
ECCV(European Conference on Computer Vision,欧洲计算机视觉会议)是全球计算机视觉领域的三大顶级会议之一。日前,ECCV 2024 在意大利米兰召开。自动化所多篇论文被本届大会录用,其中2篇论文入选Award Candidate(全球共15篇论文)。


Award Candidate入选名单
1. 整数训练脉冲推理的高精度低能耗目标检测脉冲神经网络****
Integer-Valued Training and Spike-Driven Inference Spiking Neural Network for High-performance and Energy-efficient Object Detection 论文作者:罗昕昊,姚满,侴雨宏,徐波,李国齐 ★ 本研究入选Award Candidate
SNN领域长久存在且难以克服的一个问题是如何在大规模复杂的检测任务上取得具有竞争力的性能。该研究提出的SpikeYOLO极大地弥合SNN和ANN在目标检测任务上的性能差距,主要包括两点贡献: 首先,网络架构方面,该研究将 YOLOv8 的宏观设计和 Meta-SpikeFormer 的微观设计相结合,以避免过于复杂的网络架构设计导致脉冲退化(图1)。第二,脉冲神经元方面,提出一种新型脉冲神经元,采用整数训练和脉冲驱动推理,在有效降低脉冲神经元量化误差的同时保证脉冲驱动计算特性(图2)。实验结果表明,该方法在保证低功耗的同时,能够大幅提升任务性能。在静态数据集COCO上,SpikeYOLO的mAP达到了48.9%,比当前SNN领域SOTA结果高出18.7%。在神经形态数据集Gen1上,SpikeYOLO和同架构的ANN网络相比,mAP提高了2.7%,且能效提升5.7倍。 本研究展现了SNN在超低功耗边缘视觉端的广阔应用前景。目前,研究团队在进行SNN在更多典型边缘视觉场景中应用研究的同时,开展了通用SNN架构的硬件仿真及设计工作。这一工作在算法层面挖掘了SNN在性能/能效上的潜力,证明SNN在未来有能力实现对现有人工神经网络的低功耗替代,对于下一代神经形态算法/芯片的发展有着重要指导意义。
图1. SpikeYOLO架构设计
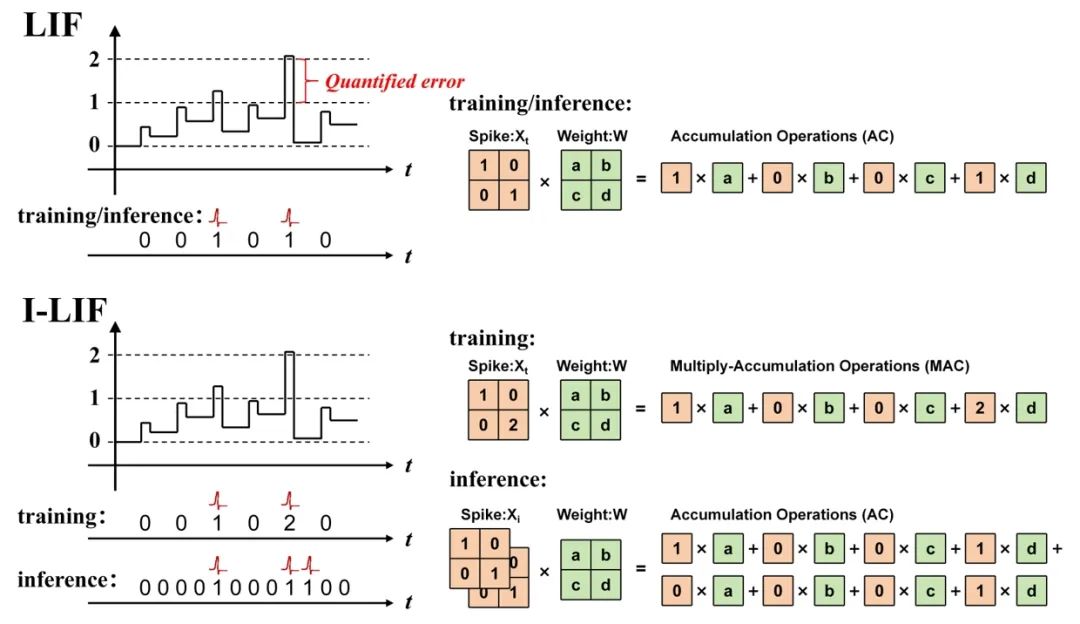
图2. I-LIF神经元
**2. **扩展场景图边界:通过视觉概念对齐和保持实现完全开放词汇的场景图生成
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention 论文作者:陈祖耀,吴锦林,雷震,张兆翔,陈长汶 ★ 本研究入选Award Candidate
我们在这篇文章中探讨了如何应对场景图生成(SGG)任务在开放词汇环境下的挑战。传统的 SGG 模型通常只能够识别预先定义的对象和关系类别,这在实际应用中限制了模型的泛化能力,尤其是在面对未见过的对象和关系时。因此,我们提出了一个名为 OvSGTR 的框架,旨在解决这些问题。 OvSGTR 框架采用端到端的 Transformer 架构,通过视觉-概念对齐技术,使得模型能够识别未见过的对象和关系。我们特别针对关系识别的难题,设计了基于图像-字幕数据的弱监督关系预训练,并通过知识蒸馏技术防止模型在引入新数据时遗忘之前学到的信息。此外,我们提出了四种场景图生成设置,涵盖了从封闭集到完全开放词汇的不同场景。 实验结果验证了我们方法的有效性。在Visual Genome数据集上的测试显示,OvSGTR在处理未见对象和关系类别时表现显著优于现有模型。这项研究不仅扩展了场景图生成的应用边界,还为未来在开放词汇环境下的视觉概念对齐和生成任务提供了新的思路。
图1. 本文提出的四种 SGG 场景设定 (虚线表示训练阶段未见过的目标类或关系类)
图2. 本文所提出的 OvSGTR 框架示意图
**3. **WPS-SAM: 基于视觉基础模型的弱监督部件分割
WPS-SAM: Towards Weakly-Supervised Part Segmentation with Foundation Models
