在机器之心 SOTA!模型启动「虎卷er行动」的第四天,我们解锁第三套「年度回顾」复习资料「Best Papers」,帮助老伙计们回顾在过去的2021年在国际上引起普遍反响的 AI 顶会最佳工作。
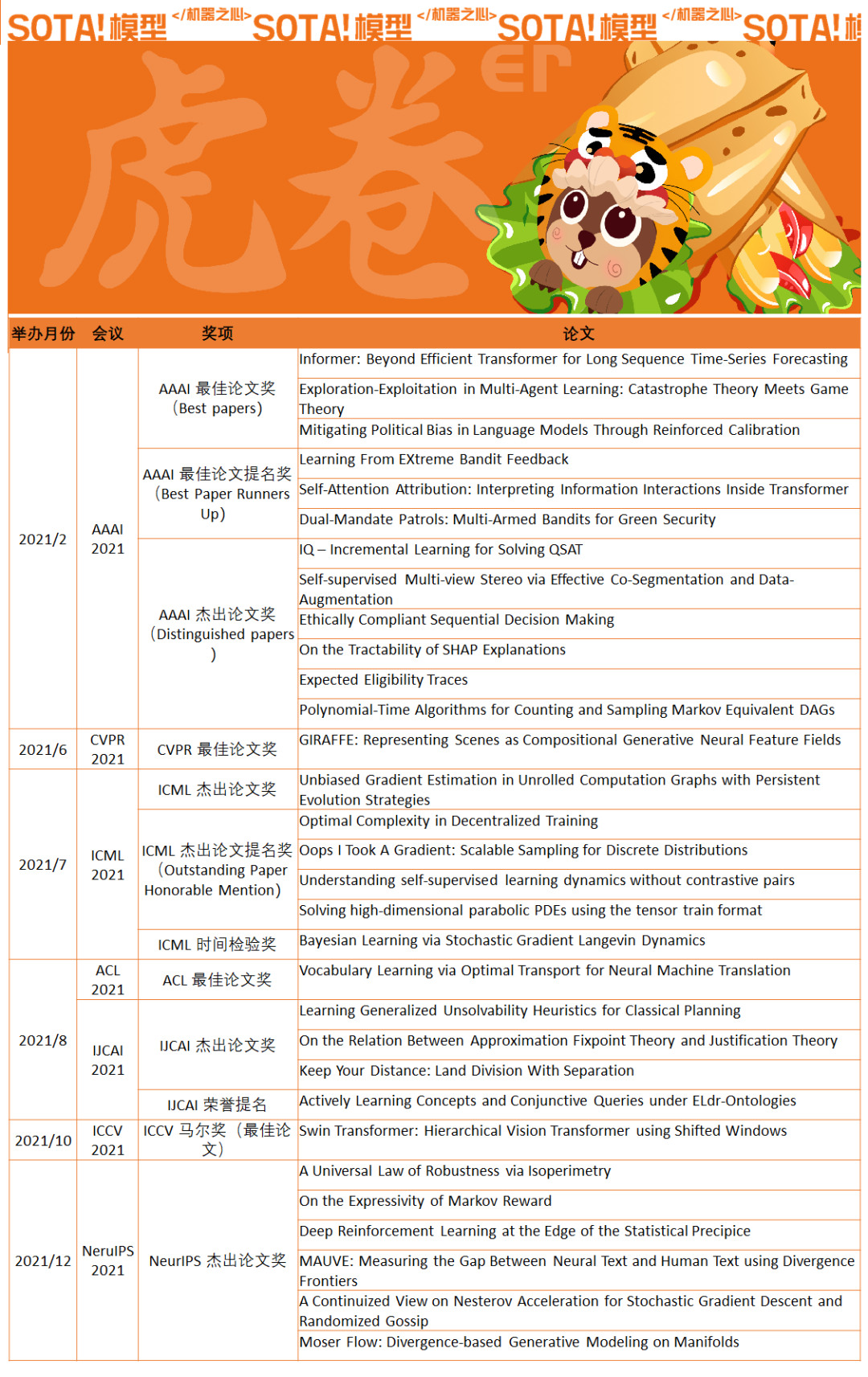
AAAI 2021 最佳论文奖(Best papers)
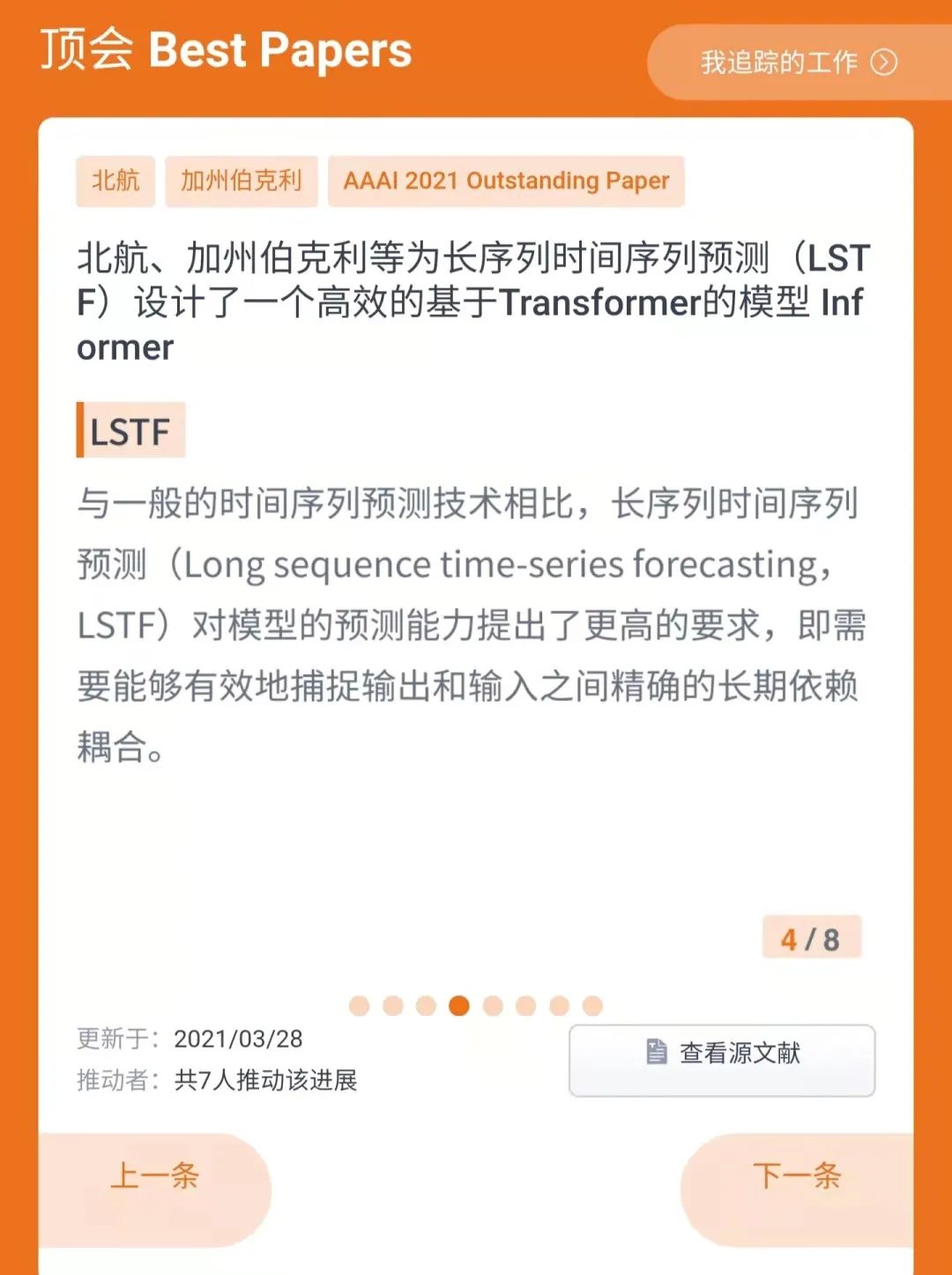
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
TL;DR:
北航、加州伯克利等为长序列时间序列预测(LSTF)设计了一个高效的基于Transformer的模型Informer
长时间序列预测技术可以应用在很多实际场景中,例如电力消耗规划。与一般的时间序列预测技术相比,长序列时间序列预测(Long sequence time-series forecasting,LSTF)对模型的预测能力提出了更高的要求,即需要能够有效地捕捉输出和输入之间精确的长期依赖耦合。
最近的研究表明,Transformer具有提高预测能力的潜力。然而,Transformer存在一些严重问题,使其无法直接应用于LSTF,包括二次时间复杂度、高内存使用率以及编码器-解码器体系结构的固有限制等等。
为了解决这些问题,本文设计了一个高效的基于变压器的适用于LSTF的模型,命名为Informer。
(i) 一种稀疏的自注意机制,在时间复杂度和内存使用方面达到O(Llog L),并且在序列依赖性对齐方面也具有较高性能。
(ii)自注意提取通过将级联层输入减半来突出控制注意,并能够有效地处理超长的输入序列。
(iii)生成式解码器通过一次正向操作而不是一步一步的方式来预测长时间序列,这种处理方式大大提高了长序列预测的推理速度。作者在四个大规模数据集上的大量实验表明,Informer的性能明显优于现有的方法,并为LSTF问题提供了一种新的解决方案。
文献地址:https://arxiv.org/abs/2012.07436
Exploration-Exploitation in Multi-Agent Learning: Catastrophe Theory Meets Game Theory
TL;DR:
新加坡科技设计大学通过 Q 学习的平滑模拟的研究探究「探索 - 利用」在多智能体学习中产生的效果。
该工作获得了AAAI 2021最佳论文奖。该工作探讨了 Exploration-Exploitation 作为一个强有力的工具,在多智能体学习(multi-agent learning,MAL)中的效果,并对相关效果进行了较为全面的分析。
探索 - 利用(exploration-exploitation)是多智能体学习(MAL)中强大而实用的工具,但其效果远未得到理解。为了探索这个目标,这篇论文研究了 Q 学习的平滑模拟。研究者认为其学习模型是学习「探索 - 利用」的最佳模型,并提供了强大的理论依据。
具体而言,该研究证明了平滑的 Q 学习在任意博弈中对于成本模型有 bounded regret,该成本模型能够明确捕获博弈和探索成本之间的平衡,并且始终收敛至量化响应均衡(QRE)集,即有限理性下博弈的标准解概念,适用于具有异构学习智能体的加权潜在博弈。
文献地址:https://arxiv.org/abs/2012.03083
Mitigating Political Bias in Language Models Through Reinforced Calibration
TL;DR:达特茅斯学院、德克萨斯大学奥斯汀分校等提出了一个强化学习(RL)框架来减轻生成文本中的政治偏见。
![]()
当前的大规模语言模型可能会因其所使用的数据而产生政治偏见,在现实环境中部署时可能会造成严重问题。
该工作描述了衡量GPT-2生成中的政治偏见的指标,并提出了一个强化学习(RL)框架来缓解生成文本中的政治偏见。
