
国际机器学习大会(International Conference on Machine Learning,简称ICML)是机器学习领域的顶级会议。7月21日至27日,ICML 2024在奥地利维也纳正式召开。自动化所多篇研究论文被本届会议录用,部分论文当选Spotlight Paper(仅占总投稿量的3.5%)。本文将对相关成果进行介绍,欢迎交流讨论。
**1. **具有O(L)训练和O(1)推理复杂度的时间可逆脉冲神经网络
High-Performance Temporal Reversible Spiking Neural Networks with O(L) Training Memory and O(1) Inference Cost 论文作者:胡珈魁、姚满、邱雪睿、侴雨宏、蔡宇轩、乔宁、田永鸿、徐波、李国齐 ★ 本研究入选Spotlight Paper
利用多时间步进行仿真的脉冲神经网络(SNNs)训练显存高,且能耗高。当前的方法无法同时解决这一训练和推理难题。该研究提出一种时间可逆架构,通过改变SNNs的前向传播路径,同时应对训练和推理挑战。该研究关闭大部分脉冲神经元的时间动态,并对开启时间动态的脉冲神经元处设计多级时间可逆交互,从而实现O(L)的训练需求。结合时间可逆特性,重新设计SNNs的输入编码和网络组织结构,实现了O(1)推理能耗。实验结果验证了所提出的方法在不损失性能的前提下,能同时大幅度提升训练效率和推理效率。
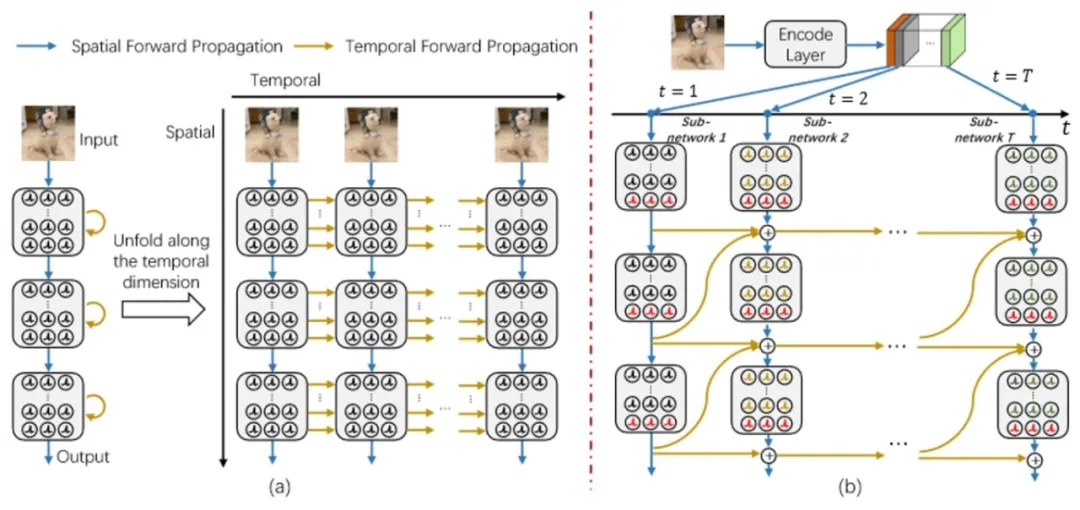
时间可逆脉冲神经网络
**2. **鲁棒的偏好强化学习算法
RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences 论文作者:程杰,熊刚,戴星源,缪青海,吕宜生,王飞跃 ★ 本研究入选****Spotlight Paper
强化学习的成功通常需要选择合适的奖励函数,这一过程费时费力、且依赖于手工设计。而偏好强化学习(PbRL)方法利用人类偏好来学习奖励函数,从而规避了该过程。相较于其他领域而言,控制任务需要更高质量的人类反馈数据;同时,现有算法过度追求反馈利用率,期望用更少的反馈数据来获得更好的控制性能,这进一步恶化了算法在面对噪声数据时的性能。 为此,本文提出了RIME,一种对含有噪声的偏好数据鲁棒的PbRL算法,可从带噪偏好中进行有效的奖励和策略学习。