论文作者:吴鑫健,张瑞松,覃杰,马时杰,刘成林 为了克服部件级分割任务中细粒度标注不足的问题,我们提出了一种新颖的弱监督部件分割方法,仅依赖部件的边界框或中心点形式的弱标签,实现高质量的像素级分割,显著减少了对高成本像素级标注的依赖。为了达到这一目的,我们深入挖掘了预训练视觉基础模型 SAM 的零样本泛化能力,设计了一个端到端的弱监督部件分割框架,在训练过程中冻结来自预训练 SAM 的部分参数模块,并引入基于轻量级查询式 Transformer 架构的学生提示模块,进一步增强了模型在弱标签条件下的分割性能。该框架不仅减轻了标注负担,还在更细细粒度的分割任务上取得了领先的性能,展示了该方法在实际应用中的强大潜力。

图1. 训练数据对比示意图:(a) 全监督部件分割任务,(b) 我们提出的弱监督部件分割 (WPS)任务,(c) 弱监督语义分割(WSSS)任务。与全监督方法相比,我们的方法显著减轻了数据标注的负担,同时在更细粒度的任务中表现优于WSSS方法。
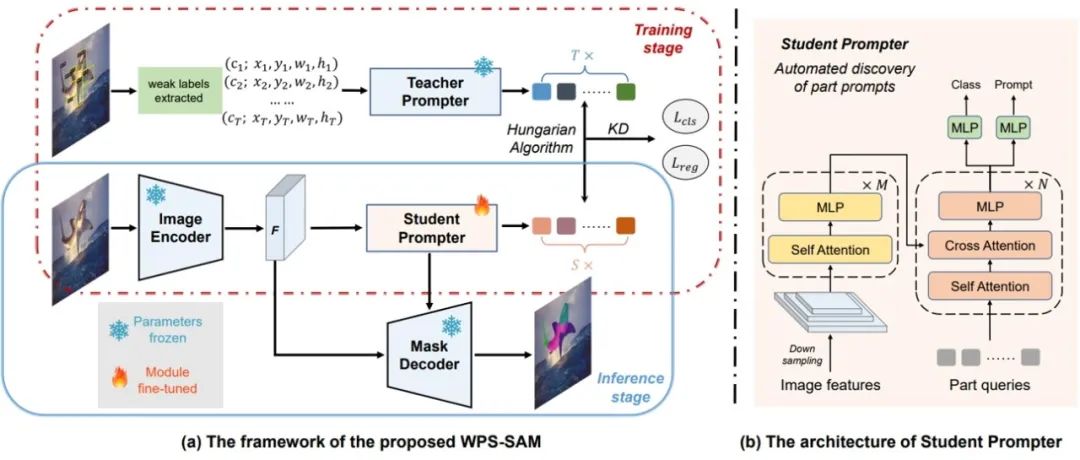
图2. 所提出的WPS-SAM框架概览,该框架在训练过程中仅依赖成本较低的弱标签,实现端到端的部件分割。图中带有冻结参数的模块来自预训练的SAM。此外,所使用的学生提示是基于轻量级的查询式Transformer架构生成的。
**4. **PILoRA:原型引导增量式LoRA的联邦类别增量学习
PILoRA: Prototype Guided Incremental LoRA for Federated Class-Incremental Learning
论文作者:郭海洋,朱飞,刘文卓,张煦尧,刘成林 现有的联邦学习方法已经有效地处理了涉及数据隐私和非独立同分布(non-IID)数据的去中心化学习场景。然而,在实际应用中,每个客户端动态地学习新类别,这要求全局模型能够对所有已见类别进行分类。为了在低通信成本下有效缓解灾难性遗忘和数据异质性,我们提出了一种简单而有效的方法,命名为PILoRA。一方面,我们采用原型学习来获得更好的特征表示,并利用原型与类别特征之间的启发式信息设计了一个原型重标定模块,以解决数据异质性导致的分类器偏差,而无需重新训练分类器。另一方面,我们将增量学习视为学习不同任务向量的过程,并将它们编码到不同的LoRA参数中。因此,我们提出了增量LoRA来缓解灾难性遗忘。在CIFAR100和Tinyimagenet上的实验结果表明,我们的方法显著优于当前最先进的方法。更重要的是,我们的方法在不同设置和数据异质性程度下展现了强大的鲁棒性和优越性。
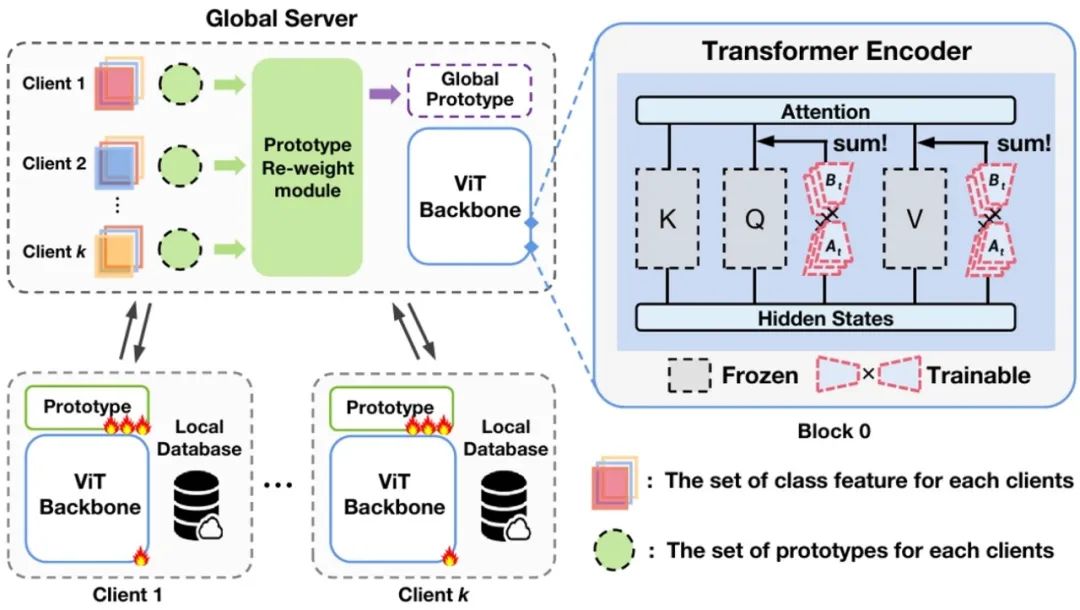
PILORA框架示意图
**5. **生成式端到端自动驾驶
GenAD: Generative End-to-End Autonomous Driving 论文作者:郑文钊,宋瑞琦,国显达,张宸鸣,陈龙 在本文中,探讨了一种新的端到端自动驾驶范式,其关键在于预测给定过去场景时自车辆和周围环境如何演变。本文提出了GenAD,一个生成式框架,将自动驾驶转化为一个生成式建模问题。文章提出了一种以实例为中心的场景标记器,首先将周围场景转换为地图感知的实例标记。然后,作者使用变分自编码器在结构化潜在空间中学习未来轨迹分布,用于轨迹先验建模。进一步采用时间模型来在潜在空间中捕捉代理和自车运动,以生成更有效的未来轨迹。GenAD最终通过在学习的结构化潜在空间中根据实例标记条件采样分布,并使用学习到的时间模型生成未来,同时进行运动预测和规划。在广泛使用的nuScenes基准上的大量实验表明,所提出的GenAD在以视觉为中心的端到端自动驾驶方面取得了SOTA性能,并且具有高效率。
图1. 生成式端到端自动驾驶框架