通过使用单词嵌入或分类器的奖励,RL框架能够在不访问训练数据或重新训练模型的情况下指导 、debiased生成。
根据对政治偏见敏感的三个属性(性别、位置和主题)进行的实证实验结果,本文方法从本文提出的评估指标和参与实验的人类主观评估两个角度出发都减少了偏见,同时保持可读性和语义一致性。
文献地址:https://arxiv.org/abs/2104.14795
AAAI 2021 最佳论文提名奖(Best Paper Runners Up)
Learning From EXtreme Bandit Feedback
TL;DR:加州大学伯克利分校、德克萨斯大学奥斯汀分校的工作。从极端强盗反馈中学习。
摘要:我们研究了在极大动作空间的设置中从强盗反馈中批量学习的问题。从极端强盗反馈中学习在推荐系统中无处不在,其中在一天内对由数百万个选择组成的集合做出数十亿个决策,产生大量观察数据。
在这些大规模的现实世界应用中,尽管由于老虎机反馈和监督标签之间的不匹配而导致显着的偏差,但诸如极限多标签分类 (XMC) 之类的监督学习框架被广泛使用。这种偏差可以通过重要性采样技术来减轻,但这些技术在处理大量动作时会出现不切实际的差异。
在本文中,我们引入了一种选择性重要性采样估计器 (sIS),它在一个明显更有利的偏差方差机制中运行。sIS 估计器是通过对每个实例的一小部分动作(Rao-Blackwellization 的一种形式)对奖励的条件期望进行重要性采样来获得的。
我们在一个新的算法程序中使用这个估计器——称为极端模型的策略优化 (POXM)——从强盗对 XMC 任务的反馈中学习。在 POXM 中,sIS 估计器选择的动作是日志策略的 top-p 动作,其中 p 是根据数据调整的,并且明显小于动作空间的大小。
我们在三个 XMC 数据集上使用监督到强盗的转换来对我们的 POXM 方法与三种竞争方法进行基准测试:BanditNet、以前应用的部分匹配修剪策略和监督学习基线。虽然 BanditNet 有时比日志记录策略略有改进,但我们的实验表明,POXM 在所有基线上都有系统且显着的改进。
文献地址:https://arxiv.org/pdf/2009.12947.pdf
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer
TL; DR:北航及微软研究院的工作。Self-Attention Attribution - 解读transformer内部的信息交互
摘要:基于 Transformer 的模型的巨大成功得益于强大的多头自注意力机制,该机制从输入中学习令牌依赖性并编码上下文信息。先前的工作努力将模型决策归因于具有不同显着性度量的单个输入特征,但他们未能解释这些输入特征如何相互作用以达到预测。
在本文中,我们提出了一种自注意力归因算法来解释 Transformer 内部的信息交互。我们以BERT为例进行广泛的研究。首先,我们提取每一层中最显着的依赖关系来构建一个归因图,它揭示了 Transformer 内部的分层交互。此外,我们应用 selfattention 归因来识别重要的注意力头,而其他注意力头只能在边缘性能下降的情况下进行修剪。
最后,我们表明归因结果可以用作对抗性模式来实施对 BERT 的非针对性攻击。
文献地址:https://arxiv.org/pdf/2004.11207.pdf
Dual-Mandate Patrols: Multi-Armed Bandits for Green Security
TL;DR:哈佛大学、卡内基梅隆大学的工作。双重任务巡逻:绿色安全的多臂强盗
摘要:在绿色安全领域保护野生动物和森林的保护工作受到防御者(即巡逻者)的有限可用性的限制,他们必须巡逻大片区域以防止攻击者(例如偷猎者或非法伐木者)。防御者必须选择在保护区的每个区域花费多少时间,平衡不常访问区域的探索和已知热点的开发。
我们将问题表述为随机多臂老虎机,其中每个动作代表一个巡逻策略,使我们能够保证巡逻策略的收敛速度。然而,幼稚的老虎机方法会为了长期最优而损害短期性能,导致动物被偷猎和森林被毁。