具体而言,基于干净偏好数据的损失上界假设,理论分析了错误样本的KL散度下界,并进一步对RL训练中的分布偏移情况进行不确定性补偿,从而动态地过滤噪声偏好数据。为了抵消因错误筛选而导致的累积误差,本文通过热启动奖励模型,使其在预训练阶段拟合自驱奖励。同时,本文发现奖励模型的热启动还可以弥补 PbRL 从预训练到在线训练切换时产生的性能鸿沟。在机器人操作(Meta-World)和运动(DMControl)任务上的实验表明,RIME 显著增强了PbRL方法的鲁棒性。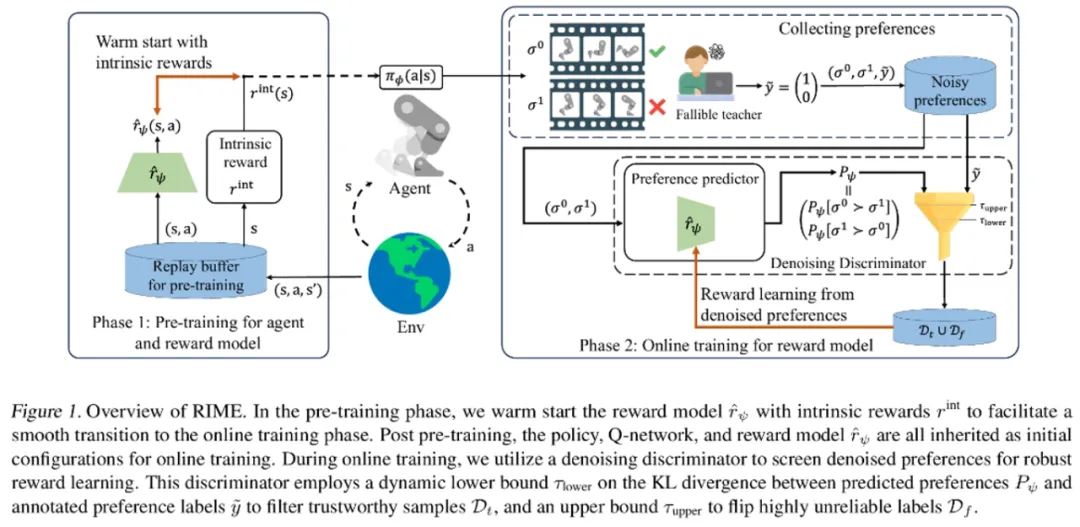
论文链接:https://arxiv.org/abs/2402.17257代码链接:https://github.com/CJReinforce/RIME_ICML2024
**3. **HGCN2SP:基于层次化图卷积网络的两阶段随机规划
HGCN2SP: Hierarchical Graph Convolutional Network for Two-Stage Stochastic Programming
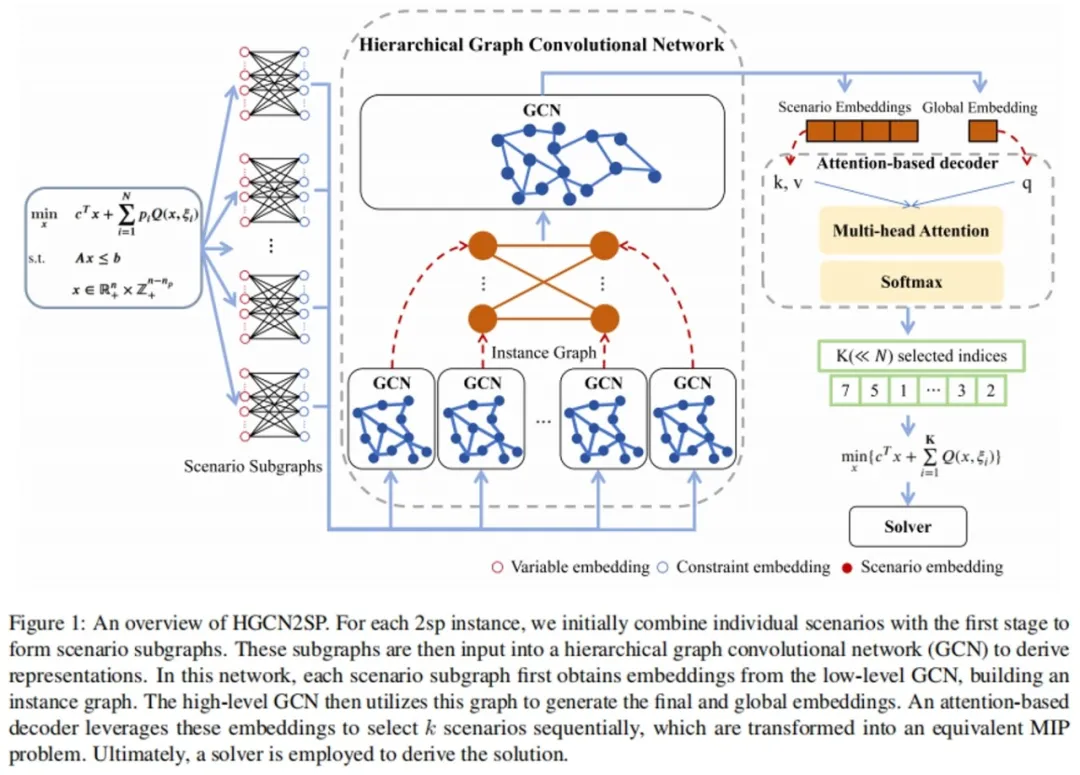
论文作者:吴洋,张一帆,梁振兴,程健 两阶段随机规划(Two-Stage Stochastic Programming, 2SP)是建模和求解不确定性下决策问题的有效方法。在这种情况下,决策者需要在不确定未来环境的情况下,先做出第一阶段的决策,然后根据实际发生的情况(场景)制定具体的第二阶段决策,以最小化总成本或最大化总收益。然而,随着场景数量的增加,问题规模迅速膨胀,导致求解时间显著增加。因此,如何高效求解成为了亟待解决的关键问题。 我们提出了HGCN2SP模型,该模型利用层次化图卷积网络提取场景的表征,采用基于注意力机制的解码器挑选代表性的场景,并结合强化学习(RL)优化其选择,实现了2SP问题的高效求解。在设施选址问题上的实验表明,HGCN2SP能够做出比现有方法更优的决策。在网络设计问题的实验中,HGCN2SP仅用不到一半的时间就取得了相近的决策效果。尤其在大规模实例和大量场景的情况下,HGCN2SP依然保持了强大的泛化能力。