**6. **通过提示提升无参考图像质量评估性能和泛化性
PromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts 论文作者:陈泽文,覃海纳,王隽,原春锋,李兵,胡卫明,王亮 由于图像质量评估(IQA)任务在不同应用场景中评估需求的多样性,现有的IQA方法在训练后难以直接适应这些多样化的需求。因此,当面对新的需求时,典型的做法是对这些模型在专门为这些需求创建的数据集上进行微调。然而,构建IQA数据集是非常耗时的。在本研究中,我们提出了一种基于提示的IQA方法(PromptIQA),它在训练后可以直接适应新的需求,而无需进行微调。一方面,PromptIQA利用一小段图像-评分对(ISP)作为提示进行有针对性的预测,这显著减少了对数据要求的依赖性。另一方面,PromptIQA在混合数据集上进行训练,并提出了两种数据增强策略来学习多样化的需求,从而使其能够有效地适应新的需求。实验表明,PromptIQA在性能和泛化能力方面均优于现有的最先进方法(SOTA)。
图1. 提出方法(Prompt-Based IQA)和经典IQA框架对比
图2. 网络结构图
**7. **事件感知的视频文本检索
EA-VTR: Event-Aware Video-Text Retrieval
论文作者:马宗扬,张子琦,陈禹昕,祁忠昂,原春锋,李兵,骆颖民,李旭,齐晓娟,单瀛,胡卫明 理解视频中发生的事件内容及其内在的时序逻辑对于视频文本检索十分重要。然而,网络爬取的预训练数据集通常缺乏足够的事件信息,而广泛采用的视频级跨模态对比学习也难以捕捉详细而复杂的视频文本事件对齐。为此,我们从数据和模型两方面入手进行改进。在预训练数据方面,我们提出了事件增强策略来补充缺失的特定事件内容和事件时序转场变化。基于事件增强后的训练数据,我们构建了新的事件感知视频文本检索模型,它可以同时高效地编码帧级和视频级视觉表征,从而实现详细的事件内容和复杂的事件时序跨模态对齐,最终获得对视频事件的全面理解。结果表明,我们的方法不仅在视频文本检索和行为识别任务的多个数据集上优于现有方法,而且在多事件视频文本检索和视频时刻检索任务上表现出卓越的事件内容感知能力,并在时间测试任务上表现出更好的事件时序理解能力。
事件内容增强(a)和事件时序增强(b)用于补充预训练数据集中的事件信息。事件内容学习(c)和事件时间学习(d)从增强后的数据中学习跨模态事件信息对齐。
**8. ****LASS3D: **基于语言辅助和渐进式不可靠点挖掘的半监督3D语义分割
LASS3D: Language-Assisted Semi-Supervised 3D Semantic Segmentation with Progressive Unreliable Data Exploitation 论文作者:李嘉楠,董秋雷 对大规模3D数据集进行精细标注以进行点云分割会耗费大量的时间和人工成本。为了减轻注释负担,研究者们开始探索半监督3D分割方法。然而,现有的方法中仍面临着如下两个问题: 1) 大型语言视觉模型如何应用在半监督3D语义分割任务中。 2) 如何有效利用预测置信度较低的无标签点(不可靠点)。 基于这两个问题,我们提出了一种名为LASS3D的语言辅助半监督3D语义分割方法,该方法建立在常用的MeanTacher框架之上。在LASS3D中,已有的视觉语言模型被用于生成多级字幕,图像被作为连接文本数据和点云的桥梁来构建点云-文本对。在学生分支中,语义感知的自适应融合模块将文本编码的语义信息注入到3D特征中,然后通过知识蒸馏将经文本增强后的3D特征中的语义信息传递给教师分支。此外,针对教师分支中的不可靠点,渐进式开发策略通过负标签学习有效地挖掘不可靠点中包含的信息。在室外和室内的公开数据集上的实验结果表明,LASS3D在大多数情况下都优于九种主流对比方法。
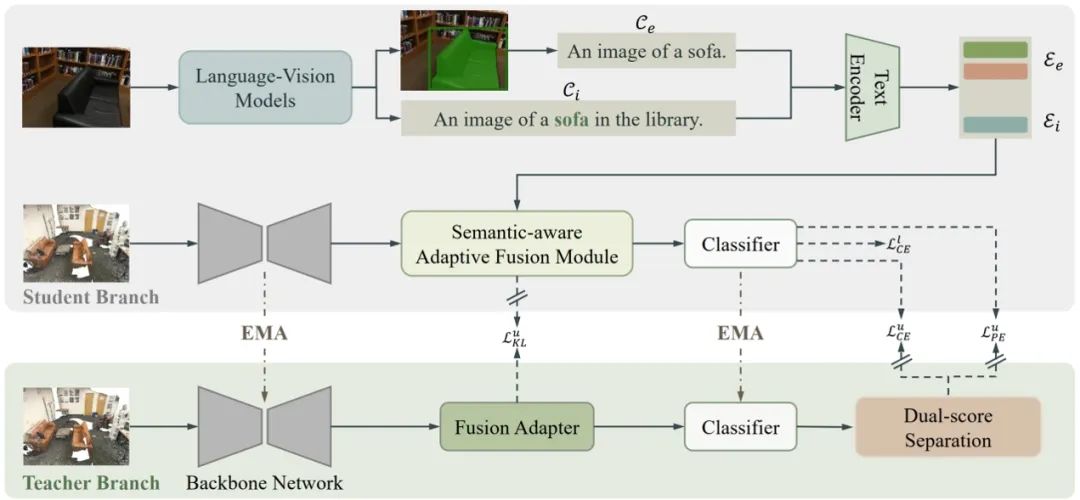
LASS3D结构示意图