为了加快性能,我们利用奖励函数的平滑性和动作的可分解性。我们展示了 Lipschitz 连续性和分解之间的协同作用,因为每个都有助于另一个的收敛。通过这样做,我们弥合了组合老虎机和 Lipschitz 老虎机之间的差距,提出了一种无悔方法,可以在优化短期性能的同时收紧现有保证。
我们证明了我们的算法 LIZARD 提高了柬埔寨真实世界偷猎数据的性能。
文献地址:https://arxiv.org/pdf/2009.06560.pdf
AAAI 2021 杰出论文奖(Distinguished papers)
IQ – Incremental Learning for Solving QSAT
摘要:事实证明,基于反例指导抽象优化(CEGAR)方法的量化可满足性(QSAT)问题的求解器具有很高的竞争力。
最近,求解器QFUN证明了在这种情况下可以成功利用机器学习。QFUN周期地使用决策树学习器,从QSAT的博弈论公式中学习动作和反动作,从而推断出在CEGAR框架内添加到部分扩展的QSAT公式中的策略。
我们提出了IQ,它是一种新的QSAT求解器,它进一步发展了这一思想。IQ用增量学习(incremental learning)决策列表代替了决策树的批量学习。但是,它的关键创新在于如何利用它们。IQ跟踪这些增量学习器在每个增量上的表现,通过它们在预测已知反向运动方面的成功程度来衡量。这样,就可以在合并策略之前就何时学会了好的策略做出明智的决策。
通过这种方式,它避免了将资源投入到批量学习步骤,而这些步骤事先无法得知学习器是否会产生好的策略。因此,它避免使用资源来推论无效策略,以及避免将无效策略添加到扩展中所带来的问题。通过对IQ进行评估,发现它的性能明显优于QFUN和QuAbS
文献地址:https://www.aaai.org/AAAI21Papers/AAAI-7047.LeeT.pdf
Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation
摘要:最近的研究表明,基于视图合成的自监督方法在多视图立体(MVS)上取得了明显的进展。但是,现有方法依赖于以下假设:不同视图之间的对应点共享相同的颜色,这在实践中可能并不总是正确的。这可能导致不可靠的自监督信号并损害最终的重建性能。
为了解决这个问题,我们提出了一个框架,在语义共分割(co-segmentation)和数据增强的指导下,集成了更可靠的监督。特别是,我们从多视图图像中挖掘出相互语义,以指导语义一致性。并且我们设计了有效的数据增强机制,通过将常规样本的预测视为伪ground truth来确保变换样本的正则化,从而确保变换的鲁棒性。在DTU数据集上的实验
结果表明,我们提出的方法在无监督方法中达到了SOTA,甚至可以与有监督方法相媲美。此外,在Tanks&Temples数据集上的大量实验证明了该方法的有效泛化能力。
文献地址:https://www.aaai.org/AAAI21Papers/AAAI-2549.XuH.pdf
Ethically Compliant Sequential Decision Making
摘要:考虑到自动化系统在影响社会的领域中的加速部署,使自动化系统符合道德规范至关重要。尽管许多道德规范已经在道德哲学中进行了广泛的研究,但是对于构建自动化系统的开发人员来说,实施仍然具有挑战性。
本文提出了一种新颖的方法来构建符合道德规范的自动化系统,该系统在遵循道德框架的同时优化完成任务。首先,我们引入符合道德规范的自动化系统及其属性的定义。接下来,我们为神的命令理论(一种元伦理理论)、表面行为和美德伦理学提供了一系列伦理学框架。
最后,我们在一组自动驾驶模拟以及对规划和机器人专家的用户研究中证明了我们的方法的准确性和可用性。
文献地址:https://www.aaai.org/AAAI21Papers/AAAI-3534.SvegliatoJ.pdf
On the Tractability of SHAP Explanations