**4. **迈向高效脉冲Transformer:一种用于训练和推理加速的令牌稀疏化框架
Towards Efficient Spiking Transformer: A Token Sparsification Framework for Training and Inference Acceleration 论文作者:诸葛正阳,王培松,姚星廷,程健 当前的脉冲Transformer在具有脉冲神经网络能效优势的同时,还展现出了逼近人工神经网络的卓越性能。然而,虽然能通过神经形态计算实现能耗高效的推理过程,但脉冲Transformer在GPU上的训练过程相比于人工神经网络需要消耗更多时间。 为了解决该问题,我们探索了针对高效脉冲Transformer的令牌稀疏化方案,并发现传统稀疏化方法存在明显的性能下降问题。我们对此问题进行了分析并提出了基于时间步锚定令牌与双对齐的稀疏化方法(STATA),使用更加标准化的准则在时间步维度上识别重要的令牌,并通过双对齐机制促进多个维度上较弱注意力图的学习,进一步保证了令牌稀疏化的准确性。实验结果表明,STATA在脉冲Transformer的训练和推理过程显著优于传统的稀疏化方法。它在保持了一定模型性能的基础上,实现了约1.53倍的训练提速和48%的推理能耗节省,同时它还在多种数据集和架构上具有较好的可迁移性。
**5. **揭示极大卷积核网络鲁棒性的秘密
Revealing the Dark Secrets of Extremely Large Kernel ConvNets On Robustness 论文作者:陈宏昊,张育荣,丰效坤,初祥祥,黄凯奇 部署深度学习模型时,鲁棒性是一个需要考虑的重要方面。许多研究致力于研究视觉转换器(ViTs)的鲁棒性,因为自20世纪20年代初以来,ViTs一直是视觉任务的主流骨干选择。最近,一些大卷积核网络以令人印象深刻的性能和效率卷土重来。然而,目前尚不清楚大卷积核网络是否具有强鲁棒性及影响其鲁棒性的因素。 在本文中,我们首先在六个不同的鲁棒性基准数据集上对大核卷积的鲁棒性及其与典型的小核卷积和ViTs的差异进行了全面评估。然后,为了分析其强大鲁棒性背后的潜在因素,我们从定量和定性的角度设计了九组实验,以揭示大核卷积网络与传统卷积网络完全不同的有趣特性。我们的实验首次证明,纯卷积网络可以实现与ViTs相当甚至优于ViTs的优异鲁棒性。我们对遮挡不变性、核注意力模式和频率特性的分析为鲁棒性的来源提供了新的见解。
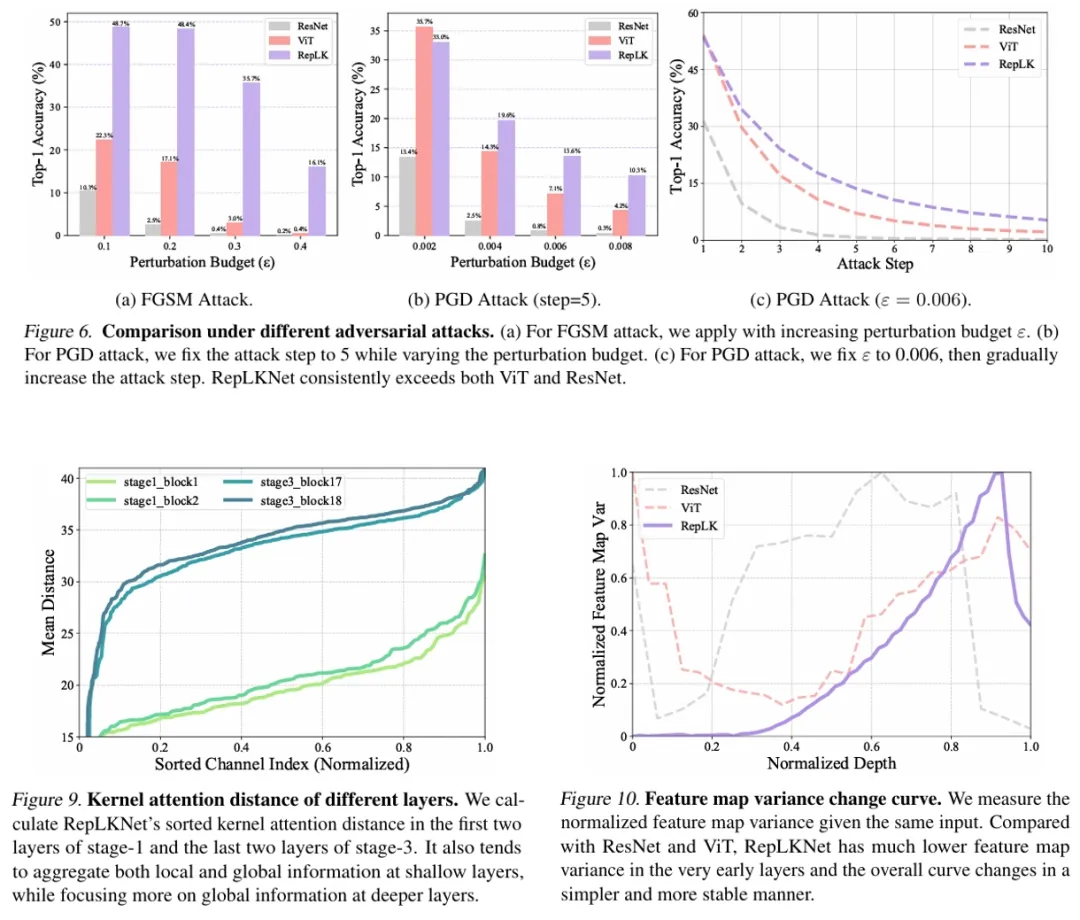