**9. **步态识别的新型关系描述符
Free Lunch for Gait Recognition: A Novel Relation Descriptor 论文作者:王继隆,侯赛辉,黄岩,曹春水,刘旭,黄永帧,张天柱,王亮 这篇文章提出了一种新的步态识别表征,名为“关系描述符”。传统的步态识别方法通常依赖于提取个体特征,而忽略了个体之间的“关系”特征。作者提出了一种新颖的方式,通过重新利用分类器权重作为步态锚点,构建出相似度分布,使得步态特征在分类器权重的帮助下更具鲁棒性和泛化能力。然而,直接使用关系描述符会导致维度扩展问题,因为描述符的维度取决于训练集的身份数量。为了解决这一问题,作者提出了最远步态锚点选择算法,选择最具区分性的步态锚点,并采用正交正则化损失增加锚点间的多样性。 实验结果表明,该方法在GREW、Gait3D等五个数据集上超越了现有方法,几乎无需增加额外成本,提升了步态识别的精度和效率。总的来说,该工作为步态识别领域提供了一种新的视角,即通过步态特征之间的关系来表征个体的步态,从而提高识别性能。
图1. 特征提取器的独立特征与关系描述步态的比较。(a)传统的步态识别利用提取的特征进行最终身份识别。(b)通过将步态特征投影到预训练的步态锚点向量上,步态通过与固定语义方向的相似度进行描述。
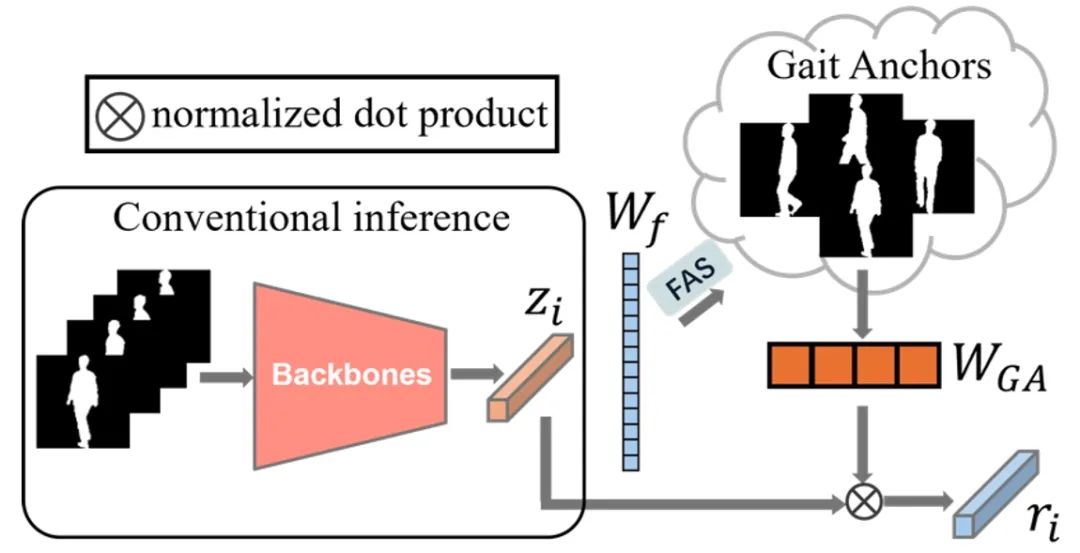
图2. 流程概述。步态锚点从预训练的分类器中选出,步态特征被投影到余弦相似度空间中。
**10. **OneTrack:解明端到端3D追踪器中检测与追踪任务冲突的本质
OneTrack: Demystifying the Conflict Between Detection and Tracking in End-to-End 3D Trackers
论文作者:王启泰,何嘉伟,陈韫韬,张兆翔 本文提出了一种解决视觉3D感知中端到端多目标追踪器在检测任务中性能退化的方法。现有研究趋于在统一模型中同时完成端到端的多目标检测和追踪,但这种共同优化往往导致模型检测能力相对于单纯检测器的大幅下滑。此前,这一问题常被模糊地归因于不同任务需求的目标特征不兼容,而缺乏明确解释。我们发现,检测和追踪任务的冲突源于正样本分配的部分差异,导致两任务优化过程中的分类梯度部分矛盾。 基于此观察,我们通过部分裁剪在两任务中具有相反样本正负性的目标样本的梯度以修复了两任务在优化过程中的冲突。提出的OneTrack方法基于完全统一的检测/追踪物体特征表示,在其检测性能等同于单纯检测器的同时,其多目标追踪性能大幅超越前有工作。
图1. 分类梯度的反向传播。在两任务中样本正负性冲突的训练样本的分类梯度被部分裁剪,如(b),以避免梯度冲突
图2. OneTrack训练管线
**11. **可扩展室内场景的单目占用预测
Monocular Occupancy Prediction for Scalable Indoor Scenes 论文作者:于泓潇,王宇琪,陈韫韬,张兆翔 基于摄像头的3D占用预测最近在户外驾驶场景中引起了越来越多的关注。然而,室内场景的研究仍然相对未被探索。室内场景的核心差异在于场景尺度的复杂性和对象大小的差异。本文提出了一种新的方法,称为ISO,用于使用单目图像预测室内场景占用率。ISO利用预训练深度模型的优点来实现精确的深度预测。此外,我们在ISO中引入了双特征视线投影(D-FLoSP)模块,该模块增强了3D体素特征的学习。为了促进该领域的进一步研究,我们引入了Occ-ScanNet,这是一个用于室内场景的大规模占用基准。其数据集大小是NYUv2数据集的40倍,有助于未来室内场景分析的可扩展研究。在NYUv2和Occ-ScanNet上的实验结果表明,我们的方法达到了最先进的性能。
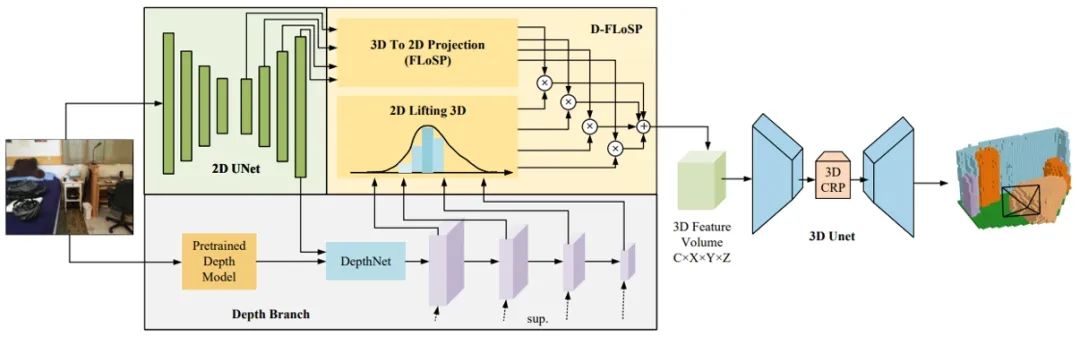
图 1 ISO模型结构图
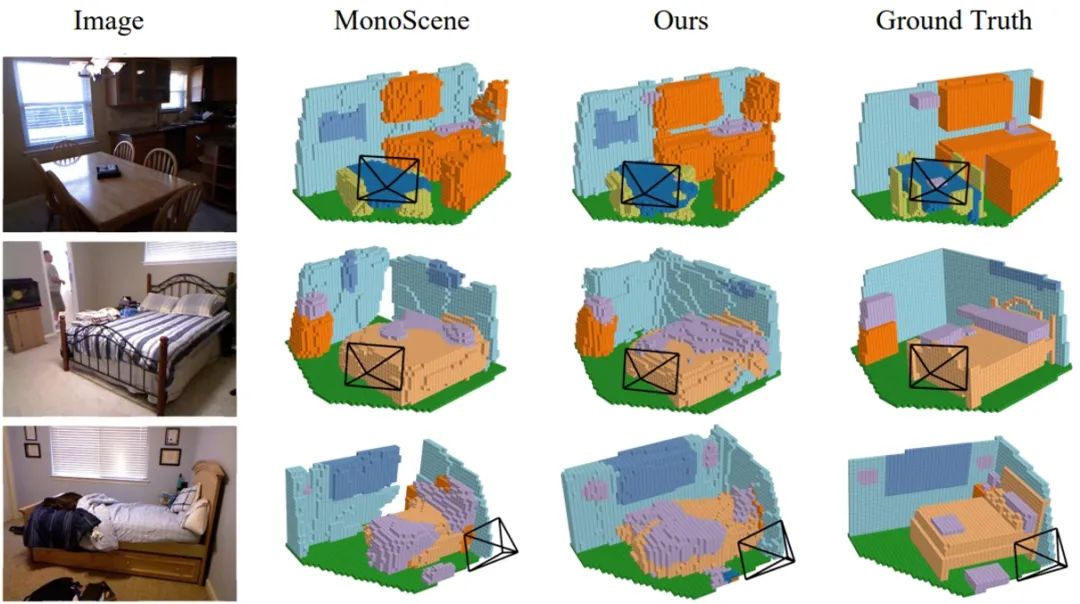
图 2 ISO在NYUv2数据集的定性结果
**12. **CityGaussian: 基于3DGS的大规模场景高质量重建与实时渲染
CityGaussian: Real-time High-quality Large-Scale Scene Rendering with Gaussians