摘要:SHAP解释是可解释AI的流行特征分配机制。它们使用博弈论的概念来衡量各个特征对机器学习模型预测的影响。尽管最近在学术界和工业界都引起了很多关注,但尚不清楚是否可以有效地计算常见机器学习模型的SHAP解释。
在本文中,我们建立了在三个重要设置中计算SHAP解释的复杂性。
首先,我们考虑完全因子化(fully-factorized)的数据分布,并表明计算SHAP解释的复杂性与计算模型期望值的复杂性相同。此完全因子化的设置通常用于简化SHAP计算,但是我们的结果表明,对于常用模型(如逻辑回归)而言,该计算可能难以处理。
除了完全因子化的分布外,我们还表明,对于非常简单的设置,计算SHAP解释已经很棘手:在朴素贝叶斯分布上计算朴素分类器的SHAP解释。
最后,我们证明即使在经验分布上计算SHAP也是#P-hard。
文献地址:https://arxiv.org/abs/2009.08634
Expected Eligibility Traces
摘要:如何确定哪些状态和行为对某个结果负责的问题被称为信念分配问题,并且仍然是强化学习和人工智能中的核心研究问题。
资格迹(Eligibility traces)可将信念分配有效地分配给智能体最近经历的状态和操作序列,但不会分配给可能导致当前状态的反事实序列。
在这项工作中,我们引入了预期的资格迹。预期的迹允许通过单次更新来更新可能早于当前状态的状态和操作,即使它们此时未这样做也是如此。我们讨论了预期的迹何时在时序差分学习(temporal-difference learning)中优于经典(瞬时)迹,并且证明有时可以实现显著的改进。
我们提出了一种通过类似于自举的机制在瞬时迹和预期迹之间平滑内插的方法,该方法可确保生成的算法是时序差分函数的严格泛化。最后,我们讨论可能的扩展和与相关概念(例如后继特征)的联系。
文献地址:https://www.aaai.org/AAAI21Papers/AAAI-10339.vanHasseltHP.pdf
Polynomial-Time Algorithms for Counting and Sampling Markov Equivalent DAGs
摘要:马尔可夫等效类的有向无环图的计数和采样是图因果分析中的基本任务。在本文中,我们证明了这些任务可以在多项式时间内完成,从而解决了该领域长期存在的开放性问题。我们的算法有效且易于实施。实验结果表明,该算法明显优于目前的SOTA方法。
文献地址:https://www.aaai.org/AAAI21Papers/AAAI-4640.WienoebstM.pdf
CVPR 2021 最佳论文奖
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
TL;DR:德国马克斯 · 普朗克智能系统研究所等提出 GIRAFFE,可在不影响背景或其他目标的情况下移动图像中的目标。该研究的关键假设是将组合 3D 场景表征结合到生成模型中,以生成更加可控的图像合成
这篇获奖论文工作的一项关键性假设是在生成模型中加入组合式三维场景表征,以使图像合成更加可控。将场景表示为组合生成性神经特征场,使我们能够将一个或多个物体从背景中分离出来,并在不需要额外监督的情况下,从非结构化和未处理的图像集中学习单个物体的形状和外观。
深度生成模型允许以高分辨率进行高真实感图像合成。但对于许多应用程序来说,这还不够:内容创建还需要可控。虽然近来一些工作研究了如何解开数据中变化的潜在因素,但其中大多数是在 2D 场景下运行的,而忽略了现实世界是 3D 的。此外,只有少数研究考虑了场景的构图性质。
通过将场景表征为组合的生成神经特征场,该研究能够从背景中分离出一个或多个目标以及单个目标的形状和外观,同时从非结构化和未定位的图像集合中学习,而无需任何额外的监督。该研究通过将场景表征与神经渲染 pipeline 相结合,得到了快速且逼真的图像合成模型。实验表明,该模型能够分离出单个目标,并允许在场景中平移和旋转它们以及改变相机位姿。