**6. **Libra:基于解耦视觉系统的多模态大语言模型
Libra: Building Decoupled Vision System on Large Language Models
论文作者:许逸凡,杨小汕,宋亚光,徐常胜 本工作提出了一个基于解耦视觉系统的多模态大语言模型Libra。解耦视觉系统将视觉建模解耦成内部模态建模和跨模态交互两部分,使得模型能够在保留视觉独有信息的同时进行有效的跨模态理解。Libra对于视觉和语言模态采用了统一的自回归建模。具体来说,本工作在已有大语言模型基础上,嵌入了路由视觉专家,在模型的注意力计算过程中将视觉和语言流进行路由,从而使得模型在模态内部建模和跨模态交互的计算情境下呈现出不同的注意力计算模式。实验表明Libra的这种结构设计能够在仅用5千万图文对的训练数据量下取得和现有多模态大模型相匹敌的性能。因此,本工作为未来多模态基础模型提供了一个新的设计角度。
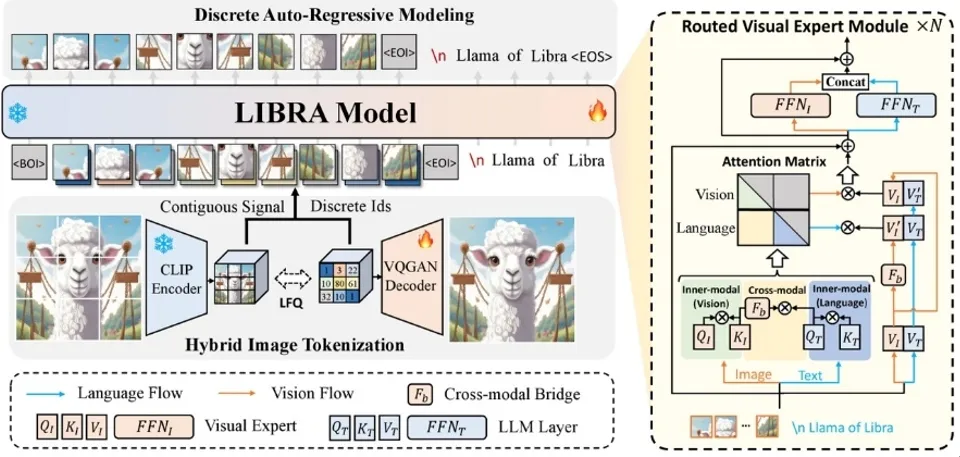
**7. **基于快-慢测试时自适应的在线视觉-语言导航方法
Fast-Slow Test-time Adaptation for Online Vision-and-Language Navigation
论文作者:高君宇,姚暄,徐常胜 视觉-语言导航作为实现具身智能的关键研究方向,专注于探索智能体如何准确理解自然语言指令并导航至目标位置。在实际中,智能体通常需要以在线的方式执行视觉-语言导航任务,即完成跨样本的在线指令执行和单样本内的多步动作决策。由于仅依赖预训练和固定的导航模型难以满足多样化的测试环境,这促使我们探索如何利用未标注的测试样本来实现有效的在线模型适应。然而,过于频繁的模型更新可能导致模型参数发生显著变化,而偶尔的更新又可能使模型难以适应动态变化的环境。 为此,本文提出了一种新的快-慢测试时自适应方法(FSTTA),该方法在统一框架下对模型梯度和参数进行联合的分解与累积分析,以应对在线视觉语言导航任务的挑战。通过大量实验验证,本文提出的方法在四个流行的基准测试中均取得了显著的性能提升。
模型的整体架构
论文链接: https://icml.cc/virtual/2024/poster/33723 代码链接: https://github.com/Feliciaxyao/ICML2024-FSTTA