论文作者:刘洋,关赫,罗传琛,范略,王乃岩,彭君然,张兆翔 大规模场景(十万平米到千万平米面积范围的区域)的高质量重建与实时渲染具有重要价值。然而,由于场景覆盖范围很大,场景结构多样且复杂,要进行精准重建难度高、时间长;丰富的细节和信息意味着大体量的表征模型,也给存储与显存开销及实时性带来挑战。为了解决上述问题,我们提出了CityGaussian,在训练和渲染管线两个方面进行了针对性的创新与改进。 **训练管线。**基于分治思想,将高斯基元与数据划分为不同的子块,这些子块被分配到不同的GPU并行训练,并在训练完成后进行综合。这一方式降低单GPU的训练负担同时提升总体效率。 **渲染管线。**3DGS以其优越的实时性著称,但其在大场景上遇到的速度挑战却并未得到充分认知。由于渲染流程中最为耗时的环节涉及对高斯点按深度排序,当总数超过10M时,排序过程将消耗大量时间,致使3DGS失去实时性。为此,我们引入多细节层次技术(Level of Detail, LoD),只加载视锥范围内所需细节层级的高斯点进行渲染。 多个数据集上的测试表明,该方法在各个指标上取得了SOTA的性能结果(图3)。此外,渲染管线也保证了在不同的相机高度下都能获得实时且丝滑的大规模场景游览体验。
图1. CityGaussian训练管线。基于分治思想对大规模场景划分为子块进行并行训练,用全局几何先验引导每个子块的微调,避免不同子块的训练结果相互冲突。同时,基于渲染贡献的数据筛选准则使得我们能以更少的高斯点数取得显著更优的渲染质量。

图2. CityGaussian渲染管线。我们通过不同的压缩率获得不同的细节层次,压缩率越高细节越粗糙,用来表达更远的区域。同时,在渲染时,只有位于视锥范围内的子块才会输入渲染管线。

图3. CityGaussian和现有其它方法的定性对比。
**13. **单样本高保真说话人生成神经辐射场
S3D-NeRF:Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
论文作者:李东泽,赵康,王伟,马一丰,彭勃,张迎亚,董晶 单样本说话人建模范式具有方便快捷,泛化能力强的特点。而基于神经辐射场的说话人建模范式具有生成质量高,姿态可控的特点。本工作结合了两者的优势,提出了一种单样本高保真说话人生成神经辐射场,只需一张源人脸以及一段驱动音频即可以生成一段高质量的说话人视频。为了充分提取源图像的纹理特征和结构特征,本工作使用了特征金字塔结构来建模不同层次由粗到细的视觉信息。为了准确的建模音频到口型的映射,本工作使用了基于交叉注意力的跨模态偏移量预测模块来建模受音频信号影响的人脸区域。进而提升音频信号驱动的说话人生成的真实性。
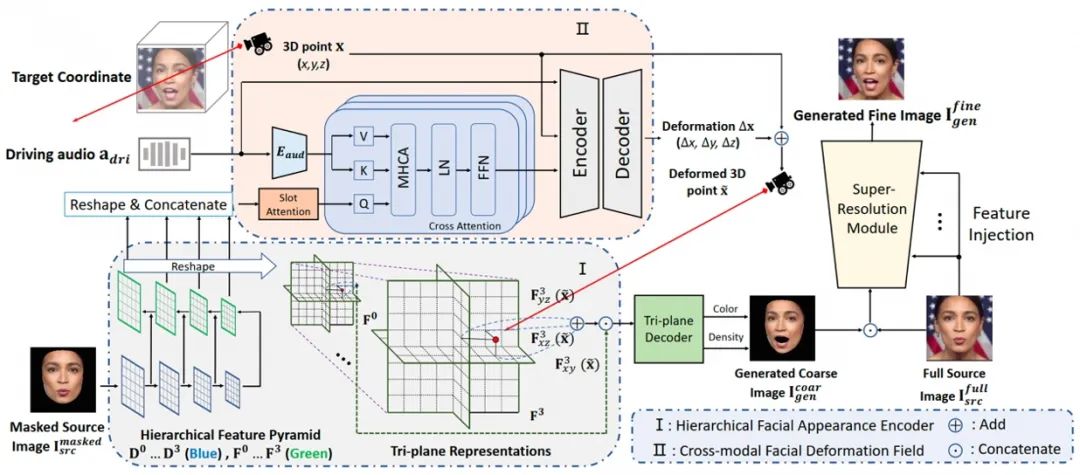
本工作算法流程图
**14. **基于稳定内存回放的异常值感知测试时自适应
Outlier-Aware Test-Time Adaptation with Stable Memory Replay 论文作者:余永灿,生力军,赫然,梁坚 测试时自适应(TTA)旨在解决在测试时只有未标记数据的情况下训练数据和测试数据之间的分布偏移问题。现有的 TTA 方法通常侧重于提高与训练集中的类别相关的测试数据的识别性能。然而,在开放世界推理过程中,不可避免地存在来自未知类别的测试数据实例,通常称为异常值。本文关注在异常值存在的情况下,在推理过程中进行样本识别和异常值拒绝的问题。为了解决这个问题,我们提出了一种基于稳定内存回放的新方法,它对可靠的内存样本而不是有风险的当前批次进行优化。具体而言,我们以类平衡的方式选择低熵和标签一致的样本来动态更新内存,存储更加可靠的样本。此外,我们开发了一种自加权熵最小化策略,在优化过程中为低熵样本分配更高的权重。 大量结果表明,我们的方法在识别和异常值检测性能方面均优于现有的 TTA 方法。
图1. 异常值感知测试时自适应。
图2. 我们的方法。通过两个过滤机制维护可靠内存,并且利用内存样本对模型进行优化。