ICML 2021 杰出论文奖
Unbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies
TL;DR:多伦多大学和谷歌大脑提出一种持久进化策略(PES)的方法,实现参数快速更新,内存使用率低,无偏差,并且具有合理的方差特性。这篇获奖论文工作的一项关键性假设是在生成模型中加入组合式三维场景表征,以使图像合成更加可控。
将场景表示为组合生成性神经特征场,使我们能够将一个或多个物体从背景中分离出来,并在不需要额外监督的情况下,从非结构化和未处理的图像集中学习单个物体的形状和外观。深度生成模型允许以高分辨率进行高真实感图像合成。但对于许多应用程序来说,这还不够:内容创建还需要可控。
虽然近来一些工作研究了如何解开数据中变化的潜在因素,但其中大多数是在 2D 场景下运行的,而忽略了现实世界是 3D 的。此外,只有少数研究考虑了场景的构图性质。而该研究的关键假设是将组合 3D 场景表征结合到生成模型中,以生成更加可控的图像合成。
通过将场景表征为组合的生成神经特征场,该研究能够从背景中分离出一个或多个目标以及单个目标的形状和外观,同时从非结构化和未定位的图像集合中学习,而无需任何额外的监督。该研究通过将场景表征与神经渲染 pipeline 相结合,得到了快速且逼真的图像合成模型。实验表明,该模型能够分离出单个目标,并允许在场景中平移和旋转它们以及改变相机位姿。
文献地址:https://arxiv.org/abs/2112.13835
ICML 2021 杰出论文提名奖(Outstanding Paper Honorable Mention)
Optimal Complexity in Decentralized Training
展开计算图应用于许多场景中,包括训练RNN、通过展开优化调整超参数以及训练学习的优化器等等。目前,这种计算图中优化参数的方法存在着高方差梯度、偏差、缓慢更新以及大量内存使用等问题。
作者在这篇获奖论文中引入了一种持久进化策略(Persistent Evolution Strategies,PES)方法,它将计算图划分为一系列阶段展开(truncated unrolls),并在每次展开后执行基于进化策略的更新步骤。PES通过在整个展开序列中累积修正项来消除这些截断的偏差。
作者通过实验证明了PES与其他几种合成任务的梯度估计方法相比的优势,并展示了它在训练学习型优化器和调整超参数方面的适用性。
文献地址:https://icml.cc/virtual/2021/poster/8893
Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
文献地址:https://icml.cc/virtual/2021/poster/9335
Understanding self-supervised learning dynamics without contrastive pairs
文献地址:https://icml.cc/virtual/2021/poster/10403
Solving high-dimensional parabolic PDEs using the tensor train format
文献地址:https://icml.cc/virtual/2021/poster/9927
ICML 2021 时间检验奖
Bayesian Learning via Stochastic Gradient Langevin Dynamics
文献地址:https://www.stats.ox.ac.uk/~teh/research/compstats/WelTeh2011a.pdf
ACL 2021 最佳论文奖
Vocabulary Learning via Optimal Transport for Neural Machine Translation
TL;DR:字节跳动火山翻译团队提出了一种新的词表学习方案 VOLT,在多种翻译任务上取得了SOTA
