

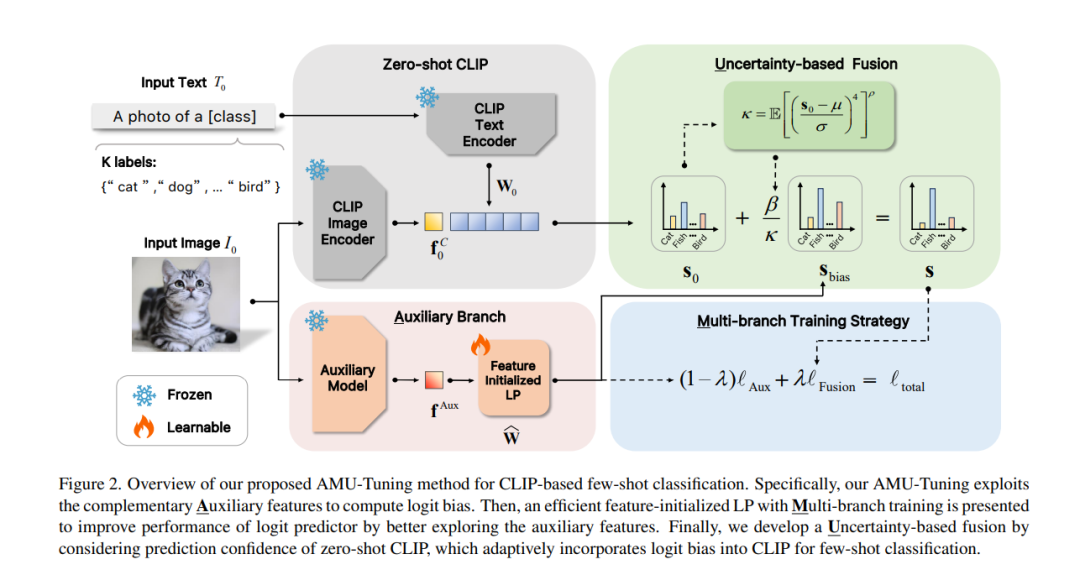
最近,预训练的视觉语言模型(例如,CLIP)在少样本学习中表现出巨大的潜力,并吸引了大量研究兴趣。尽管已经有努力改进CLIP的少样本能力,但现有方法的关键因素的有效性尚未被充分研究,这限制了进一步探索CLIP在少样本学习中的潜力。在本文中,我们首先介绍了一个统一的公式,从对数偏差的角度分析基于CLIP的少样本学习方法,这促使我们学习一个有效的对数偏差,以进一步提高基于CLIP的少样本学习方法的性能。为此,我们拆解了计算对数偏差中涉及的三个关键组成部分(即,对数特征、对数预测器和对数融合),并从实证上分析了它们对少样本分类性能的影响。基于关键组件的分析,本文提出了一种新颖的AMU-Tuning方法,用于学习有效的对数偏差,用于基于CLIP的少样本分类。具体来说,我们的AMU-Tuning通过利用适当的辅助特征来预测对数偏差,这些特征被送入一个高效的多分支训练的特征初始化线性分类器。最后,开发了一种基于不确定性的融合方法,将对数偏差整合到CLIP中进行少样本分类。实验在几个广泛使用的基准测试上进行,结果显示AMU-Tuning在性能上明显优于其竞争对手,同时实现了基于CLIP的少样本学习的最先进性能,无需任何花哨的技巧。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日