**15. **Griffon:基于多模态大模型的任意粒度目标定位
Griffon: Spelling out All Object Locations at Any Granularity with Large Language Models 论文作者:詹宇飞,朱优松,陈志扬,杨帆,唐明,王金桥 模拟人类天生具有的基于任意形式和任意粒度文本定位所有物体的能力对于图文大模型来说依然是一个巨大的挑战。目前的图文大模型仅能定位单个且确定存在的物体。这一局限性带来了模型设计上的妥协,必须引入视觉专家模型或特定的结构。为突破这些限制,我们的研究揭示了图文大模型在基础物体感知方面的能力,使其能够准确识别和定位感兴趣的物体。基于这一发现,我们提出了一种全新的语言提示定位数据集,旨在充分释放图文大模型在细粒度物体感知和精准定位方面的能力。更重要的是,我们提出了Griffon,一个完全基于大语言模型的基准模型。Griffon没有引入任何特殊占位符、专家模型或额外的检测模块,而是通过在各种定位相关场景中实现统一表示,并通过精心设计的流程进行端到端训练,从而保持了与常用图文大模型一致的结构。详细的实验表明,Griffon不仅在细粒度的RefCOCO系列和Flickr30K Entities上达到了最好的性能水平,而且在检测任务MSCOCO上接近专家模型Faster RCNN的能力。 
图2. Griffon v1整体框架图
**16. **大语言模型作为副驾驶的粗粒度视觉语言导航
LLM as Copilot for Coarse-grained Vision-and-Language Navigation
论文作者:乔滟媛,刘千一,刘家俊,刘静,吴琦 视觉语言导航 (Vision-and-Language Navigation, VLN) 是指通过人类提供的文本指令,引导智能体在室内环境中完成导航任务。粗粒度视觉语言导航 (Coarse-grained VLN)采用简短且抽象的高层次指令,因其更贴近现实世界的应用场景而逐渐受到广泛关注。然而,这类简洁指令也带来了一个显著挑战,即智能体通常难以充分理解并做出合理决策。尽管已有研究探索了智能体在导航过程中寻求帮助的机制,但通常依赖于预定义的数据集或模拟器,难以灵活适应复杂多变的环境。大语言模型 (Large Language Models, LLMs) 的出现为这一问题提供了全新的解决方案。本文提出了VLN-Copilot框架,其核心特性在于:当智能体在决策过程中遇到困惑时,能够主动检测并发起求助请求,而非被动依赖预设条件。LLM则作为“副驾驶”,根据实时环境辅助导航。本方法通过引入困惑度机制,量化智能体在决策过程中的不确定性,以决定何时请求帮助,并通过LLM提供实时详尽的导航指导。基于两个粗粒度VLN数据集的实验结果验证了该方法的有效性。
VLN-Copilot方法概览:在每个时间步,智能体会对当前视图中的候选点预测概率值,并计算困惑度以决定是否向LLM寻求帮助。当困惑度超过阈值 时,智能体会向LLM求助,并提供环境信息帮助LLM进行感知。LLM返回指导信息以辅助智能体决策。
**17. **CoReS:推理和分割协奏共舞
CoReS: Orchestrating the Dance of Reasoning and Segmentation 论文作者:包笑一,孙思洋,马帅磊,郑可成,郭雨欣,赵国盛,郑赟,王欣刚 推理分割任务要求对复杂的查询进行细致的理解,以准确定位目标区域,因此越来越受到关注。然而,多模态大型语言模型(MLLM)往往难以准确定位复杂推理语境中描述的对象。我们认为,推理分割的过程应该模仿人类视觉搜索的认知阶段,每一步都是逐步细化思维以指向最终目标的过程。因此,我们引入了“推理与分割链(CoReS)”,并发现这种自上而下的视觉层次结构确实提高了视觉搜索过程。具体来说,我们提出了一种双链结构,生成多模态、链状输出,以辅助分割过程。此外,为了引导MLLM的输出进入预期的层次结构,我们将上下文输入作为指导。广泛的实验证明,我们的CoReS具有优越的性能,在ReasonSeg数据集上的表现比当前最先进的方法高出6.5%。

CoReS的整体架构。MLLM的输入包括用户输入的灰度信息和额外的上下文输入(橙色),其中包括与用户查询无关的QA示例。MLLM在推理链的逻辑层面生成输出,其中[LOC]和[SEG]的词嵌入作为不同分割链位置的提示输入,引导分割链逐步生成分割结果。