标记词汇的选择会影响机器翻译的性能。本文旨在找到“什么是好的词汇”,以及是否能够在不进行试训的情况下找到最佳词汇。
为了回答这些问题,作者首先从信息论的角度对词汇的作用进行了另一种理解。基于此,作者将词汇化的探索——寻找大小合适的最佳 token 词典——表述为一个最优传输(Optimal Transport,OT)问题。
作者提出了(VOcabulary Learning approach via optimal Transport,VOLT)——一种简单有效的无需试训的解决方案。实验结果表明,VOLT在不同的场景下,包括WMT-14英德翻译和TED多语言翻译,都优于广泛使用的词汇表。
在英德翻译中,VOLT实现了近70%的词汇量缩减和0.5 BLEU增益。此外,与BPE搜索相比,VOLT将英德翻译的搜索时间从384 个GPU小时减少到30个 GPU小时。
文献地址:https://arxiv.org/abs/2011.12100
IJCAI 2021 杰出论文奖
Learning Generalized Unsolvability Heuristics for Classical Planning
TL;DR:林雪平大学和庞培法布拉大学提出从广义规划的角度来处理经典规划问题,并学习描述整个规划领域不可解性的一阶公式。
对于经典规划问题,近期的研究引入了专门检测不可解决状态(即不能达到目标状态的状态)的技术。
本文从广义规划的角度来处理这个问题,并学习描述整个规划领域不可解性的一阶公式。作者具体将该问题转换为一个自监督分类任务进行分析。本文使用的训练数据是通过对每个域的小实例的详尽探索而自动生成和标记的,候选特征则是由用于定义域的谓词自动计算得到的。
作者研究了三种具有不同性质的学习算法,并将它们与经典的启发式算法进行比较。本文的实验结果表明,本文方法往往能以较高的分类准确度捕捉到重要的不可解决的状态类别。此外,本文的启发式方法的逻辑形式使其易于解释和推理,并可用于表明在某些领域中所学到的特征描述正好捕捉了该领域的所有不可解决的状态。
文献地址:https://www.ijcai.org/proceedings/2021/0574.pdf
On the Relation Between Approximation Fixpoint Theory and Justification Theory
近似不动点理论(Approximation Fixpoint Theory,AFT)和正当性理论(Justification Theory,JT)是统一逻辑形式的两个框架。AFT根据网格算子(lattice operators)的不动点研究语义,JT根据理由(justifications)研究语义,这些理由解释了为什么某些事实在模型中成立或不成立。虽然方法不同,但这些框架的设计目标类似,即研究在非单调逻辑中出现的不同语义。
本文的第一个贡献是提供两个框架之间的正式关联性分析。作者证明了每一个理由框架都会诱导生成一个近似值,并且这种从JT到AFT的映射保留了所有主要语义。
第二个贡献是利用这种对应关系,用一类新的语义即终极语义(ultimate semantics)来扩展JT。在JT中,通过对理由框架进行语法转换可以获得最终语义,本质上是对规则进行某种解析。
文献地址:https://www.ijcai.org/proceedings/2021/0272.pdf
Keep Your Distance: Land Division With Separation
本文的研究内容来自于实际应用程序的需求,目的是使公平划分(fair division)理论更接近于实践。
(1) 每个agent都应该接收一个可用的几何形状的地块;
(2) 不同agent的地块必须在物理上分开。在符合这些要求的情况下,经典的公平概念—按比例划分是不切实际的,因为它可能不可能达到任何乘法近似值。
Budish于2011年提出的序数最大值共享近似法(the ordinal maximin share approximation),对公平相关问题提供了保障。