**8. **Transformer不同子层的差异化结构压缩
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models 论文作者:李广焱,唐永强,张文生 Transformer的结构化压缩往往采用单一的压缩方法,从而忽略了Transformer中不同子层之间的结构特性。为了解决该问题,本文设计了一种新颖的结构化压缩方法 LoRAP,它有机地结合了低秩矩阵近似和结构化剪枝。这项研究中得出了一个重要观察:多头自注意力(MHA)子层显示出明显的低秩结构,而前馈网络(FFN)子层则没有。基于这一观察,对于MHA子层,本文提出了一种输入激活加权奇异值分解方法,并根据矩阵低秩属性的差异分配不同的参数量。对于FFN子层,本文提出了一种梯度无关的结构化通道剪枝方法。在零样本困惑度和零样本任务分类的广泛评估中,本文的方法在多个压缩比下均优于之前的结构化压缩方法。
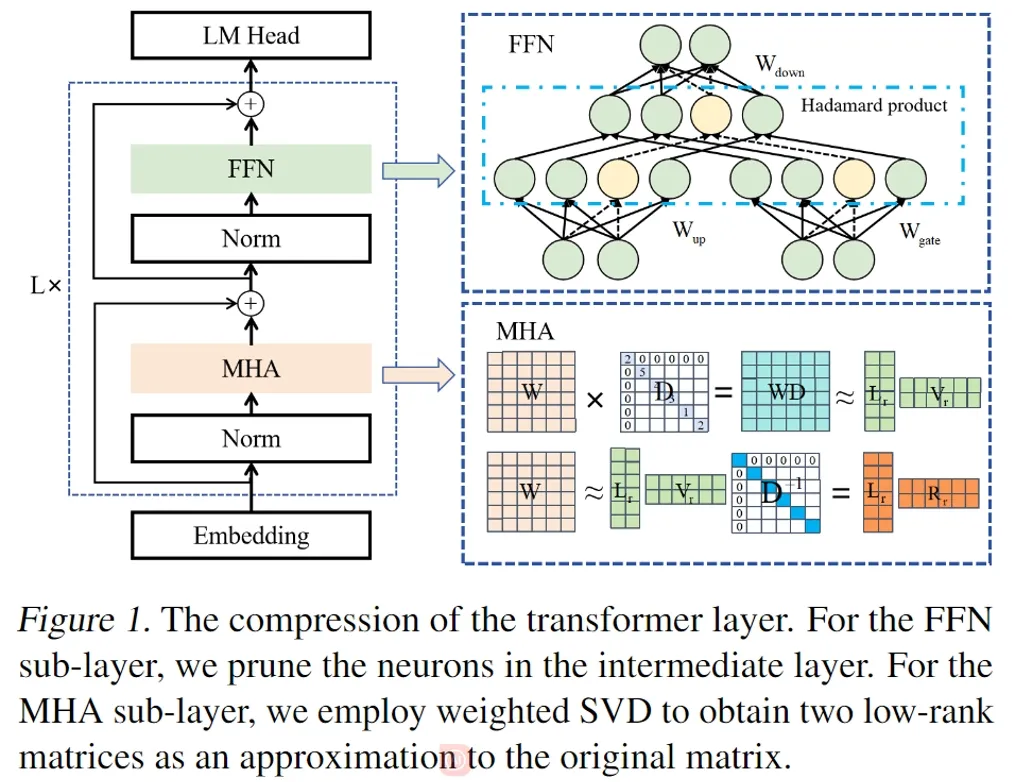
论文链接: https://arxiv.org/abs/2404.09695
**9. **连点成线:面向黑盒视觉语言模型的协作式微调
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models 论文作者:王政博、梁坚、赫然、王子磊、谭铁牛 随着预训练视觉语言模型的不断发展,它的通用性和泛化性得到广泛认可,人们投入了大量精力对其进行微调以适应下游任务。尽管如此,这些方法通常需要访问模型的结构和参数,这可能会侵犯模型所有者的权益。因此,为了保护其模型所有权,模型拥有者往往选择将其模型以黑盒形式提供,这给模型微调带来了挑战。 本文提出了一种名为协作式微调(CraFT)的新方法,用于在黑盒条件下微调视觉语言模型以适应各种下游任务。该方法仅依赖于模型的输入提示和输出预测结果。CraFT设计两个关键模块:一个提示生成模块,用于自动学习最有效的文本提示;一个预测优化模块,通过增强残差来优化输出预测。此外,我们引入了一种辅助的预测一致性损失,以促进这些模块之间的一致优化。所有这些模块通过一种新颖的协作训练算法进行优化。 通过大量的实验验证,无需模型的结构、参数及梯度,CraFT能够在保持微调效率的前提下大幅提升黑盒模型在下游任务的性能。 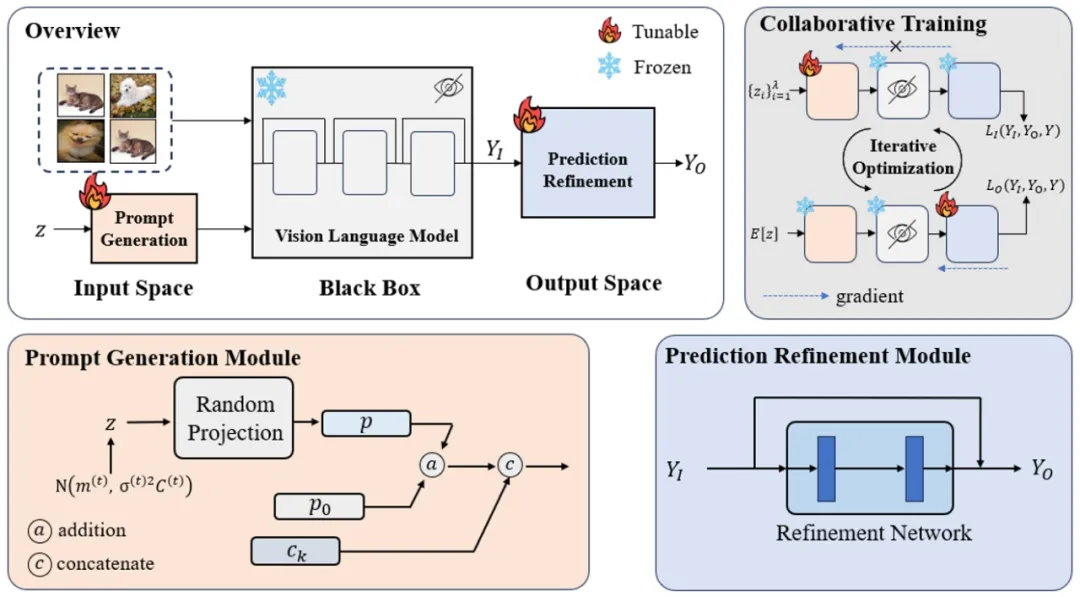