**18. **基于视觉语义提示的零样本异常分割
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation 论文作者:屈震,陶显,Mukesh Prasad,沈飞,张正涛,宫新一,丁贵广 最近,大规模视觉-语言模型(如CLIP)在零样本异常分割(ZSAS)任务中展示了巨大的潜力。它们通过精心设计的文本提示并利用统一模型直接检测任何未见过产品的异常。然而,现有方法通常假设需要检测的产品类别是已知的,因此设计了产品特定的文本提示,这在数据隐私场景中难以实现。此外,即使是同一类型的产品,由于特定组件和生产过程中差异的存在,也会表现出显著的不同,这给文本提示的设计带来了重大挑战。为此,我们提出了一种基于CLIP的视觉上下文提示模型(VCP-CLIP)用于ZSAS任务。VCP-CLIP的动机是通过视觉上下文提示来激活CLIP的异常语义感知能力。具体而言,我们首先设计了一个Pre-VCP模块,将全局视觉信息嵌入到文本提示中,从而消除了对特定产品提示的需求。然后,我们提出了一个新颖的Post-VCP模块,利用图像的细粒度特征调整文本嵌入。在对10个真实工业异常分割数据集进行的广泛实验中,VCP-CLIP在ZSAS任务中取得了最先进的性能。

VCP-CLIP框架图
**19. **面向工业异常检测与定位的梯度上升引导统一异常合成策略
A Unified Anomaly Synthesis Strategy with Gradient Ascent for Industrial Anomaly Detection and Localization 论文作者:陈麒宇,罗惠元,吕承侃,张正涛 由于通常难以收集足够的缺陷样本,同时像素级注释的成本过高,监督方法在实际工业缺陷检测中存在明显阻碍。因此,在工业检测场景中广泛应用了无监督异常检测技术。近年来,异常合成策略有效地增强了无监督异常检测。然而,现有策略在异常合成的覆盖范围和可控性方面存在局限性,尤其是对与正常区域非常相似的微弱缺陷。本文提出了一种全新的统一框架:全局与局部异常共合成策略(GLASS),旨在基于流形假设来约束低维空间和高维空间的特征分布,从而由局部到全局合成覆盖更为广泛的异常。具体来说,GLASS使用高斯噪声在梯度上升和截断投影的指导下,以可控的方式合成近分布异常。GLASS在MVTec AD等多个工业数据集上实现了最先进的结果,并且在微弱缺陷检测方面表现出色。其高效性在织物缺陷检测实际工业应用中得到了进一步验证。
**20. **一致的三维线段建模
Consistent 3D Line Mapping 论文作者:白旭龙,崔海楠,申抒含 本文从几何视角出发探索了基于图像的轻量化3D线图的构建方法。传统三维线段建模方法以图像线段匹配和摄像机位姿作为输入,通过三维线段假设聚类生成局部最优三维线段,然后构造直线特征轨迹进行点线融合的捆绑调整优化。虽然一些方法通过多种三角化方式可以缓解三维线段生成的退化情况,但是生成了大量的异常值,影响了线段模型构造的鲁棒性,同时它们没有考虑到3D线段在多视图中的一致性。因此,我们提出了三种3D线段的几何一致性约束,包括最优线段假设的多视角一致性,线段特征轨迹中2D线段元素一致性以及3D空间元素几何拓扑一致性。此外,为了进一步提高3D线段模型的轻量化程度,我们在点线模型的基础上提出3D平面模型,使用点、线、面三种混合特征进行场景建模,同时将他们之间的拓扑约束引入到优化过程中。在大量公开的室内外数据上测试表明,我们的方法相比现有的3D线图构造方法在准确性和完整性方面展现出了显著优势。
一致性三维线段建模流程图
**21. **基于房间语义的平面布置图重建Transformer
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