相比之下,本文证明了当可用形状为正方形、宽矩形或任意轴对齐矩形时,可实现的最大共享保证的上限和下限,并探索了在此设置下找到公平划分的算法和查询复杂性
文献地址:https://arxiv.org/abs/2105.06669
IJCAI 2021 荣誉提名
Actively Learning Concepts and Conjunctive Queries under ELdr-Ontologies
文献地址:https://arxiv.org/pdf/2105.08326.pdf
ICCV 2021 马尔奖(最佳论文)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
TL;DR:微软亚洲研究院提出 Swin Transformer,在 COCO 等数据集上超越 CNN
微软亚洲研究院凭借 Swin Transformer 获得了 ICCV 马尔奖(最佳论文)。这篇论文的作者主要包括中国科学技术大学的刘泽、西安交通大学的林宇桐、微软的曹越和胡瀚等人。
该研究提出了一种新的 Vision Transformer,即 Swin Transformer,它可以作为计算机视觉的通用骨干。
相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:
1、引入 CNN 中常用的层次化构建方式构建分层 Transformer;
2、引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。
文献地址:https://arxiv.org/pdf/2103.14030.pdf
A Universal Law of Robustness via Isoperimetry
TL;DR:微软和斯坦福研究员提出一个理论模型,以解释为什么许多最先进的深度网络需要的参数比顺利拟合训练数据所需的多得多。
本文提出了一个理论模型,以解释为什么许多最先进的深度网络需要的参数比顺利拟合训练数据所需的多得多。
特别是在关于训练分布的某些规则性条件下,一个O(1)-Lipschitz函数插值训练数据低于标签噪声所需的参数数量以nd级数扩展,其中n是训练样本数量,d是样本数据维度。这一结果与传统的结果形成了鲜明的对比,传统的结果指出,一个函数需要n个参数来插值训练数据,而为了顺利插值,这个额外的d系数似乎是必要的。
该理论非常简单,并且与一些关于在MNIST分类中具有鲁棒概括性的模型大小的经验观察一致。这项工作还提供了一个可测试的预测,即为ImageNet分类开发鲁棒模型所需的模型大小。
文献地址:https://arxiv.org/abs/2105.12806
On the Expressivity of Markov Reward
TL;DR:Deepmind、普林斯顿大学和布朗大学的研究员表明可在多项式时间内(polynomial time)确定所需设置是否存在兼容的马尔可夫奖励。
马尔科夫奖励函数是不确定性和强化学习下的顺序决策的主导框架。
本文从系统设计者对特定行为的偏好、对行为的偏好或对状态和行动序列的偏好等方面,对马尔可夫奖励何时足以或不足以使系统设计者指定一项任务进行了阐述。
作者用简单的、说明性的例子证明,存在着一些任务,对于这些任务,不能指定马尔科夫奖励函数来诱导所需的任务和结果。幸运的是,他们还表明有可能在多项式时间内决定对于所需的设置是否存在兼容的马尔科夫奖励,如果存在,也存在一种多项式时间的算法来构建有限决策过程设置中的这种马尔科夫奖励。
这项工作揭示了奖励设计的挑战,并可能开辟未来的研究途径,研究马尔科夫框架何时以及如何足以实现人类利益相关者所期望的绩效。
文献地址:https://arxiv.org/abs/2111.00876
Deep Reinforcement Learning at the Edge of the Statistical Precipice