**10. **词元级别直接偏好优化
Token-level Direct Preference Optimization 论文作者:曾勇程,刘国庆,马纬彧,杨宁,张海峰,汪军 在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。直接偏好优化方法(DPO)通过数学推理得到奖励函数与最优策略之间的直接映射,消除了奖励模型的训练过程,直接在偏好数据上优化策略模型,实现了从「反馈到策略」的直观飞跃。然而,DPO主要关注在逆KL散度约束下的策略优化。由于逆KL散度的mode-seeking特性,DPO在提升对齐性能方面表现出色,但是这一特性也倾向于在生成过程中减少多样性,可能限制模型的能力。另一方面,尽管DPO从句子级的角度控制KL散度,模型的生成过程本质上是逐个token进行的。从句子级控制KL散度直观上表明DPO在细粒度控制上存在限制,对KL散度的调节能力较弱,可能是DPO训练过程中LLM的生成多样性迅速下降的关键因素之一。 为了应对模型生成多样性显著下降的问题,我们的方法TDPO从token-level的角度重新定义了整个对齐流程的目标函数,并通过将Bradley-Terry模型转换为优势函数的形式,使得整个对齐流程能最终从 Token-level层面进行分析和优化。相比于 DPO而言,TDPO的主要贡献如下: * Token-level的建模方式:TDPO从Token-level的角度对问题进行了建模,对RLHF进行了更精细的分析; * 细粒度KL散度约束:在每个token处从理论上引入了前向 KL散度约束,使方法能够更好地约束模型优化; * 性能优势明显:相比于DPO而言,TDPO能够实现更好的对齐性能和生成多样性的帕累托前沿。

图 1:DPO和TDPO损失函数对比
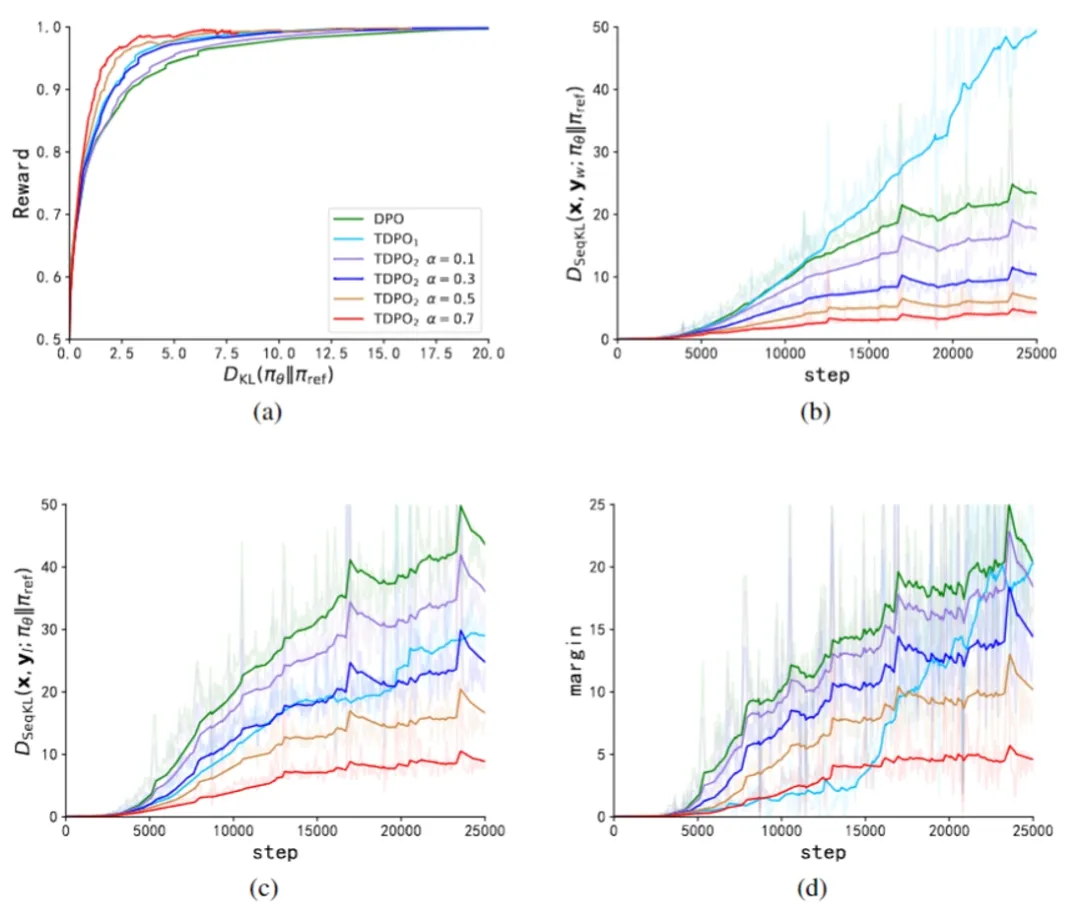
图 2:IMDb数据集上的实验。图3(a)表示相对于参考模型的预期回报和KL散度的帕累托前沿。我们针对参数α实施了DPO、TDPO1以及TDPO2的不同版本。就帕累托前沿而言,TDPO1和TDPO2均优于DPO,其中TDPO2相对于TDPO1进一步提高了性能。这证明了我们的分析和修改的有效性。图3(b)和图3(c)分别展示了在训练步骤中,偏好和不偏好响应子集的序列KL散度的演变情况。图3(d)展示了在整个训练过程中,不偏好响应子集的序列KL散度与偏好响应子集的序列KL散度之间的差异。与TDPO1和DPO算法相比,TDPO2在KL散度的调节方面表现出了优越性。
