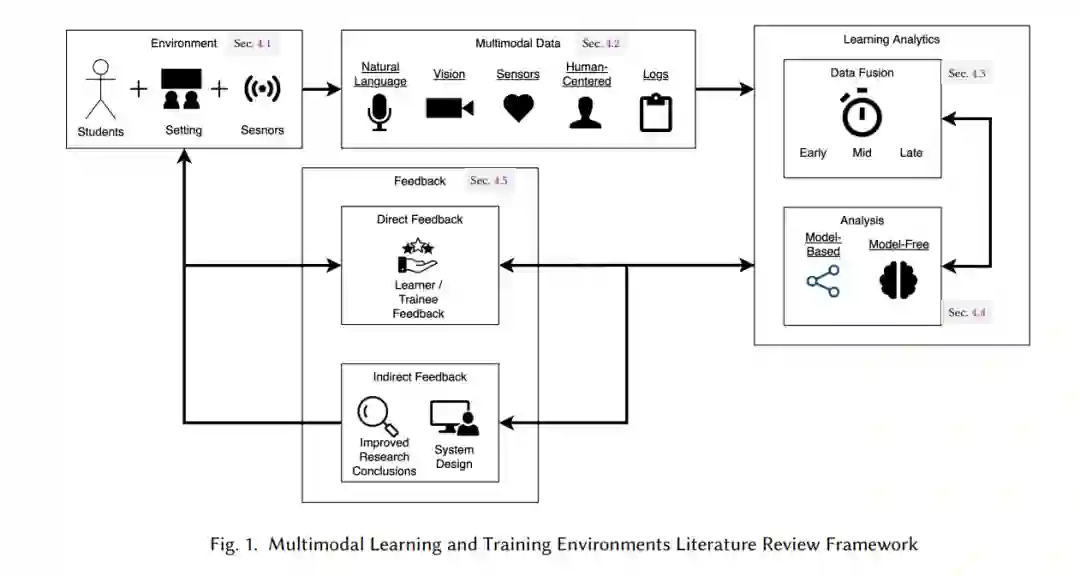
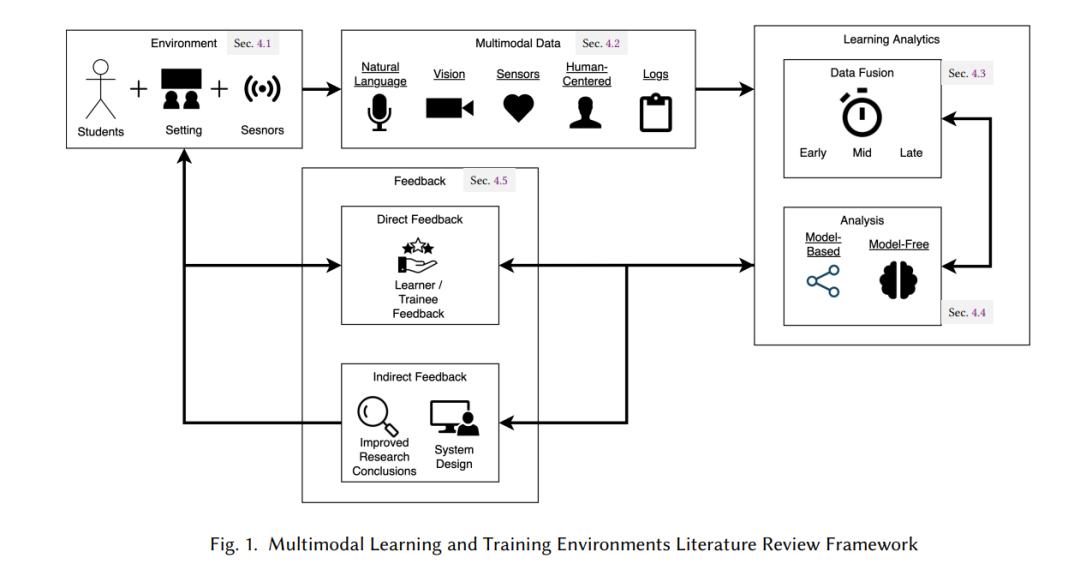
在本文中,我们将数据收集媒介定义为一种独特的原始数据流(如视频、音频、光体积描记(PPG)传感器)。模态是从一个或多个数据流中派生出的独特属性,每个流传达不同的信息,即使来自相同的媒介[108]。模态组是通过归纳编码派生出的传达相似信息的模态的独立集合(见图1)。多模态是多种模态或多种数据流的组合。例如,同一视频数据流可以用来派生情感和姿势模态,情感模态可以从音频和视频流中派生。这两个例子都被认为是多模态的。我们在文中将“论文”和“作品”交替使用,包括会议和期刊之外的出版物(如书籍和书籍章节)。我们的定义旨在描述我们综述的范围,而不是建立“通用”的多模态和多模态分析的定义。 我们的综述包括所有未被排除标准(见附录B.2.2)排除的文献搜索结果中的论文。这包括“顺带”进行的多模态学习和训练分析。例如,一篇专注于多模态创作环境的论文,如果在此过程中进行了多模态学习分析,也会被纳入。我们感兴趣的是多模态分析所使用的方法,而不仅仅是其作为主要研究焦点的研究。我们审查了跨越多种媒介和模态的数据收集和分析的研究,包括完全物理环境(如物理治疗)、混合现实环境(如基于假人的护理模拟)以及在线教育平台(如基于计算机的物理教学)。值得注意的是,由于当前虚拟现实环境在教育环境中的可扩展性挑战[37],我们的综述排除了虚拟现实环境。
1.4 贡献本文对多模态学习和训练环境的方法进行了系统的文献综述,并做出了以下几个新颖的贡献:
- 对多模态学习和训练环境中使用的研究方法、遇到的挑战以及文献中报告的相关结果进行了全面综述。同时,我们还识别了数据收集和分析方法中的研究空白;
- 提出一个反映多模态学习和训练方法最新进展的统一框架和分类法;
- 引入了一种称为中级融合(mid fusion)的额外数据融合分类(即介于早期融合和后期融合之间),用于区分相对于可观测性线的已处理特征;
- 提出一种基于图的语料库缩减程序,称为引文图剪枝(citation graph pruning),该程序允许通过程序化方式修剪文献综述语料库。详细描述见第3.2.1节。