TL;DR:谷歌大脑和蒙特利尔大学的研究员提出了提高深度强化学习算法比较的严谨性的实用方法。
本文提出了提高深度强化学习算法比较的严谨性的实用方法:具体而言,对新算法的评估应该提供分层的自举置信区间、跨任务和运行的性能概况以及四分位数。
本文强调,在许多任务和多次运行中报告深度强化学习结果的标准方法会使人很难评估一种新的算法是否代表着比过去的方法有一致的、可观的进步,作者通过经验性的实验说明了这一点。所提出的性能总结被设计成可以用每个任务的少量运行来计算,这对许多计算资源有限的研究实验室来说可能是非常重要的。
文献地址:https://arxiv.org/abs/2108.13264
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
TL;DR:华盛顿大学、斯坦福大学和艾伦人工智能研究所联合提出一种用于比较模型生成的文本和人类生成的文本分布的散度测量方法MAUVE
本文提出了MAUVE—一种用于比较模型生成的文本和人类生成的文本分布的散度测量方法。
MAUVE使用被比较的两个文本的量化嵌入的(soft)KL散度度量系列。所提出的MAUVE测量本质上是对连续系列测量的整合,旨在捕捉第一类错误(产生不现实的文本)和第二类错误(没有捕捉到所有可能的人类文本)。
实证实验表明,MAUVE能识别模型生成的文本的已知模式,并与人类的判断有更好的关联。
文献地址:https://arxiv.org/abs/2102.01454
A Continuized View on Nesterov Acceleration for Stochastic Gradient Descent and Randomized Gossip
TL;DR:巴黎科学艺术人文大学、洛桑联邦理工学院提出Nesterov加速梯度方法的「连续」版本
本文描述了Nesterov加速梯度方法的 "连续化 "版本,其中两个独立的矢量变量在连续时间内共同演化—与之前使用微分方程来理解加速的方法很相似—但使用梯度更新是在泊松点过程决定的随机时间发生的。
(1) 享有与Nesterov方法相同的加速收敛性。
(2)本文给出了一个清晰的分析过程,通过利用连续时间进行论证,与之前的加速梯度方法的分析相比更容易理解。
(3)避免了连续时间过程离散化带来的额外误差,这与之前几次利用连续时间过程理解加速方法的尝试形成了鲜明的对比。
文献地址:
https://arxiv.org/abs/2106.07644
Moser Flow: Divergence-based Generative Modeling on Manifolds
TL;DR:魏茨曼科学研究所、Facebook、UCLA共同提出一种在黎曼流形上训练连续归一化流(CNF)生成模型的方法
本文提出了一种在黎曼流形上训练连续归一化流(continuous normalizing flow,CNF)生成模型的方法。
该工作的关键思想是利用Mose 的一个结果,该结果用一类有限的常微分方程(ODEs)来描述CNF的解决方案(Moser称之为流形上的方向保全自变量),该类ODEs享有几何规则性条件,并使用目标密度函数的发散来明确地定义。
本文所提出的Moser Flow方法使用这一解决概念,开发了一种基于参数化目标密度估计器(可以是神经网络)的CNF方法。训练相当于简单地优化密度估计器的散度,从而无需运行ODE求解器。
本文实验表明,与之前的CNF工作相比,CNF训练时间更快,测试性能更优,并且能够对具有非恒定曲率的隐式表面的密度进行建模。此外,这种利用几何规律性条件解决昂贵的反向传播训练的思路可能有更广阔的的应用价值。"
文献地址:https://arxiv.org/abs/2108.08052
在SOTA!
模型推出的「虎卷er行动」中,我们基于2021年度国际AI顶会「Best Papers」、重要SOTA工作,形成总计五十道年度大题。具体分布如下:
答题通道现已开启!扫描下方二维码,进入「机器之心SOTA!模型」服务号,点击菜单栏即可开始答题。