论文地址: https://arxiv.org/abs/2404.11999 代码地址: https://github.com/Vance0124/Token-level-Direct-Preference-Optimization
**11. **基于扰动过程一致性的随机微分方程的策略梯度稳定算法
Stabilizing Policy Gradients for Stochastic Differential Equations via Consistency with Perturbation Process
论文作者:周相鑫,王亮,周钇驰 为了生成具有目标性质的样本,本研究专注于优化参数化的随机微分方程(SDEs)的深度神经网络生成模型,这是具有高表达性的先进生成模型。策略梯度是强化学习中的领先算法。然而,当将策略梯度应用于SDEs时,由于策略梯度是基于有限的轨迹集估计的,它可能是不明确的,并且在数据稀疏区域的策略行为可能是不受控制的。这一挑战妨碍了策略梯度的稳定性,并对样本复杂性产生了负面影响。 为了解决这些问题,本研究提出将SDE约束为与其相关的扰动过程一致。由于扰动过程覆盖了整个空间并且易于采样,本研究可以缓解上述问题。研究框架提供了一种通用方法,允许灵活选择策略梯度方法,以有效且高效地训练SDEs。本研究在基于结构的药物设计任务上评估了算法,并优化了生成的配体分子的结合亲和力。本研究提出的方法在CrossDocked2020数据集上实现了最佳Vina得分。 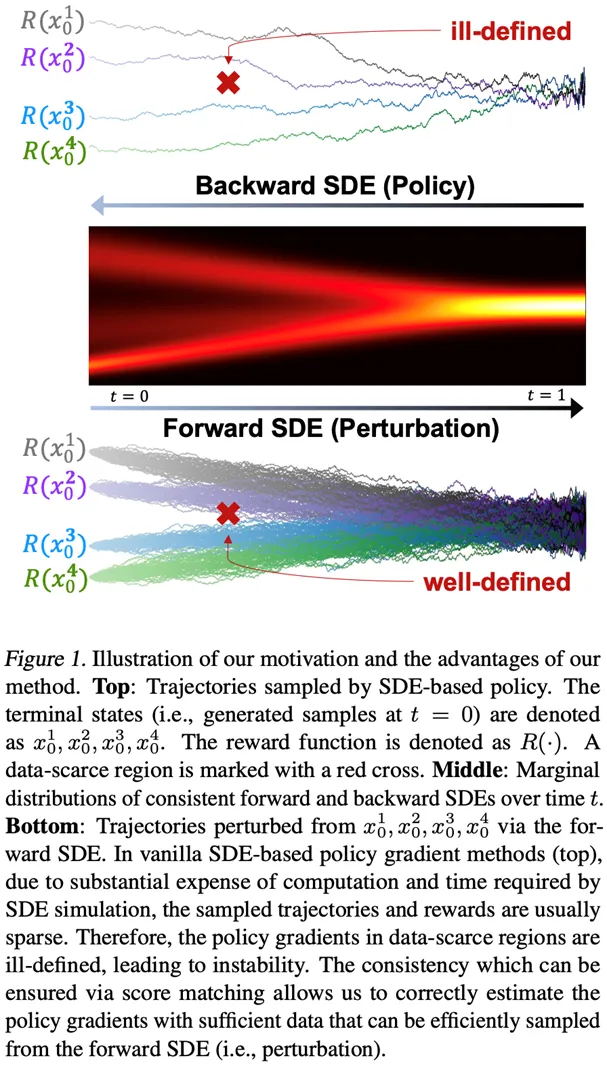
**12. **多智能体系统中的序列异步动作协调:斯塔克尔伯格决策Transformer方法
Sequential Asynchronous Action Coordination in Multi-Agent Systems: A Stackelberg Decision Transformer Approach