论文作者:刘昱州,朱灵杰,马孝冬,叶翰樵,高翔,郑先伟,申抒含 现有的平面布置图生成方法主要分为两类,第一类是深度学习与几何优化相结合的多阶段方法,这类方法首先对点云投影图进行语义分割,在此基础上通过后处理生成平面布置图,其存在非端到端、过度依赖语义先验、优化速度较慢的问题。第二类是基于Transformer的端到端方法,这类方法存在角点缺失或偏离导致轮廓错误的问题。针对平面布置图生成任务中普遍存在的结构表达与数据缺失问题,本文通过对现有两类方法进行有效结合,利用实例分割网络给出房间先验,并利用Transformer优化坐标;与此同时,为实现对重建的平面布置图轮廓有效监督,本文沿分割轮廓稠密采样监督点坐标,进而提升了平面布置图的生成效果。在多个室内场景结构化建模数据集上的测试表明,本文方法相比现有的平面布置图生成方法在房间区域(Room)、角落位置(Corner)、角落拐角(Angle)三个指标上均取得了优异的性能。
PolyRoom整体网络架构图
**22. **基于一致性建模的少样本缺陷图像生成
Few-shot Defect Image Generation based on Consistency Modeling
论文作者:史庆丰,魏静,沈飞,张正涛 提出了一种新的文本引导扩散方法DefectDiffu,该方法可以对多个产品的产品内背景一致性和产品间缺陷一致性进行建模,并调节一致性扰动方向来控制产品类型和缺陷强度,从而实现多样化的缺陷图像生成。首先,我们利用文本编码器分别为解纠缠集成体系结构的背景、缺陷和融合部分提供一致性提示,从而解纠缠缺陷和正常背景。其次,提出通过一致性方向的两阶段扰动生成缺陷图像的双自由策略,通过调整扰动尺度来控制产品类型和缺陷强度。此外,DefectDiffu可以利用来自缺陷部分的交叉注意映射生成缺陷掩膜注释。最后,为了提高小缺陷和掩模的生成质量,我们提出了自适应注意力增强损失来增加缺陷的注意力。实验结果表明,DefectDiffu在生成质量和多样性方面优于现有的方法,从而有效地提高了下游缺陷性能。此外,缺陷扰动方向可以在不同产品之间转移,实现零缺陷生成,这对解决数据不足的问题非常有利。

图1. 产品间的缺陷一致性和产品内的背景一致性示例
图2. 方法架构图
**23. **基于信息瓶颈理论的持续学习样本偏差纠正
Information Bottleneck Based Data Correction in Continual Learning 论文作者:陈帅,张茗奕,张俊格,黄凯奇 连续学习指模型在开放且动态的环境中不断获取新任务知识的同时,保持对旧任务知识的记忆能力。现有的基于经验回放的连续学习算法在每次对旧任务数据进行采样时,往往会丢弃一部分未被采样的数据,从而导致对旧任务分布估计的偏差。我们提出了一种基于信息瓶颈理论的偏差纠正算法。由于未被采样的数据无法直接用于训练,我们的方法在旧任务学习完成后,通过解耦未采样数据与已采样数据的特征,使模型能够通过挖掘两类数据之间的关联来有效估计未采样数据的代理影响。这一方法有望显著减轻由于数据采样和回放引起的偏差,从而提升连续学习算法的性能,特别是在处理未采样数据方面展现了潜在的优势。我们的方法作为一种通用的设计模块,可以与现有的基于回放的方法结合应用。

**24. **基于分形特征图表征拓扑自相似性以实现管状结构的准确分割
Representing Topological Self-Similarity Using Fractal Feature Maps for Accurate Segmentation of Tubular Structures 论文作者:黄家兴,周岩峰,罗曜儒,刘国乐,郭恒,杨戈 在生物学、医学以及遥感等多个领域中,对细长的管状结构进行精确分割是一项重要任务。管状结构拥有复杂的拓扑与几何特征,为分割任务带来了重大的挑战。这些结构的基本属性之一是它们的拓扑自相似性,这种拓扑自相似性可以通过分形特征如分形维数来量化。在这项研究中,我们通过滑动窗口技术将分形维数扩展到像素级别,将分形特征融入深度学习模型中。滑动窗口计算得到的分形特征图随后作为额外的通道输入到模型中,并在损失函数中作为像素级权重,以利用其拓扑自相似性增强分割性能。此外,我们通过加入边缘解码器和骨架解码器扩展了U-Net架构,提高了分割结果的边界准确性和骨架连续性。我们在五个管状结构数据集上验证了方法的有效性和鲁棒性。此外,将分形特征图与HR-Net等其他主流分割模型结合同样带来分割性能的提升,这表明分形特征图可以作为插件模块与不同模型架构相结合。
图1. 分形特征图计算流程图
图2. 模型结构图