论文作者:张斌,毛航宇,李丽娟,徐志伟,李大鹏,赵瑞,范国梁 在多智能体系统中,智能体不仅需要最大化自身奖励,还需与其他智能体动态协调,以实现最佳联合策略。现有的MARL方法大多假设智能体之间的同步动作,限制了其在复杂场景中的应用。 这篇文章探讨了多智能体系统中的异步动作协调问题。作者提出了一种新的方法—Stackelberg Decision Transformer(STEER),旨在通过结合斯塔克尔伯格博弈的层次决策结构和自回归序列模型的建模能力,来提高多智能体强化学习方法的可扩展性。STEER引入了双Transformer架构,其中内部Transformer块能够实现博弈抽象,有效处理不同环境下的状态配置,外部Transformer块则促进了每个智能体策略函数和价值函数的自回归拟合。这种架构还能够并行更新所有智能体的策略,大幅降低了之前基于斯塔克尔伯格博弈博弈的强化学习方法的计算成本。此外,文章还提出了知识蒸馏方案来实现其在分散式执行系统中的部署。

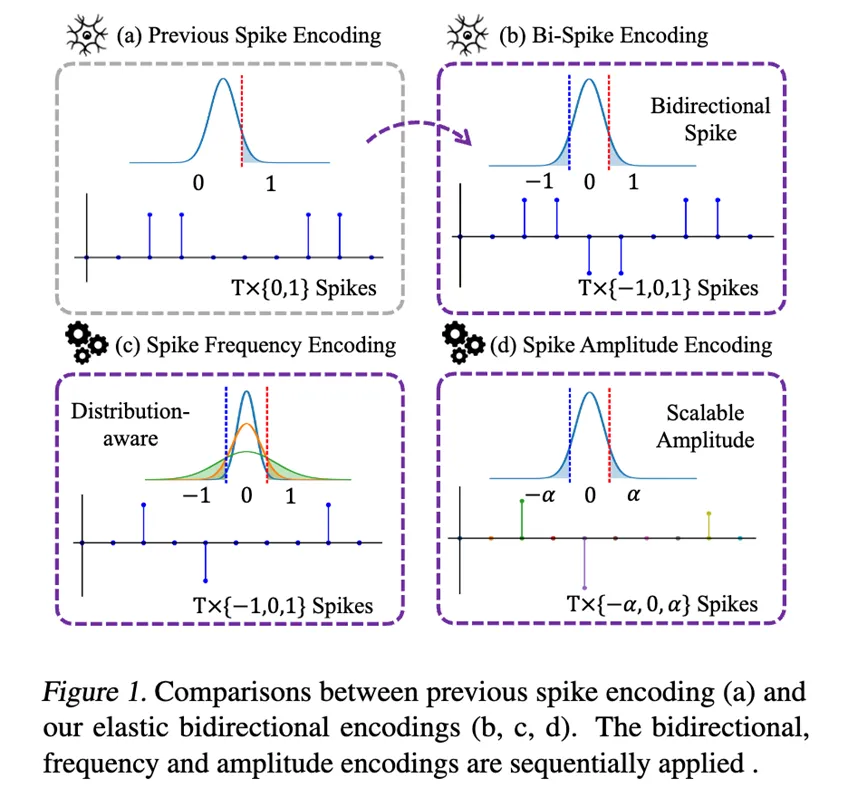
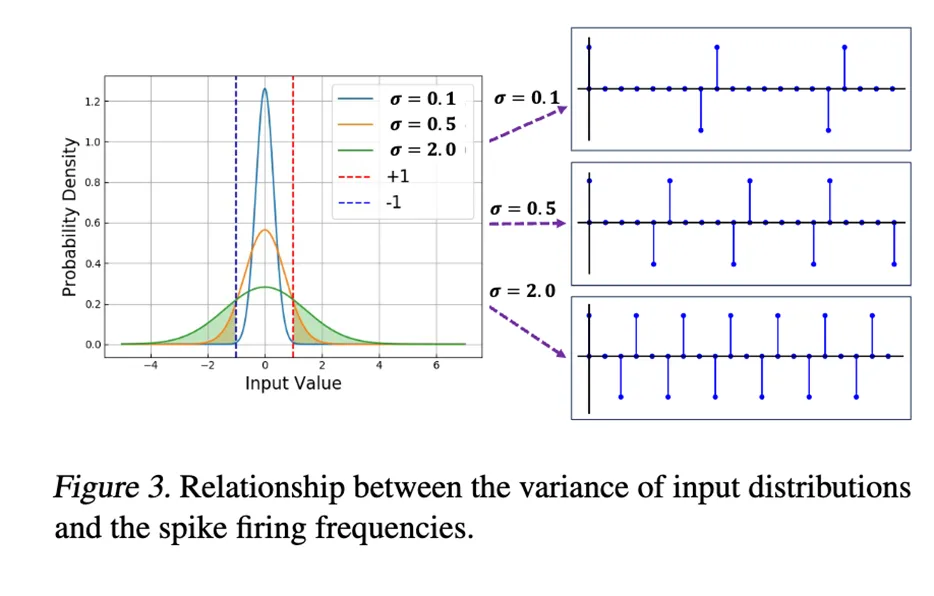
**13. **SpikeLM:通过松弛双向脉冲机制实现脉冲驱动的通用语言建模
SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
论文作者:邢兴润,张正,倪子懿,肖诗涛,鞠一鸣,樊思琪,王业全,张家俊,李国齐 文章的目标是开发一种类脑的低功耗人工智能语言模型,即生物启发的脉冲神经网络(SNNs)。与传统的人工神经网络(ANNs)相比,SNNs具有生物神经细胞可解释性、事件驱动的稀疏性和二值激活的优势。近期,大规模语言模型展现出了让人印象深刻的泛化能力,这激发了探索更通用的脉冲驱动模型的动机。然而,现有SNN中的二值脉冲无法编码足够的语义信息,这给泛化带来了技术挑战。 本文提出了一种全新的全脉冲机制,用于通用语言任务,包括判别性和生成性任务。与以往的{0,1}脉冲不同,我们提出了一种更通用的脉冲形式,具有双向、松弛的幅度和频率编码,同时保持了SNN的加性特性。在单时间步中,脉冲通过方向和幅度信息得到增强;在脉冲频率上,我们设计了一种控制脉冲发射率的策略。我们将这种松弛的双向脉冲机制应用于语言建模,命名为SpikeLM。这是第一次使用全脉冲驱动模型处理通用语言任务,其准确性大幅超越了以往方法。SpikeLM还大大缩小了SNN和ANN在语言建模中的性能差距。
 代码链接:
代码链接:
