导读 | CVPR全称为IEEE国际计算机视觉与模式识别会议,是计算机视觉领域三大顶级会议之一。CVPR 2024将在美国西雅图举办。我们将分两期对自动化所的录用研究成果进行简要介绍(排名不分先后),欢迎大家共同交流讨论。

**1. **驶向未来:面向自动驾驶的多视图预测与规划的世界模型
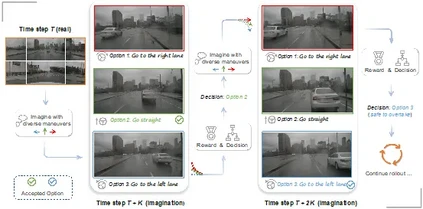
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving 论文作者:王宇琪,何嘉伟,范略,李鸿鑫,陈韫韬,张兆翔 最近,世界模型的概念引发了广泛关注。我们首次提出了一种名为Drive-WM的全新多视图世界模型,旨在增强端到端自动驾驶规划的安全性。Drive-WM模型通过多视图世界模型,能够想象不同规划路线的未来情景,并根据视觉预测获取相应的奖惩反馈,从而优化当前的路线选择,为自动驾驶系统的安全提供了保障。Drive-WM是与现有端到端规划模型兼容的第一个驾驶世界模型。通过视图因子分解促进的联合时空建模,我们的模型在驾驶场景中生成了高保真度的多视角视频。在其强大的生成能力基础上,我们首次展示了将世界模型应用于安全驾驶规划的潜力。对真实世界驾驶数据集的评估验证了我们的方法可以生成高质量、一致性和可控性的多视角视频,为真实世界的模拟和安全规划开辟了新的可能性。

图1. 自动驾驶世界模型
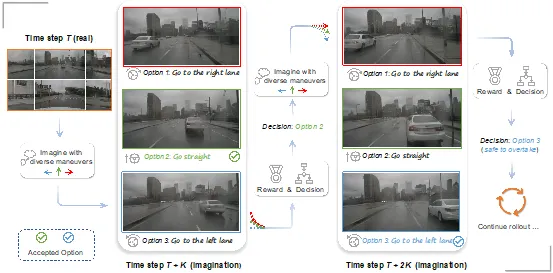
图2. 基于多视图世界模型的预测和规划 论文链接: https://arxiv.org/abs/2311.17918 代码链接: https://github.com/BraveGroup/Drive-WM Project Page: https://drive-wm.github.io
**2. **PanoOcc:面向视觉三维全景分割任务的统一栅格占用表示
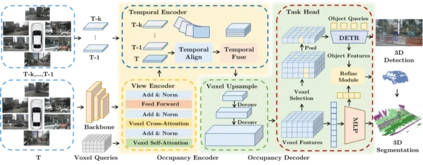
PanoOcc: Unified Occupancy Representation for Camera-based 3D Panoptic Segmentation 作者:王宇琪,陈韫韬,廖星宇,范略,张兆翔 全面的三维场景感知对于自动驾驶和机器人领域至关重要。基于相机的三维感知取得了迅速发展,但过去的任务如三维目标检测、地图语义分割等,各自关注场景表示的某一方面,且表示方式不统一。我们希望能够探索一种统一的场景表示,使其能统一表达这些任务,并将背景和前景物体统一建模。目前基于鸟瞰图特征的方法在三维目标检测上表现出色,但由于缺失了高度和形状信息,直接应用于三维场景感知任务时性能较差。这启示需要探索适合三维场景的特征表示,这也使得三维的栅格占用表示重新受到关注。然而,与二维空间相比,三维空间更加稀疏,直接将二维鸟瞰图特征扩展到三维体素表示将带来巨大的显存和计算开销。本研究提出PanoOcc模型,将检测和分割任务联合学习,统一了检测和分割任务的输出表示。为实现高效的特征学习,我们设计了从粗到细的解码层结构,并探索了稀疏表示的应用。本研究进行了大量消融研究以验证有效性和效率,在基于相机的机的三维语义分割、全景分割和密集占用栅格预测等任务中都取得了最先进性能。
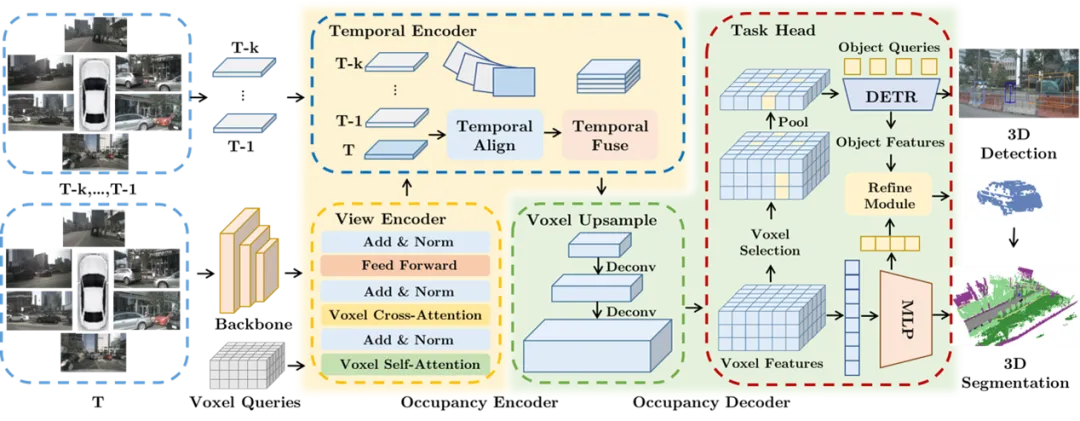
图. PanoOcc的整体模型设计 论文链接: https://arxiv.org/abs/2306.10013 代码链接: https://github.com/Robertwyq/PanoOcc
**3. **基于可靠持续学习的失败检测
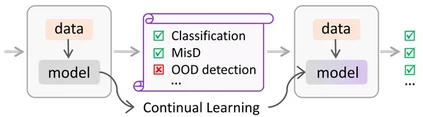
RCL: Reliable Continual Learning for Unified Failure Detection 作者:朱飞,程真,张煦尧,刘成林,张兆翔 深度神经网络往往对未知输入过于自信,给实际应用带来了较大风险。已有研究主要关注检测来自未知类别的分布外样本,而忽略了来自已知类别的错分样本。最近的研究发现,分布外检测方法往往对错分检测有害,表明这两项任务之间似乎存在折中。本文研究了统一失败检测问题,即同时检测错分样本和分布外样本。我们发现对二者的学习目标进行联合训练不足以获得统一检测的能力,而序列学习的模式有较大潜力。受此启发,本文提出了一种可靠的持续学习范式,使模型先具备错分检测的能力,然后在不降低已有可靠性的前提下通过持续学习提升模型的分布外检测能力。实验表明,该方法具有优异的失败检测性能。
可靠持续学习示意图
**4. **基于偏振光融合优化的深度测量增强方法
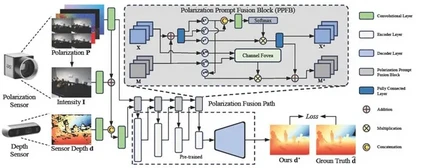
Robust Depth Enhancement via Polarization Prompt Fusion Tuning 作者:池村敬,黄一鸣,菲利克斯·海德,张兆翔,陈启峰,雷晨阳 本文提出了一个利用偏振成像改进各种深度传感器不准确深度测量的通用框架。现有的深度传感器在存在透明或反射物体的复杂场景中会提供不准确的深度值,而此前基于偏振的深度增强方法主要利用纯物理公式来处理单一传感器的数据。相比之下,本文所提出的方法采用深度学习,通过训练神经网络从偏振数据和来自不同传感器的传感器深度图来获得更稠密准确的深度图。本文提出了一种称为Polarization Prompt Fusion Tuning (PPFT)的策略,其利用在大规模RGB数据集上预训练的模型,在规模有限的偏振数据集上进行融合增强,从而有效地训练出更强大的深度增强模型。本文在一个公共数据集上进行了大量实验证明,与现有的深度增强基准方法相比,所提出的方法表现最佳。

图1. 图中数据来自偏振相机以及d-ToF深度传感器,本方法在具有挑战性的深度增强问题上产生准确的结果,包括深度补全、透明表面的深度修复、形状校正等。如图所示,透明水瓶处的深度被有效修复 。
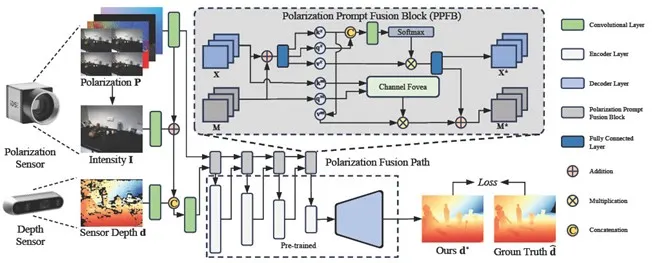
图2. 本文所提出的偏振提示融合块(PPFB)将偏振光信息作为额外视觉提示输入,采用递进的方法依次融合到从预训练层提取的特征中。 相关链接: https://lastbasket.github.io/PPFT/
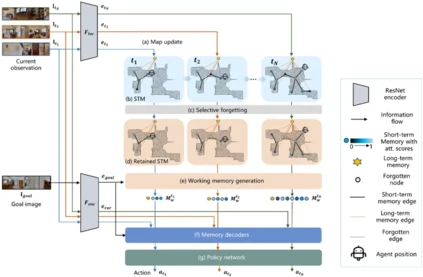
**5. **MemoNav: 基于类人工作记忆的视觉导航智能体
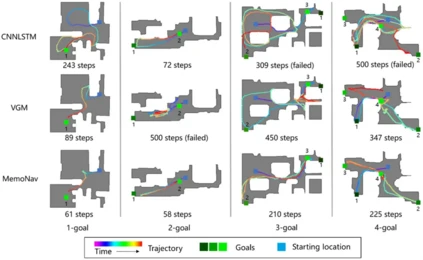
MemoNav: Working Memory Model for Visual Navigation 论文作者:李鸿鑫,王泽禹,杨旭,杨雨然,梅树起,张兆翔 人类导航至多目标时,会回忆起与目标相关的地点特征,忽视其他无关区域的记忆,并利用激活的这部分局部信息来快速规划路线,无需重复探索。MemoNav借鉴人类这种工作记忆机制,结合短期记忆和长期记忆一起提升导航决策性能(图1)。其引入了遗忘机制、长期记忆、和工作记忆三个协同组件: 选择性遗忘机制** 由于并非所有地图结点都和导航目标有关,MemoNav提出利用目标注意力机制,计算地图结点和当前目标的注意力分数,然后暂时“遗忘”分数较低即对导航帮助不大的偏远结点,被保留的则用于下游决策。 长期记忆 为了习得场景的全局表征,智能体维护一个和所有短期记忆结点相连的全局结点作为长期记忆,不断地通过图注意力机制聚合短期记忆特征。 工作记忆 **利用一个图注意力机制编码保留的短期记忆和长期记忆,得到和当前导航任务最相关的工作记忆,输入给下游策略模块以得到最终导航行为。 在Gibson和Matterport3D场景中,该方法的多目标导航性能大幅超越SoTA模型。定性实验显示其可以规划更快捷的路径,且死锁概率更小(图2)。
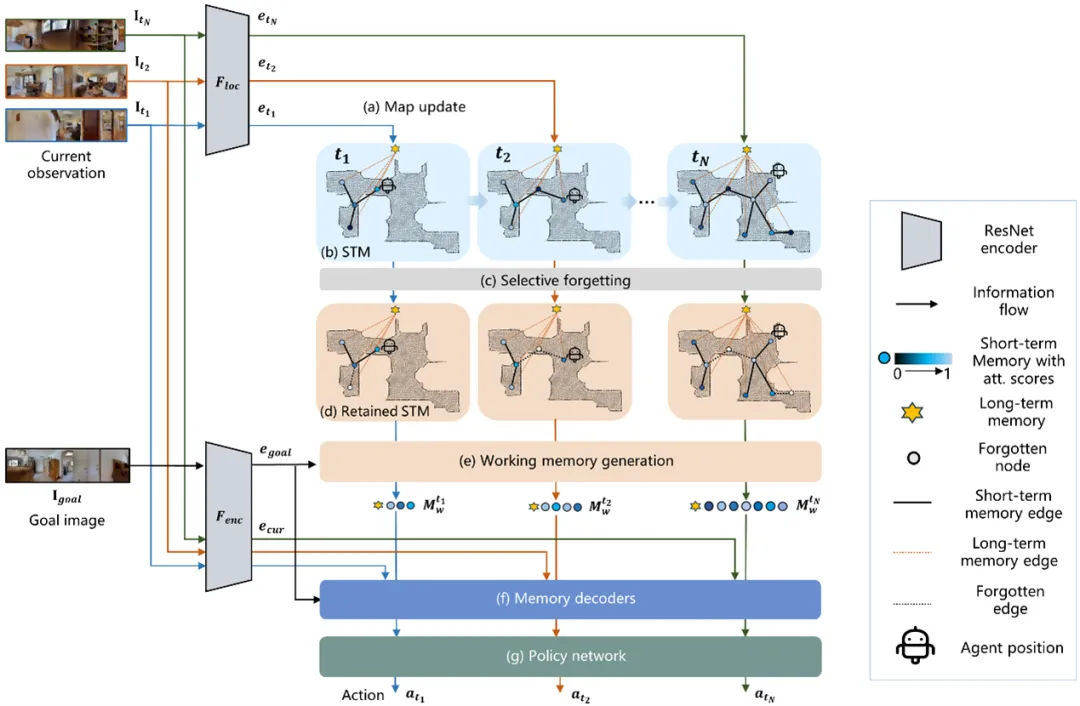
图1. MemoNav借鉴人脑工作记忆的导航模型。MemoNav通过注意力机制选择与当前导航目标相关的短期记忆(即地图结点)和长期记忆(即全局结点)一起生成工作记忆,用于下游决策。
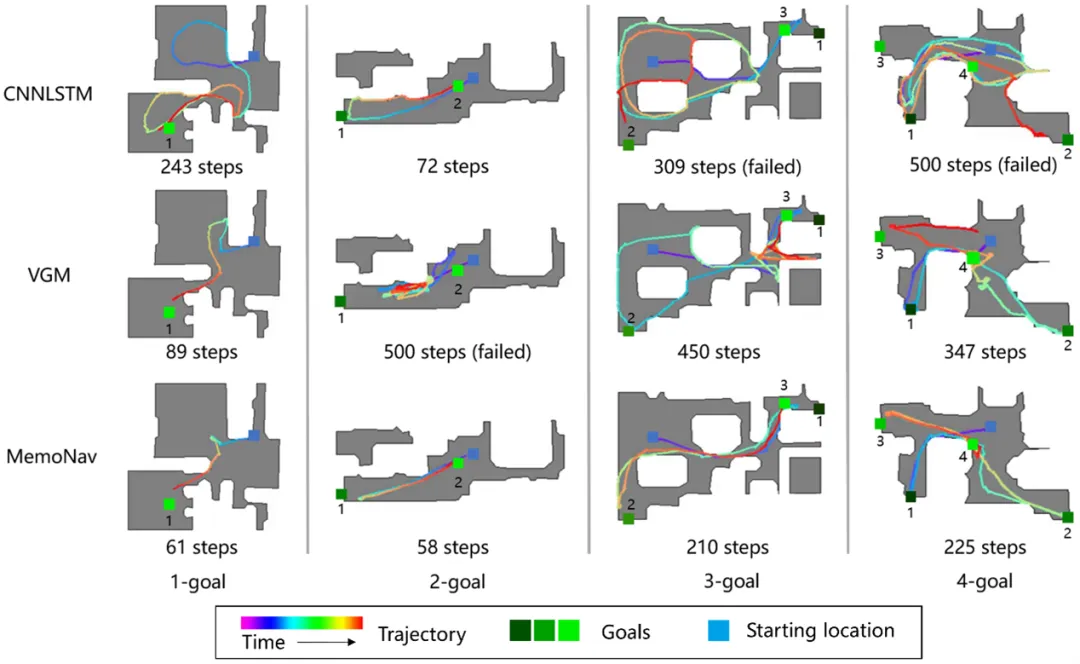
图2. MemoNav和现有其它方法的定性对比。 代码链接: https://github.com/ZJULiHongxin/MemoNav 论文链接: https://arxiv.org/abs/2402.19161
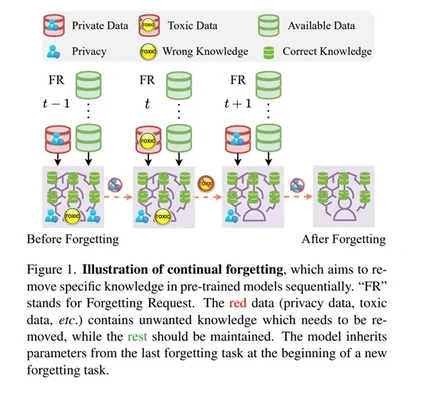
**6. **预训练视觉模型的连续遗忘
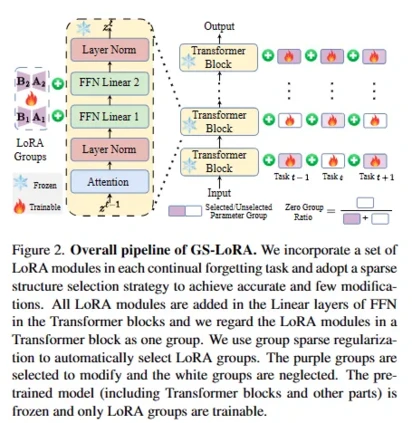
Continual Forgetting for Pre-trained Vision Models 论文作者:赵宏博、尼博琳、樊峻菘、王玉玺、陈韫韬、孟高峰、张兆翔 出于隐私和安全考虑,如今变得越来越明显的是,需要从预训练的视觉模型中擦除不需要的信息。在现实世界场景中,用户和模型拥有者可以随时提出擦除请求。这些请求通常形成一个序列。因此,在这样的设置下,期望从预训练模型中连续移除选定信息,同时保留其余信息。我们将这个问题定义为持续遗忘,并确定了两个关键挑战。(i) 对于不需要的知识,有效且高效的删除至关重要。(ii) 对于剩余的知识,遗忘过程带来的影响应尽可能小。为了解决这些问题,我们提出了群稀疏LoRA(GS-LoRA)。具体来说,针对(i),我们使用LoRA模块独立地对Transformer块中的FFN层进行微调,以应对每个遗忘任务,并针对(ii),采用了简单的组稀疏正则化,实现了特定LoRA群组的自动选择并将其他群归零。GS-LoRA有效、参数高效、数据高效且易于实现。我们在人脸识别、目标检测和图像分类上进行了广泛实验,并展示了GS-LoRA能够在对其他类别影响最小的情况下忘记特定类别。
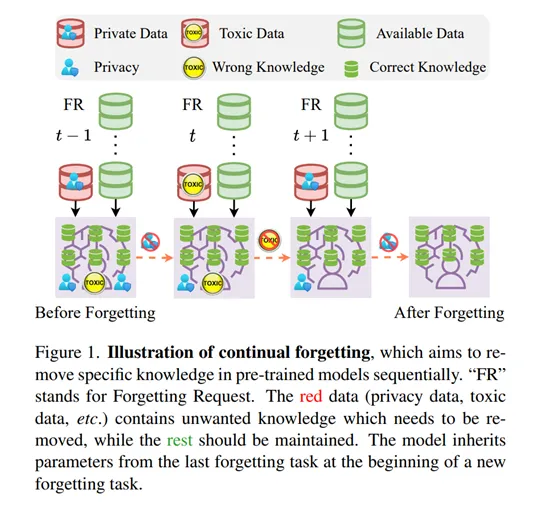
图1. 连续遗忘
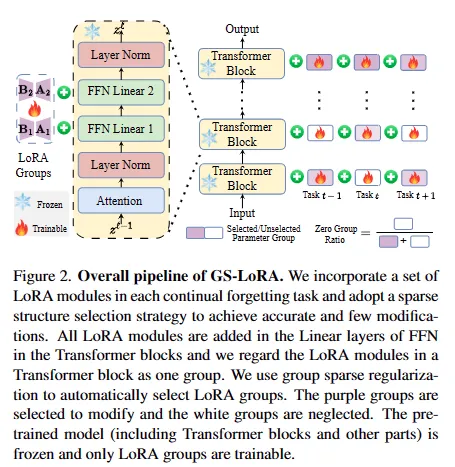
图2. GS-LoRA管线示意图 论文链接: arxiv.org/pdf/2403.11530.pdf 代码链接: https://github.com/bjzhb666/GS-LoRA
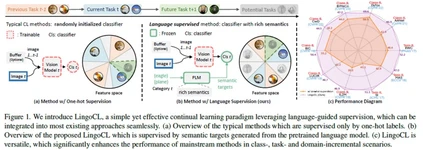
**7. **通过语言引导监督加强视觉连续学习
Enhancing Visual Continual Learning with Language-Guided Supervision 论文作者:尼博琳、赵宏博、张承灏、胡珂、孟高峰、张兆翔、向世明 连续学习旨在使模型能够在不忘记先前获得的知识的情况下学习新的任务。当前的工作往往集中在网络结构、回放数据和正则化等技术。然而,数据类别标签中的语义信息在很大程度上被忽略了。当前的方法往往使用独热标签,每个任务独立学习分类头。我们认为,独热标签无法捕捉连续学习场景下不同类别跨任务的语义关系,阻碍了知识在任务间的有效转移。在本工作中,我们重新审视了分类头在连续学习场景中的作用,并用来自预训练语言模型的语义知识取代了随机初始化的分类头。具体来说,我们使用预训练语言模型为每个类别生成语义目标,这些目标在训练期间被冻结作为监督信号。这些目标充分考虑了跨任务的所有类之间的语义相关性。实证研究表明,我们的方法通过减轻表征漂移和促进跨任务的知识转移来减轻遗忘。所提出的方法易于实现,并且可以无缝地插入到现有方法中。
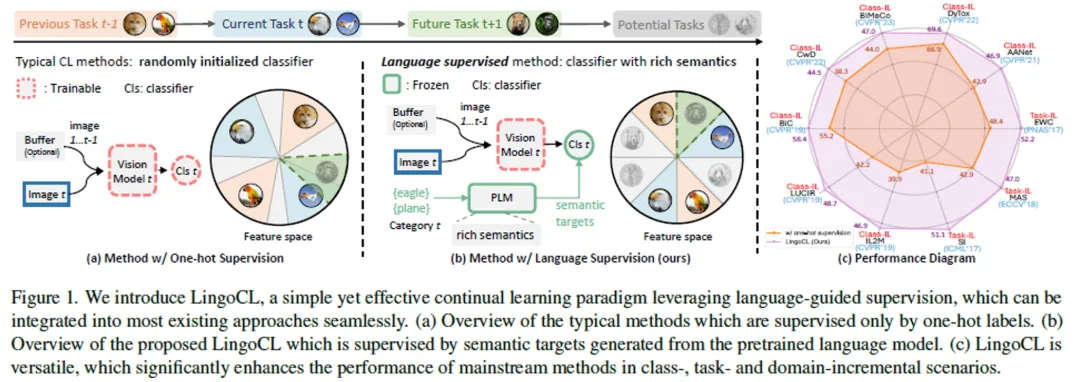
图1. LingoCL示意图及效果
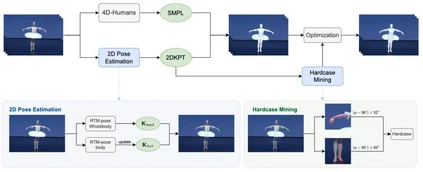
**8. **HardMo:一个大规模难例动作捕捉数据集
HardMo: A Large-Scale Hardcase Dataset for Motion Capture 论文作者:廖佳琪,罗传琛,杜伊诺,王玉玺,殷绪成,张曼,张兆翔,彭君然 本文介绍了一个大规模的难例动作捕捉数据集——HardMo,旨在弥补现有人体mesh恢复方法(HMR)在处理舞蹈和武术等场景中不常见姿势的不足。由于这些领域的动作具有高速度和高张力特征,而现有数据集大多聚焦于日常动作,缺乏这类复杂动作的样本,导致模型难以有效处理舞蹈和武术场景。为此,我们提出了一套数据收集流程,包括自动爬取、精确标注和难例挖掘,基于此流程快速建立了包含700万张图片的大型数据集HardMo。这些图片覆盖了15类舞蹈和14类武术,每张图片都配有精确的标注。实验发现,舞蹈和武术中的预测失败主要表现在手腕和脚踝的不对齐上。此外针对这两个难点,我们利用提出的自动化流程筛选出相关数据,构建了名为HardMo-Hand和HardMo-Foot的子集。广泛的实验表明,我们的标注流程和数据驱动解决方案的有效性。特别是,经HardMo训练后的HMR方法甚至在我们的基准测试上超过了当前的最先进技术4DHumans。

图1. HardMo 数据集概览
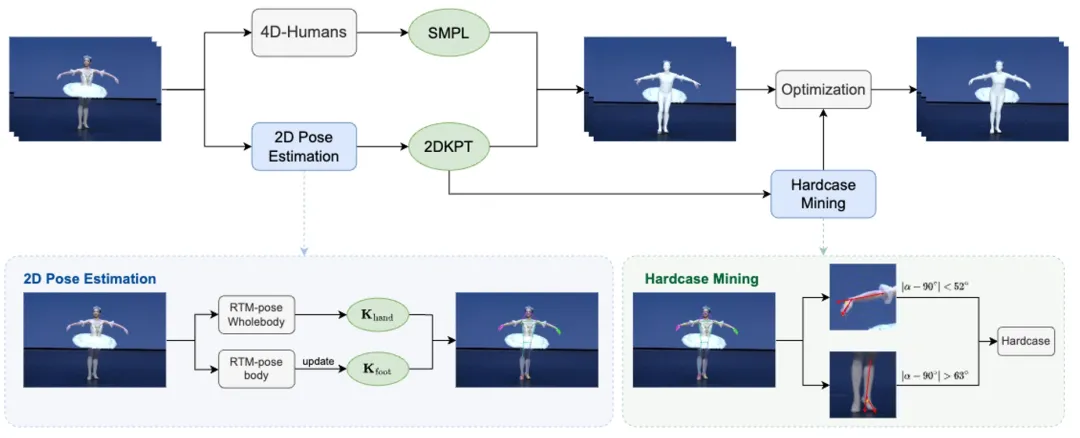
图2. 自动化标注流程
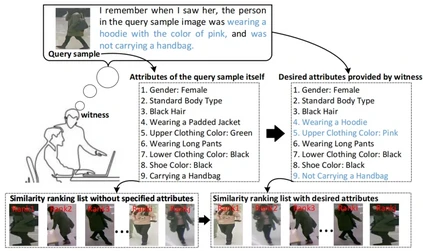
**9. **属性引导的行人检索:跨越行人重识别中的内在属性变化
Attribute-Guided Pedestrian Retrieval: Bridging Person Re-ID with Internal Attribute Variability 论文作者:黄延、张彰、吴强、钟怡、王亮 在智能监控领域中,行人检索(重识别)技术,扮演着至关重要的角色。目前的Re-ID方法常常忽略对行人细微属性变化所导致的外观变化显式建模。针对这一问题,我们的研究提出了视觉属性引导的行人检索(AGPR)任务,旨在通过对特定人体属性查询条件与查询图像的整合来提高行人检索准确性。我们提出的基于ViT属性引导的行人检索(ATPR)框架通过对行人属性组间相关性和属性组内去相关性建立正则化项,有效地融合了全局行人ID识别与局部属性学习。我们基于RAP行人属性数据集构建了新的AGPR任务基准,并进行了广泛实验,结果验证了我们提出的ATPR方法在AGPR任务中的有效性。
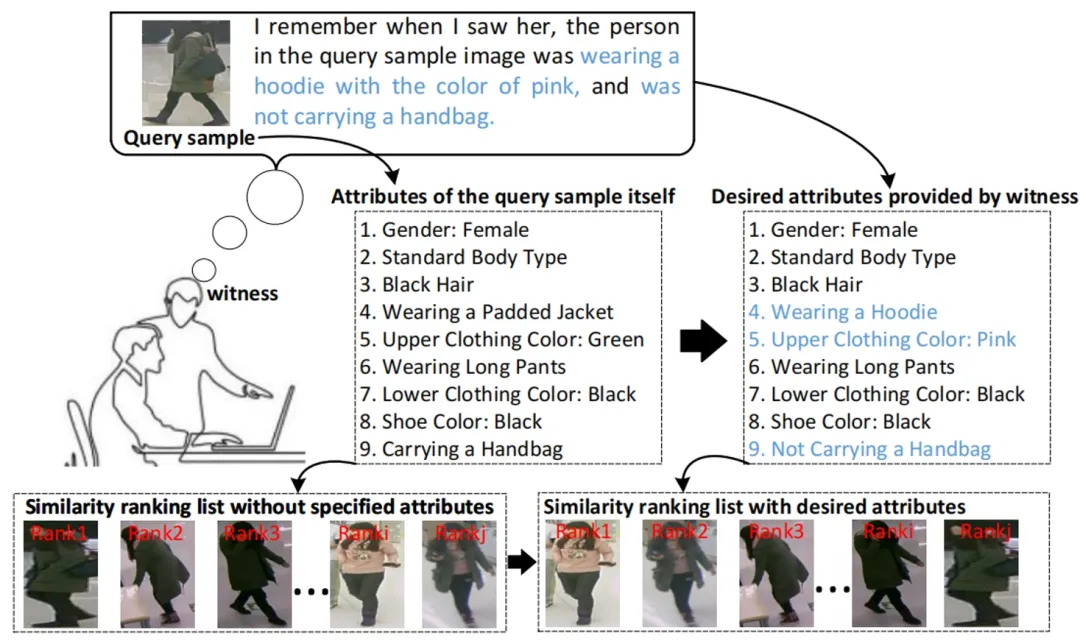
图. 视觉属性引导的行人检索(AGPR)示意图
10. 调查视觉-语言模型在视觉定位任务上的组合关系挑战
Investigating Compositional Challenges in Vision-Language Models for Visual Grounding 论文作者:曾宇楠,黄岩,张津津,揭泽群,柴振华,王亮 预训练的视觉-语言模型(VLMs)在各种下游任务中取得了高性能,这些模型已被广泛应用于视觉定位任务。然而,尽管大规模的视觉和语言预训练贡献了性能提升,我们发现最先进的VLMs在定位任务的组合推理上存在困难。为了证明这一点,我们提出了属性、关系和主次定位(ARPGrounding)基准测试,以测试VLMs在视觉定位任务中的组合推理能力。ARPGrounding包含11,425个样本,并从三个维度评估VLMs的组合理解能力:1)属性,测试对目标属性的理解;2)关系,测试对目标之间关系的理解;3)主次,反映了与名词相关的词性的意识。使用ARPGrounding基准测试,我们评估了几种主流的VLMs。实验结果表明,这些模型在传统的视觉定位数据集上表现相当好,达到或超过了最先进方法的性能,然而在组合推理上显示出明显的不足。更进一步,我们提出了组合关系感知的微调流程,展示了利用低成本的图像-文本标注来增强VLMs在定位任务中的组合理解能力的潜力。

图1. 在视觉定位任务中测试CLIP的组合关系理解的例子。CLIP在辨别真实目标和欺骗性目标时遇到挑战。(左)CLIP被一只不同颜色的狗误导。(右)CLIP被短语中的另一个目标误导。这两个例子都表明CLIP对组合结构的把握存在不足。
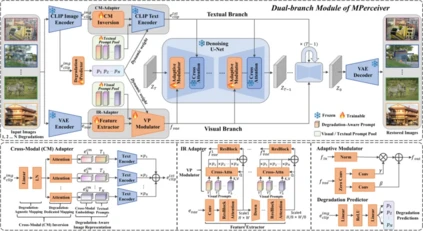
**11. **多模态提示感知器:为多功能图像复原赋能自适应性、泛化性和保真度
Multimodal Prompt Perceiver: Empower Adaptiveness, Generalizability and Fidelity for All-in-One Image Restoration 论文作者:艾雨昂,黄怀波,周晓强,王杰翔,赫然 本文介绍了一种名为MPerceiver的多模态提示学习方法,旨在解决多功能图像复原中面临的复杂真实场景退化问题。MPerceiver通过利用Stable Diffusion中的先验知识来增强自适应性、泛化性和保真度。具体来说,本文提出了一个双分支模块提供多模态提示:文本提示用于整体表征,而视觉提示用于多尺度细节表征。这两种提示通过CLIP图像编码器的退化预测动态调整,能够适应各种未知的退化情况。此外,MPerceiver采用了一个插件式细节精炼模块,通过编码器到解码器的信息跳连,改善了图像复原的保真度。MPerceiver在9个图像复原任务中进行了训练,并且在许多任务中甚至超越了最先进的特定任务方法。在多任务预训练之后,MPerceiver学习到了底层视觉的通用表征,展现了强大的Zero-Shot和Few-Shot能力。在16个复原任务上的实验证明了MPerceiver在自适应性、泛化性和保真度方面的优越性。
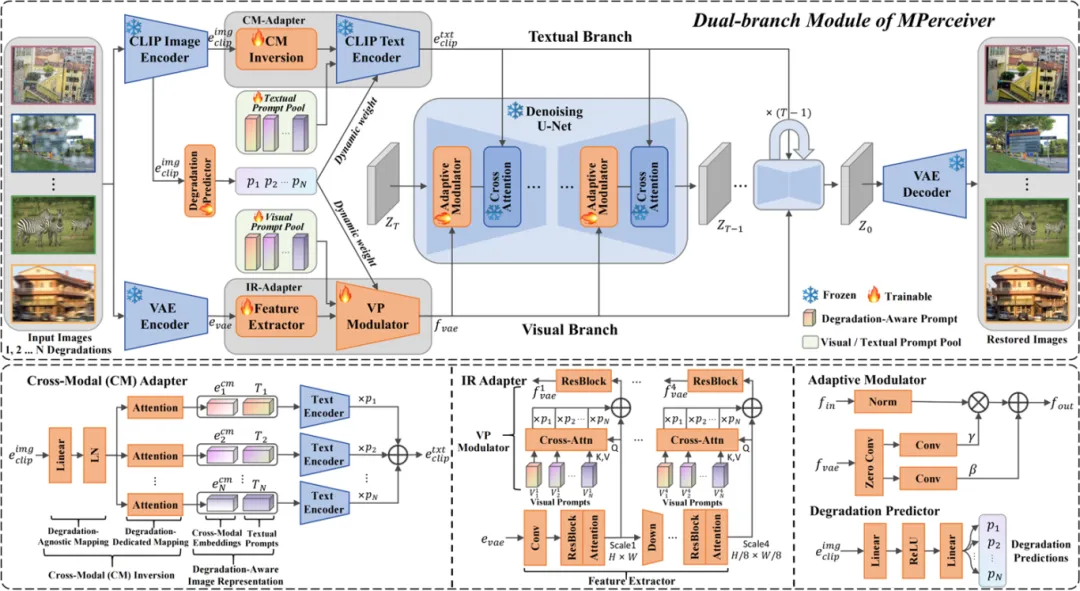
图. MPerceiver双分支结构 论文链接: https://arxiv.org/abs/2312.02918
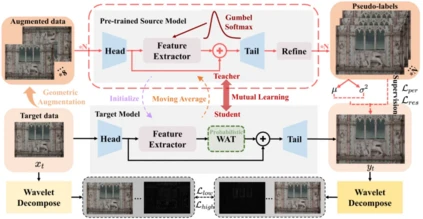
**12. **基于小波增强Transformer和不确定性感知的无源自适应图像超分辨率
Uncertainty-Aware Source-Free Adaptive Image Super-Resolution with Wavelet Augmentation Transformer 论文作者:艾雨昂,周晓强,黄怀波,张磊,赫然 无监督领域适应能够通过同时访问源数据和目标数据,有效地解决真实场景图像超分辨率中的域差异问题。考虑到实际场景中源数据的隐私政策或传输限制,本文提出了一种无源领域自适应框架SODA-SR用于图像超分辨率。SODA-SR利用源训练模型生成精细化的伪标签,用于师生学习。为了更好地利用伪标签,本文提出了一种新颖的基于小波的增强方法,名为小波增强Transformer,它可以灵活地结合现有网络,隐式地产生有用的增强数据。此外,本文提出了一种不确定性感知的自训练机制,以提高伪标签的准确性,不准确的预测将通过不确定性估计得到纠正。实验表明,即使不访问源数据,SODA-SR也在多种设置中超越最先进的UDA方法,并且不受特定网络架构的限制。
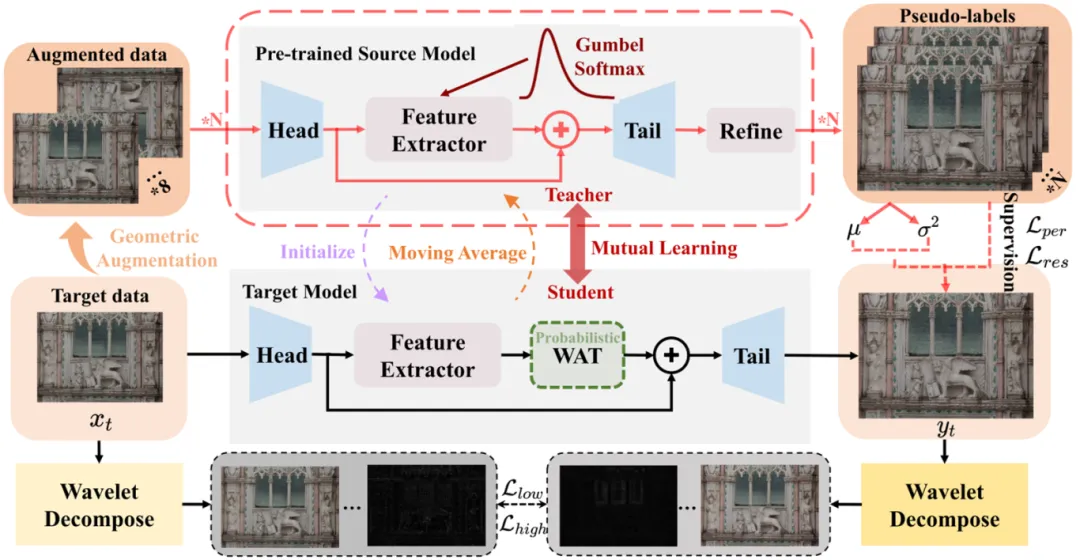
图. SODA-SR结构 论文链接: https://arxiv.org/abs/2303.17783
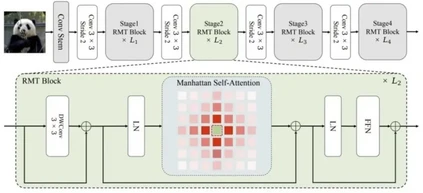
**13. **RMT:Retentive Network遇上Vision Transformer
RMT: Retentive Networks Meet Vision Transformers 论文作者:樊齐航,黄怀波,陈铭锐,刘红敏,赫然 最近,Retentive Network(RetNet)作为一种有可能取代Transformer的架构出现,引起了自然语言处理社区的广泛关注。作者将RetNet的思想迁移到视觉领域并将RetNet和Transformer结合起来,提出了RMT。受RetNet启发,RMT在视觉Backbone中引入了显式衰减,将与空间距离相关的先验知识引入到视觉模型中。这种与距离相关的空间先验允许显式控制每个Token可以关注的Token范围。此外,为了降低全局建模的计算成本,作者沿图像的两个坐标轴分解了这个建模过程。大量的实验表明,RMT在各种计算机视觉任务如分类、目标检测、实例分割和语义分割等中表现出色。
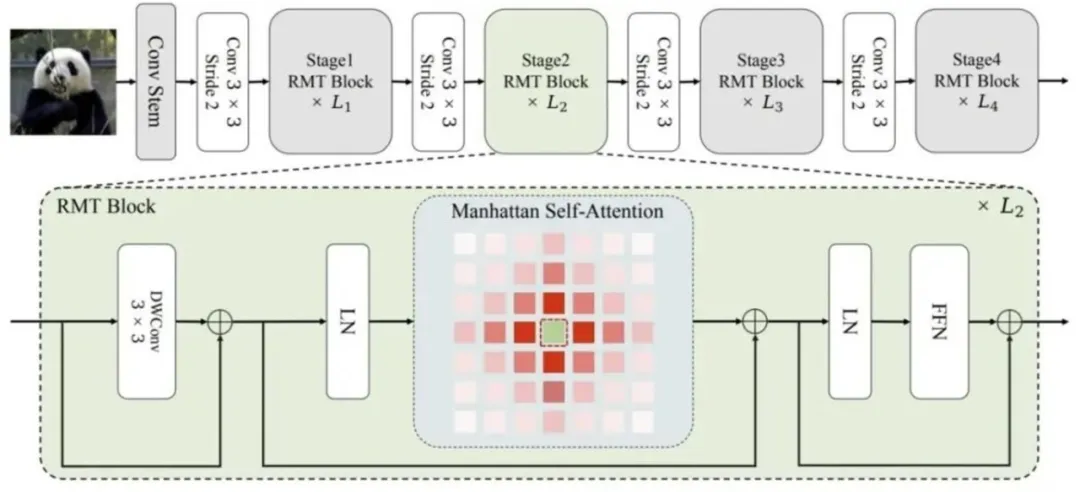
图. RMT示意图 论文链接: https://arxiv.org/abs/2309.11523 代码链接: https://github.com/qhfan/RMT
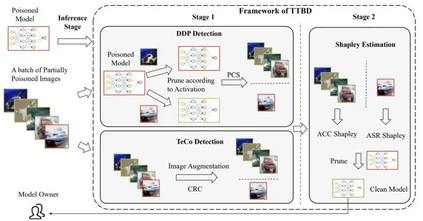
**14. **面向测试过程检测及修复的神经后门防御
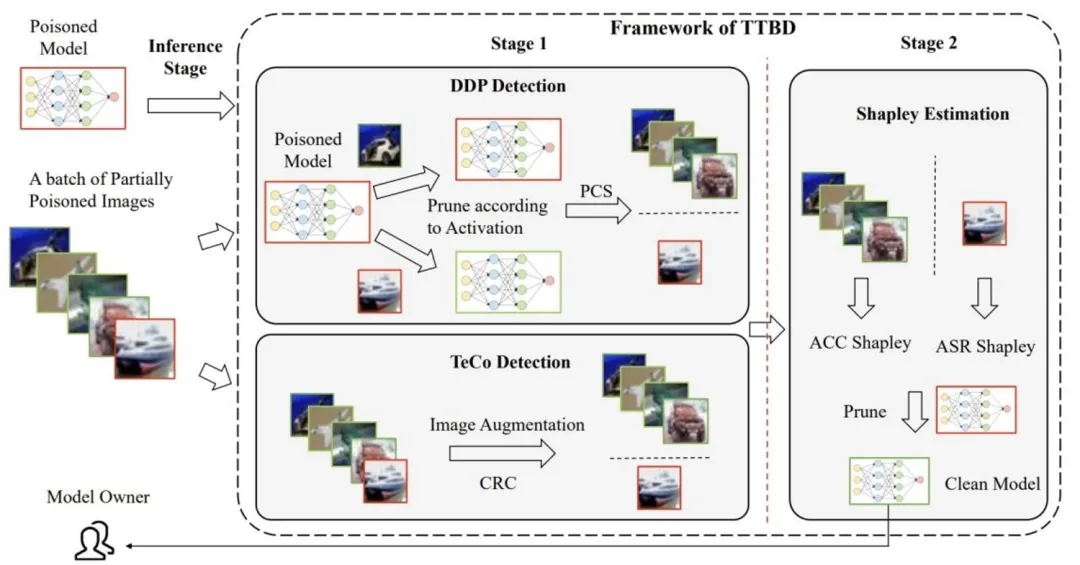
Backdoor Defense via Test-Time Detecting and Repairing 论文作者:关霁洋,梁坚,赫然 针对神经后门防御问题,之前的工作主要在模型部署之前使用干净样本来去除模型神经后门,而本文研究了利用部分污染的模型测试数据从模型中去除神经后门,并提出了一种两阶段的神经后门防御方法。在第一阶段,本文提出了一种后门样本检测方法DDP,它从一批混合的部分投毒数据中识别出后门样本,其后,本文使用夏普利值估计定位并去除模型中的神经后门。我们的的方法TTBD在多种网络结构下针对多种不同的神经后门攻击,均取得了良好的神经后门防御效果。
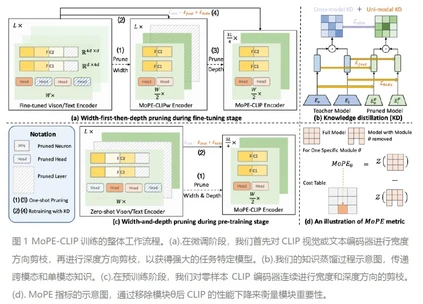
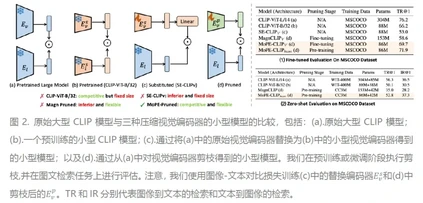
**15. **MoPE-CLIP:使用模块化剪枝误差度量的高效视觉-语言模型结构化剪枝方法
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric 论文作者:林浩坤,柏昊立,刘智立,侯璐,孙沐毅,宋林琦,魏颖,孙哲南 本文探索了多种多模态视觉语言预训练模型(如CLIP)的小型化方案,研究发现直接使用较小的预训练模型或应用基于权重大小的剪枝,往往导致灵活性不足和性能不佳。针对上述挑战,我们提出了一种新颖的模块化剪枝误差(MoPE)度量方法,旨在精确评估CLIP模块在跨模态任务中的重要性。利用MoPE度量,我们进一步提出适用于预训练和特定任务微调两个压缩阶段的剪枝框架,同时设计了更高效的知识蒸馏损失函数。在预训练阶段,MoPE-CLIP利用教师模型的知识,显著减少了预训练成本,并保持CLIP模型强大的零样本能力。在微调阶段,通过先宽度剪枝再深度剪枝的方式,我们能够在特定任务上产生性能强大的专用模型。我们通过两个阶段的广泛实验验证了MoPE度量的有效性, MoPE-CLIP超越了之前最先进的多模型模型剪枝方案,与先前采用单一模态剪枝度量或涉及昂贵的可学习掩模搜索过程的方法相比,我们的方法不仅提高了性能,而且提供了一种更灵活、成本效益更高的解决方案。
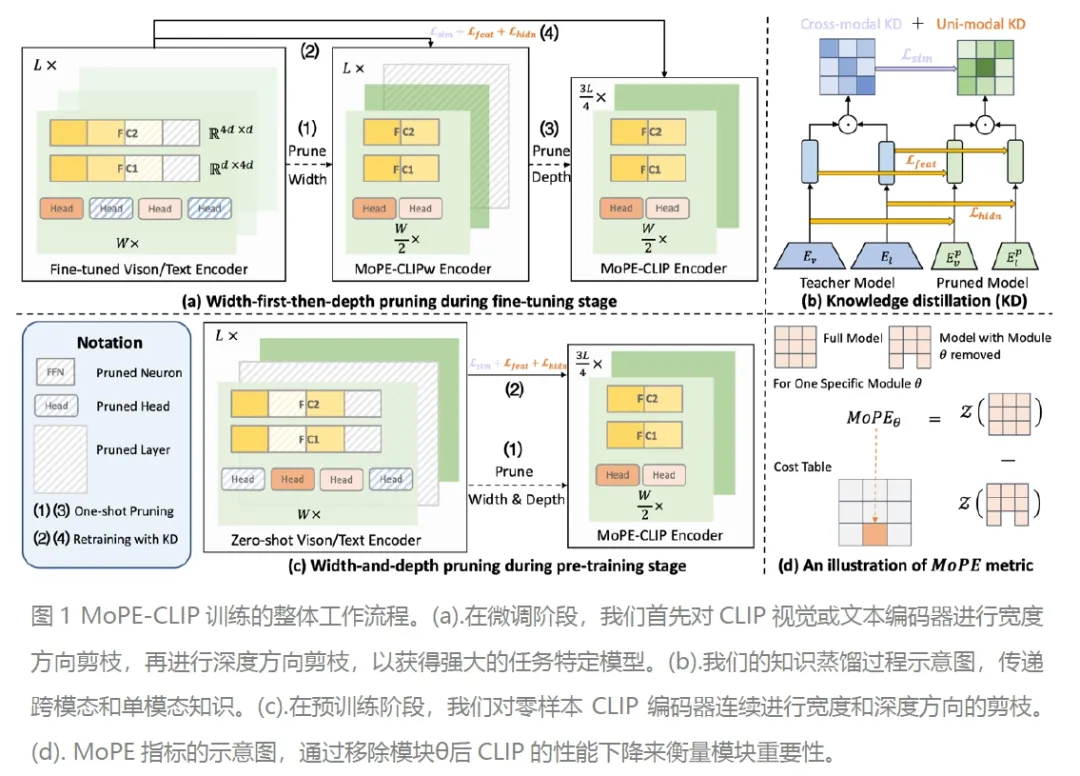
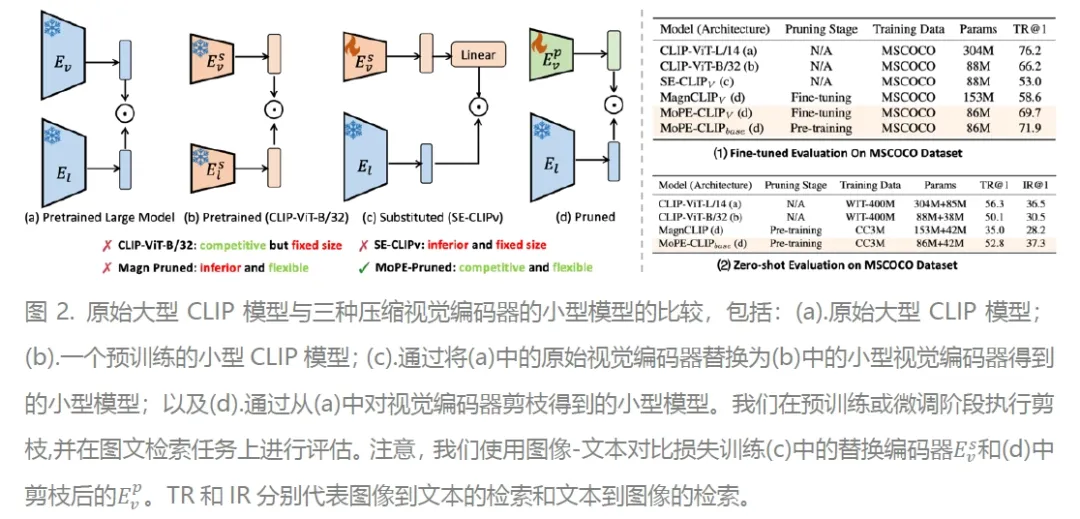
论文链接: https://arxiv.org/abs/2403.07839
**16. **SfmCAD:基于“草图+特征”建模的无监督CAD重建
SfmCAD: Unsupervised CAD Reconstruction by Learning Sketch-based Feature Modeling Operations 论文作者:李朴,郭建伟,李慧斌,Bedrich Benes,严冬明 SfmCAD通过学习现代CAD工作流中基于草图的特征建模操作来重构三维形状。给定一个体素形式表示的三维形状,SfmCAD能够无监督地学习一种草图+路径参数化表示方法,包括形状部件的二维草图及其三维扫掠路径。SfmCAD利用二维草图来表达局部几何细节,并通过三维路径捕捉整体结构,实现了形状细节与结构之间的解耦。这种转化为参数化形式的方法不仅增强了模型的可解释性,还提高了输出结果的可编辑性,使用户能够方便地编辑形状的几何和结构特征。我们通过将SfmCAD应用于各种不同类型的对象,如CAD部件、ShapeNet形状和树干结构,展示了我们方法的有效性。
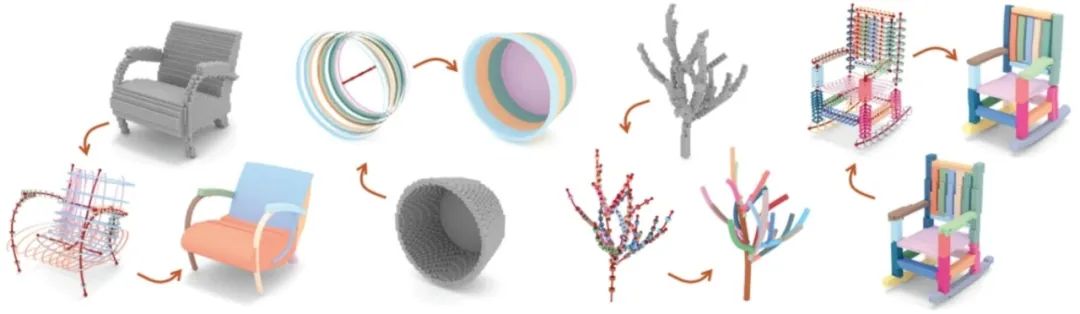
图1. “草图+特征”CAD重建结果示意图
**17. **SVDTree:基于语义体素扩散模型的单张图像树木三维重建
SVDTree: Semantic Voxel Diffusion for Single Image Tree Reconstruction 论文作者:李源、刘志浩、Bedrich Benes、张晓鹏、郭建伟 高效地表示和重建树木的三维几何仍然是计算机视觉和图形领域中的一个极具挑战性的问题。本研究提出了一种新颖的方法,用于从单个视角的照片生成逼真的树木三维模型。本研究将三维信息推理问题转化为语义体素扩散过程,该过程将树木的输入图像转换为三维空间中的新颖语义体素结构(SVS)。SVS编码了几何外观和语义结构信息(例如树干、树枝和树叶),从而保留了复杂的树木内部特征。针对SVS,本研究提出了一种新的混合树木建模方法,SVDTree,包括面向结构的树干重建和基于自组织的树冠重建两部分。本研究使用合成和真实树木的图像对SVDTree进行了算法验证和对比,结果表明,本研究方法能够更好地保留树木细节,并实现了更为逼真和准确的重建结果。

图. SVDTree用于单张图像树木三维重建。给定一张带掩码的图像,SVDTree使用扩散模型自动推断出树木的语义体素结构,并通过一个混合几何重建算法,生成具有高视觉保真度的三维树木模型。
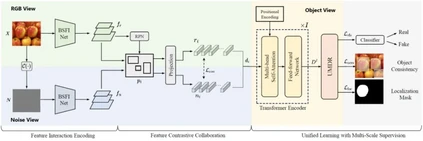
**18. **UnionFormer: 用于图像篡改检测和定位的多视角表征联合学习Transformer模型
UnionFormer: Unified-Learning Transformer with Multi-View Representation for Image Manipulation Detection and Localization 论文作者:李帅伯、马伟、郭建伟、徐世彪、李本冲、张晓鹏 本研究提出了UnionFormer,一种针对图像篡改检测与定位的新颖Transformer框架,它采用联合学习机制,整合了三个不同视角的篡改信息,以准确判别真伪图像。在该研究中,我们设计了能够从RGB视角和噪声视角交互提取篡改表征的BSFI-Net,其不仅对边界处的异常痕迹有着敏感的响应,而且能够建模多尺度的空间连续性。此外,本研究引入图像内不同目标间的不一致性作为全新的判别视角,并将其构建过程与检测、定位任务融合于一个统一的三任务联合学习架构中,从而实现不同任务间的相互促进。由此,本研究提出的模型在多重监督下,成功学习并整合三个视角的篡改判别特征,实现了高性能的同步检测与定位。实验结果表明,与先前的方法相比,本研究方法对多种类型的图像篡改具有更高的检测与定位准确率。
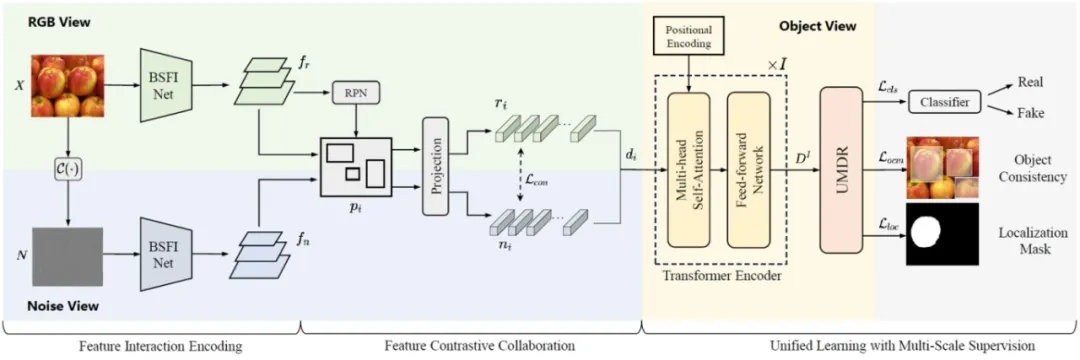
图. UnionFormer 整体框架。本方法通过BSFI-Net获取RGB视角和噪声视角下的篡改痕迹特征,并基于两者在联合学习中构建对象视角的表征。三个视角的信息被交互融合为统一的篡改判别表征 UMDR,用于同步检测与定位。每种视角由不同颜色表示。
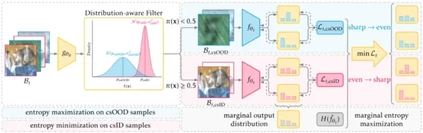
**19. **面向开放集测试阶段自适应的统一熵优化方法
Unified Entropy Optimization for Open-Set Test-Time Adaptation 论文作者:高正清、张煦尧、刘成林 测试阶段自适应(Test-time adaptation,TTA)旨在将一个在标记源域上预训练的模型适应到未标记的目标域。现有方法通常专注于在协变量偏移下改善TTA性能,而忽略了语义偏移。在这篇论文中,我们探索了一种更加符合实际的开放集TTA场景,其中目标域可能包含来自未知类别的样本。许多现有的封闭集TTA方法在应用于开放集场景时表现不佳,这可以归因于对数据分布和模型置信度的不准确估计。为了解决这些问题,我们提出了一个简单有效的框架,称为统一熵优化(Unified Entropy Optimization,UniEnt),它能够同时适应协变量偏移的分布内(csID)数据和检测协变量偏移的分布外(csOOD)数据。具体来说,UniEnt首先从测试数据中挖掘出伪csID和伪csOOD样本,随后对伪csID数据进行熵最小化处理,以及对伪csOOD数据进行熵最大化处理。此外,我们引入了UniEnt+以利用样本级置信度减轻硬数据划分造成的噪声。在CIFAR基准和Tiny-ImageNet-C上的广泛实验显示了我们框架的优越性。
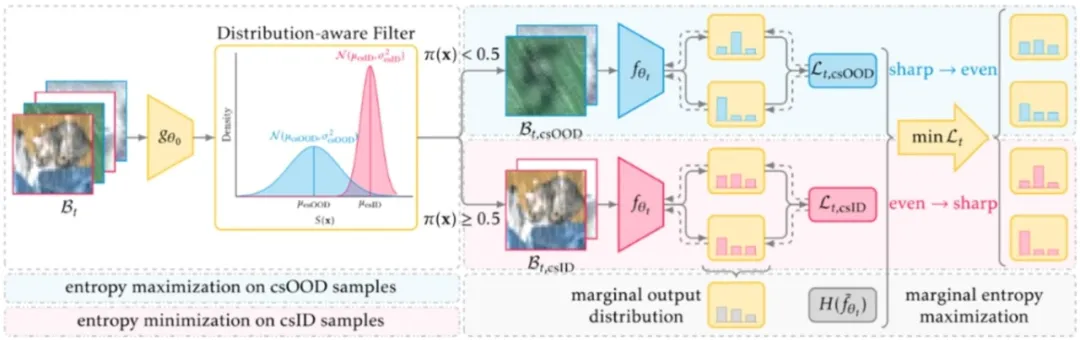
统一熵优化框架说明
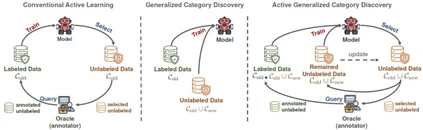
**20. **主动广义类别发现
Active Generalized Category Discovery 论文作者:马时杰、朱飞、钟准、张煦尧、刘成林
广义类别发现是一项现实且具有挑战性的开放环境任务,其目标是利用部分有标记的旧类别样本,对同时含有新类别和旧类别的无标签数据进行分类(聚类)。由于从旧类别中学到的知识不能完全迁移到新类中,并且新类完全未标记,这个任务存在固有的问题,包括:新旧类别之间分类性能不均衡、模型对新旧类别置信度分布不一致,特别是在标签很少的条件下。因此,对于新类的标注是很有必要的。然而,标记新类的成本极其高昂。为了解决这个问题,我们借鉴主动学习的思想,提出了一个新任务:主动广义类别发现。其目标是通过主动从无标注样本中选择有限数量的有价值样本进行标记,来提高新旧类的分类性能。为了解决这个问题,我们设计了一种自适应采样策略,考虑样本的新颖性、信息量和多样性,以自适应地选择具有适当不确定性的潜在新类样本。然而,由于新类发现本质是聚类问题,这会导致模型预测和ground truth标签索引的排序不同,查询的标签不能直接应用于后续训练。为了克服这个问题,我们进一步提出了一种稳定的标签映射算法,将真实标签转换到模型的标签空间,从而确保不同主动学习阶段的一致训练。我们的方法在通用和细粒度数据集上都实现了最先进的性能。
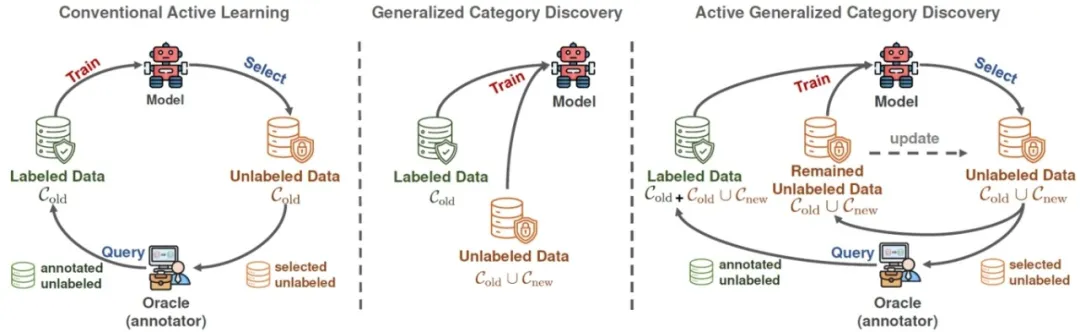
图. 主动广义类别发现与相关任务的区别 论文链接: https://arxiv.org/abs/2403.04272 代码链接: https://github.com/mashijie1028/ActiveGCD
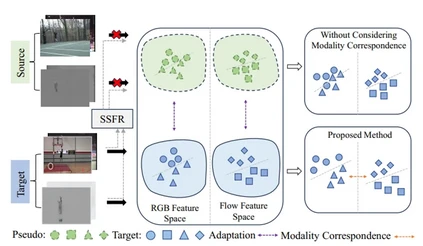
**21. **模态协同测试时自适应动作识别
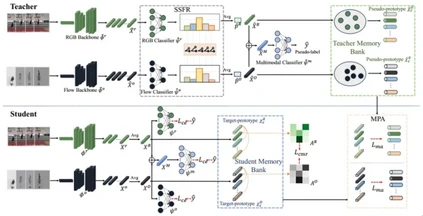
Modality-Collaborative Test-Time Adaptation for Action Recognition 论文作者:熊宝琛、杨小汕、宋亚光、王耀威、徐常胜 基于视频的无监督域自适应方法提高了视频模型的泛化程度,使其能够应用于不同环境下的动作识别任务。然而,这些方法需要在适配过程中持续访问源数据,这在源视频不可用的真实场景中是不切实际的,因为存在传输效率或隐私问题的问题。为了解决这个问题,本文重点介绍了多模态视频测试时自适应(MVTTA)任务。现有的基于图像的TTA方法无法直接应用于这项任务,因为视频在多模态和时序上存在域偏移,这带来了新的困难。为了应对上述挑战,我们提出了一个模态协同测试时间适应(MC-TTA)网络。MC-TTA包含分别用于生成伪原型和目标原型的教师和学生记忆库。在教师模型中,我们提出了自组装源友好特征重建模块(SSFR),以鼓励教师记忆库存储更有可能与源分布一致的特征。通过多模态原型对齐和跨模态相对一致性,我们的方法可以有效缓解视频中的域差异。
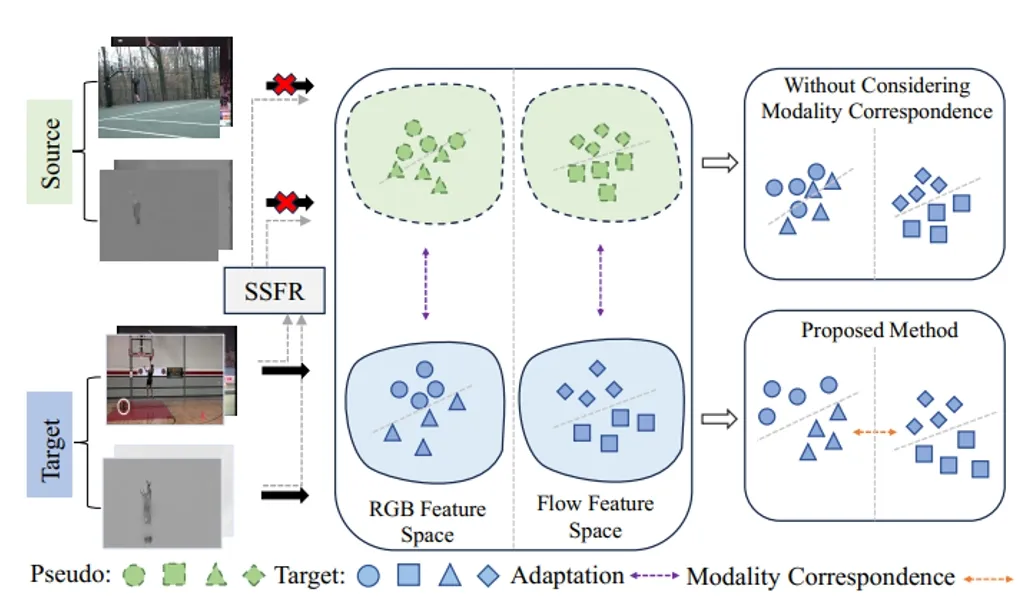
图1 仅有预训练后的源模型和未标记的目标视频才能用于目标模型学习。我们提出自组装源友好型特征重构 (SSFR) 模块,以构建来自目标域的伪源域特征。此外,通过模态协同可以保持易受域偏移影响模态的判别性。
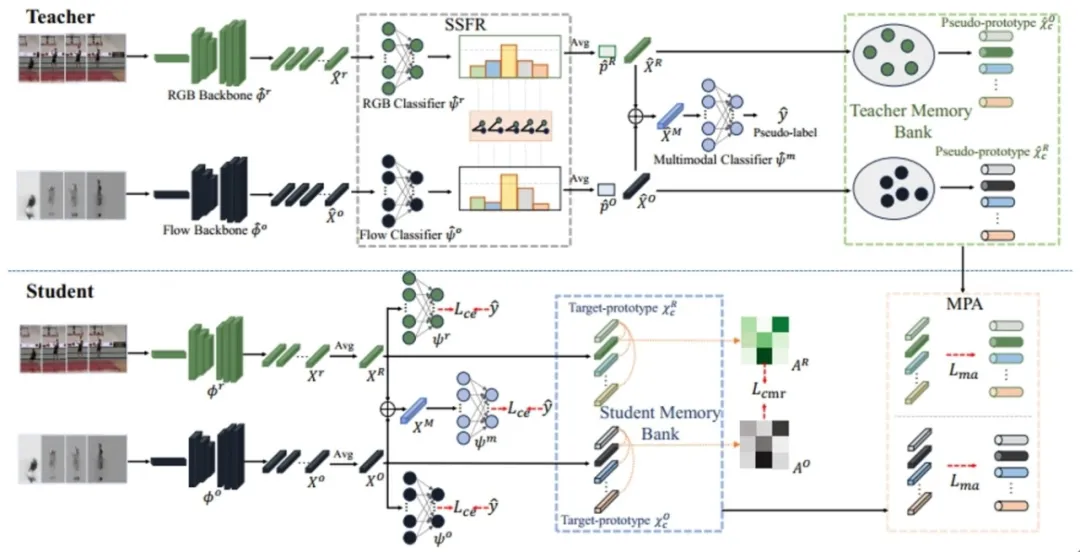
图2 模态协同测试时间适应(MC-TTA)网络
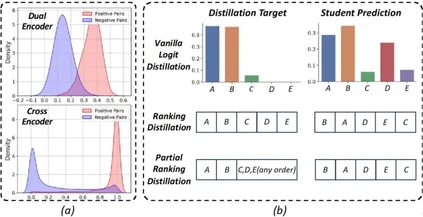
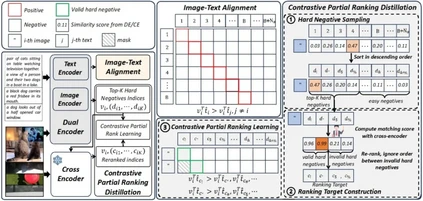
**22. **如何让交互编码器成为高效图文检索的良师?
How to Make Cross Encoder a Good Teacher for Efficient Image-Text Retrieval? 论文作者:陈禹昕、马宗扬、张子琦、祁仲昂、原春锋、李兵、蒲俊福、单瀛、齐晓娟、胡卫明 针对双流预训练结构简单,难以建模丰富图文关联知识的问题,本文提出了一种基于对比式局部排序蒸馏的图像文本预训练方法。预训练蒸馏方法通常使用具有高匹配精度的单流模型作为教师模型,在预训练的过程中指导计算高效的双流模型对丰富图文知识的学习。现有方法通常采用基于相似度分布蒸馏的方式,然而由于单流模型与双流模型之间的相似度分布差异极大,这种方法难以有效实现知识传递。本文采用了一种排序蒸馏的方法,将单流模型对于不同图像文本对的相似度排序作为知识监督,要求双流模型对这些图文对的相似度排序与单流模型保持一致。同时,本文通过分析及实验发现,只有难负样本对之间的相对顺序包含有效的知识,并且蒸馏损失需要与图文对比学习损失保持协调以免产生干扰。因此,本文专注于蒸馏难负样本之间的相对顺序,忽略简单负样本的排序,并通过对比学习的方式实现知识蒸馏目标,实现了知识的有效传递。实验结果表明,本文方法在两个公开图像文本检索数据集MSCOCO和Flickr30K,以及图像文本匹配数据集CrissCrossed Captions数据集上有效提高了双流模型的图文检索和匹配精度,超越了同期的蒸馏方法。
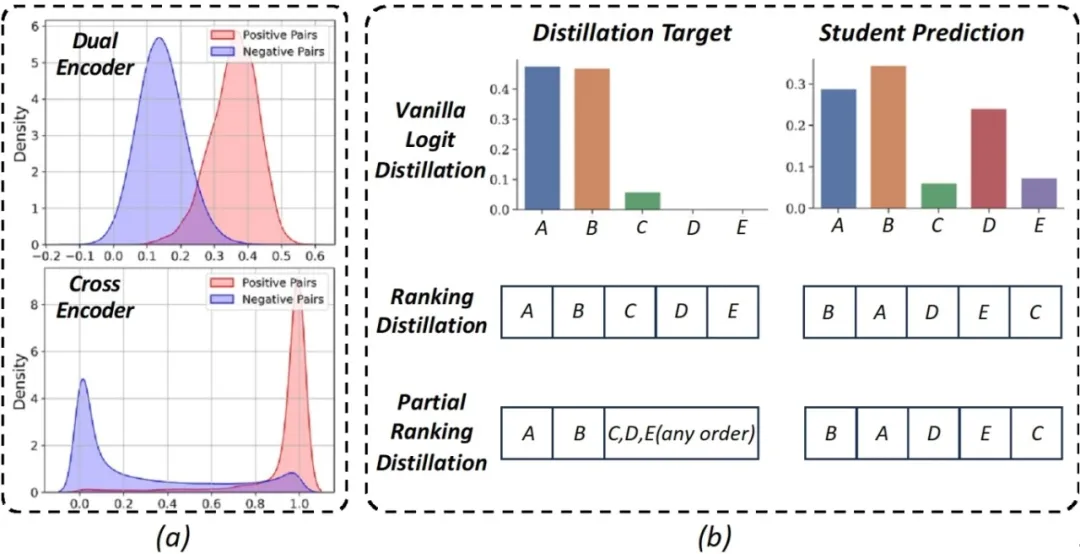
图1.(a)双流编码器与交互编码器的相似度分数分布。(b)不同蒸馏方法的蒸馏目标及学生模型输出结果。对于局部排序蒸馏,简单样本之间的相对顺序被忽略。

图2. 对比式局部排序蒸馏方法示意图。左侧展示了整体训练流程。右侧展示了图文对齐和对比式局部排序蒸馏的详细计算流程。
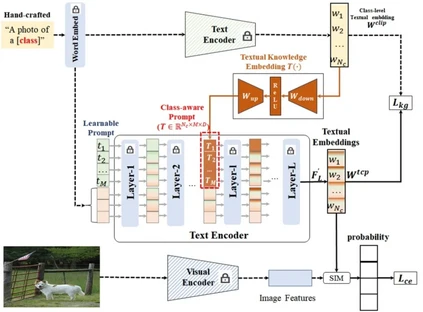
**23. **类别感知提示学习
TCP:Textual-based Class-aware Prompt tuning for Visual-Language Model 论文作者:姚涵涛、张蕊、徐常胜 为了有效的迁移视觉语言模型中包含的百科知识到下游任务,提示学习(Prompt Tuning)被广泛用于新知识的学习。在CLIP中,固定的模板(“a photo of {}”)被用来建模类别的文本空间描述并用于预测。不同于CLIP,基于提示学习的文本优化近来被用于建模新数据的有效类别特征空间。但是,目前的提示学习算法可以概括为域共享的提示学习和图像感知的提示学习,但是这些提示学习算法的文本优化器会过拟合于训练域而在未知测试域上具有较差的性能。为了进一步提升文本编码器生成的分类器的辨别能力和泛化能力,我们提出了类感知提示学习(图1)。由于预训练生成的类别特征具有一定的辨别能力,通过在预训练模型中显式的插入包含类别先验的基于类别特征生成的类别感知提示模板提升的提示学习的泛化性和辨别性。在一系列的数据集上验证了类别感知提示学习在零样本学习、域泛化学习和小样本学习等任务上都取得了很好的性能。另外我们提出的类别感知提示模块具有很好的即插即用性,可以简单高效地融合于提示学习算法。
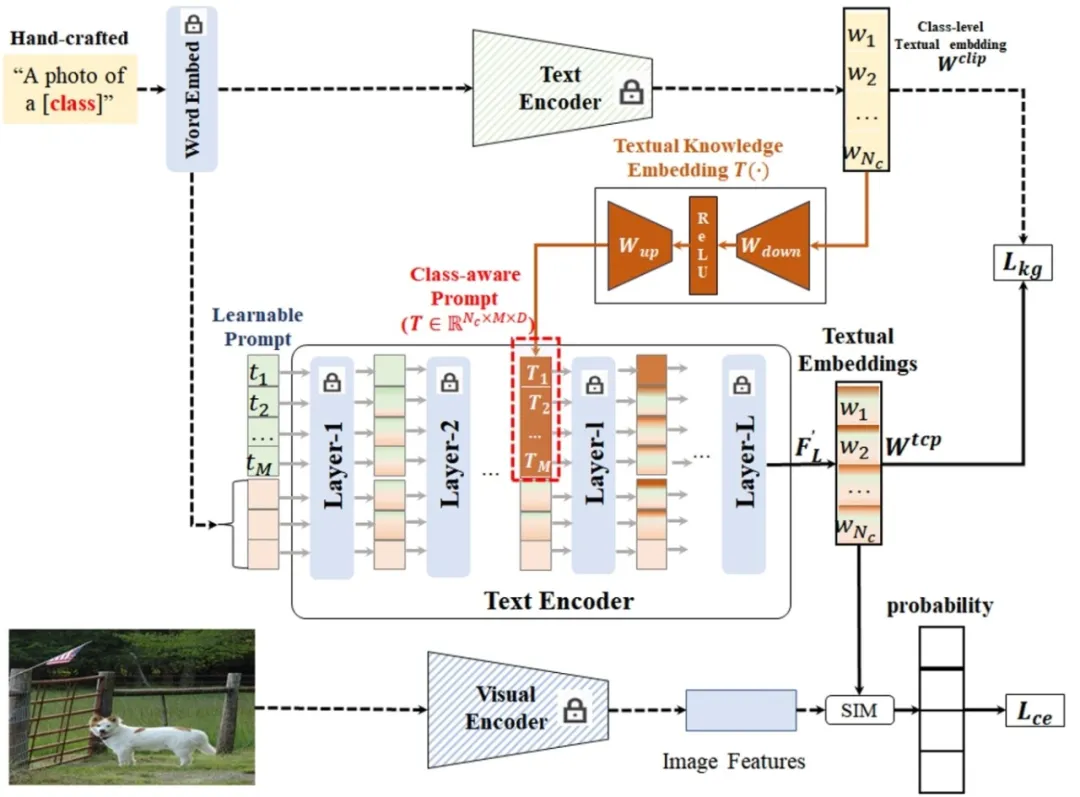
图. 类别感知提示学习的框架 论文链接: https://arxiv.org/abs/2311.18231 代码链接: https://github.com/htyao89/Textual-based_Class-aware_prompt_tuning
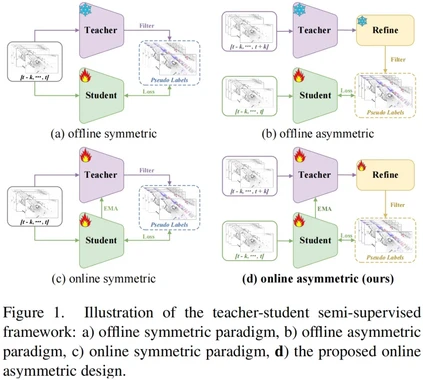
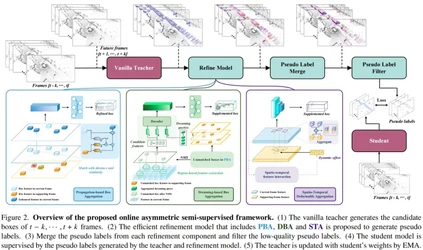
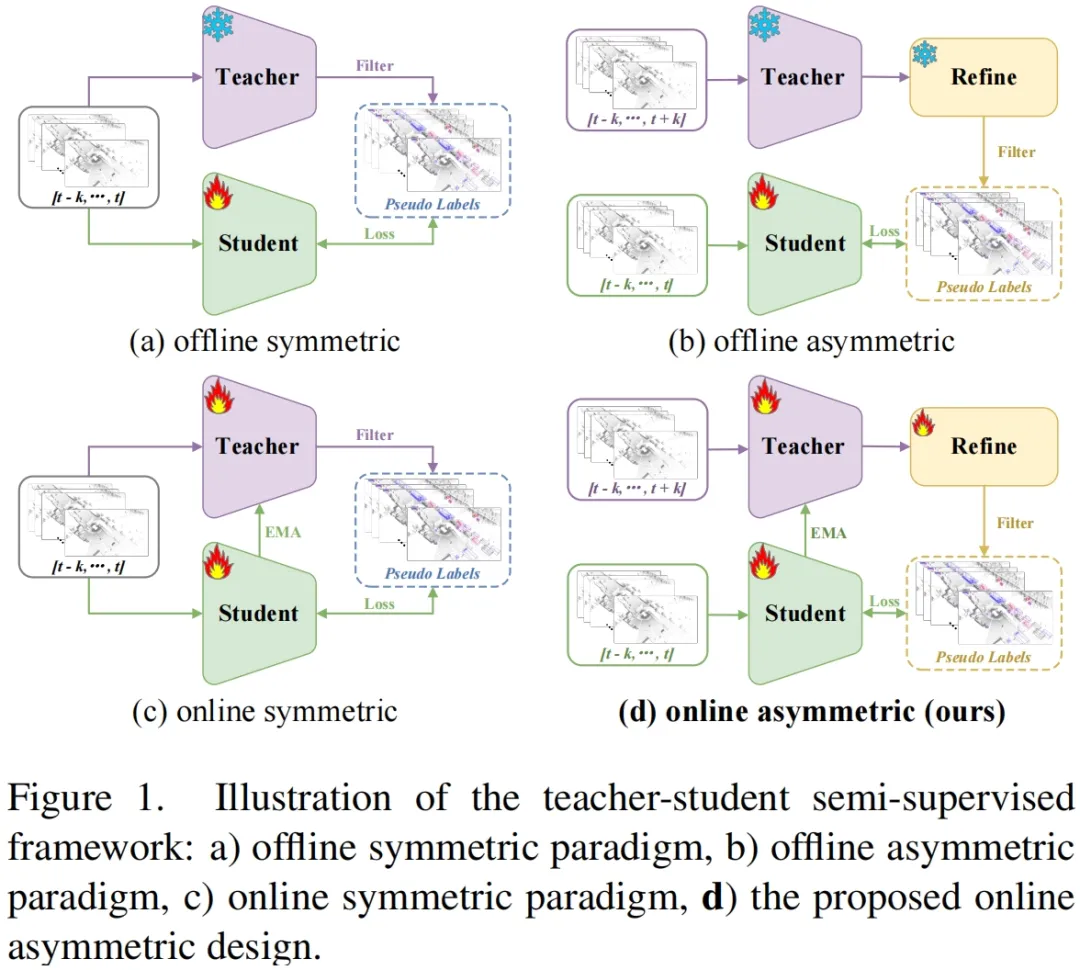
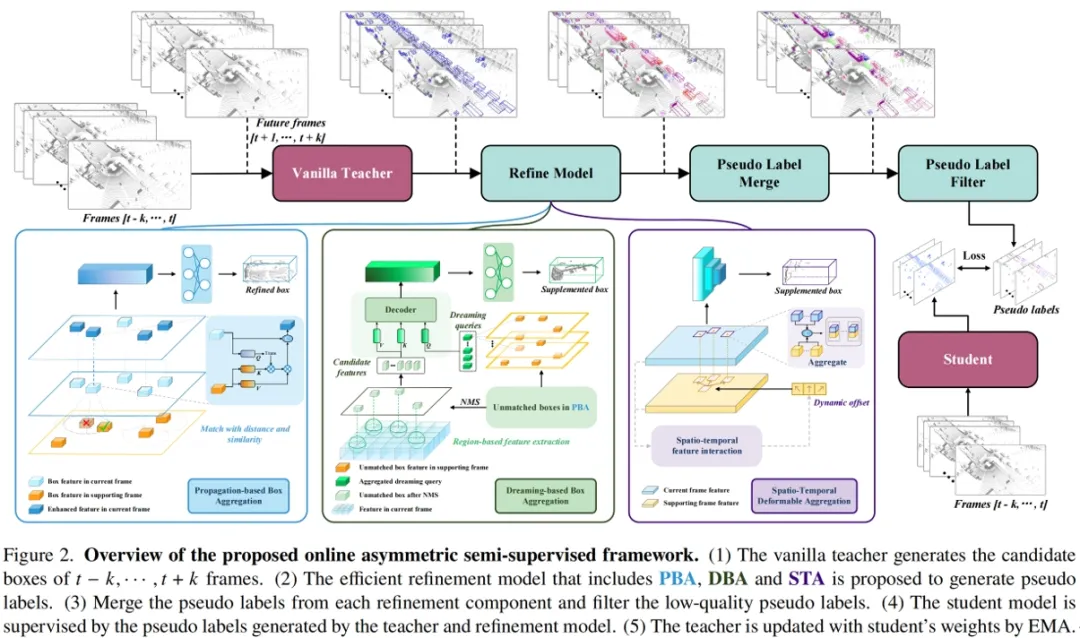
**24. **用于 3D 半监督物体检测的非对称网络
A-Teacher: Asymmetric Network for 3D Semi-Supervised Object Detection 论文作者:王汉石、张志鹏、胡卫明、高晋 本文提出了首个基于LiDAR的3D对象检测的在线非对称半监督框架,即A-Teacher。本文的动机来源于观察到现有的对称教师-学生方法虽简单,但由于要求模型结构和输入数据格式相同,限制了教师与学生之间的知识传递效率。与之相反,复杂的离线非对称方法能生成更精确的伪标签,但共同优化教师和学生模型却具有挑战。因此,我们提出了一种不同的方法,可以利用离线教师的能力同时保留共同更新整个框架的优势,并设计了基于注意力机制的Refine模型,高效处理复杂情况。在Waymo数据集上的实验结果显示,我们的方法在减少训练资源的同时,性能超过了之前的最佳方法。
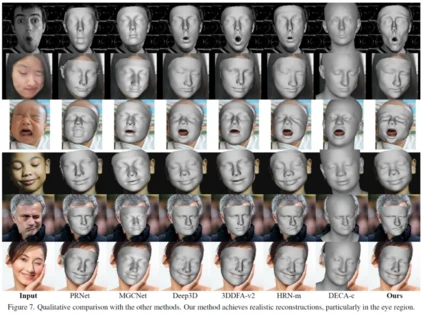
**25. **人脸分割几何信息指导下的三维人脸重建
3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation 论文作者:王子都、朱翔昱、张田硕、王柏钦、雷震 本文面向单目三维人脸重建任务,实现了对人脸极端表情的精确三维重建。我们利用二维人脸分割的几何信息来引导人脸重建,设计了一个强大的几何约束函数。该约束函数首先将人脸部件的分割信息转化为点集,把三维部件形状的拟合问题转化为点集分布的匹配问题。该函数使用一组已知点作为锚点,分别计算锚点与预测点集以及目标点集之间的各种统计距离,并通过减少这些距离的差异来确保预测点集和目标点集具有相同的几何覆盖区域。大量的定量和定性实验证明了我们方法的有效性,它可以非常准确地捕捉不对称和奇怪的面部表情。此外,我们还合成了一个包含皱眉、歪嘴、闭眼等极端表情的人脸数据集,以促进相关研究。
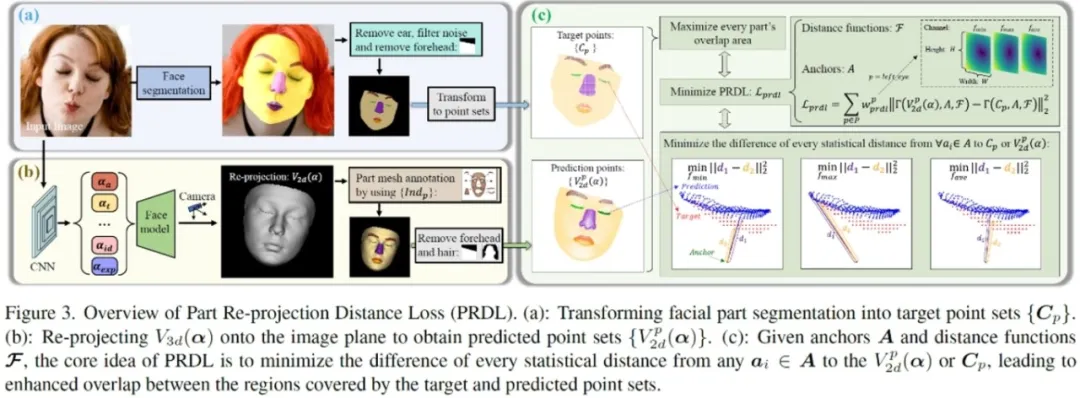
图1. 方法的主要流程图
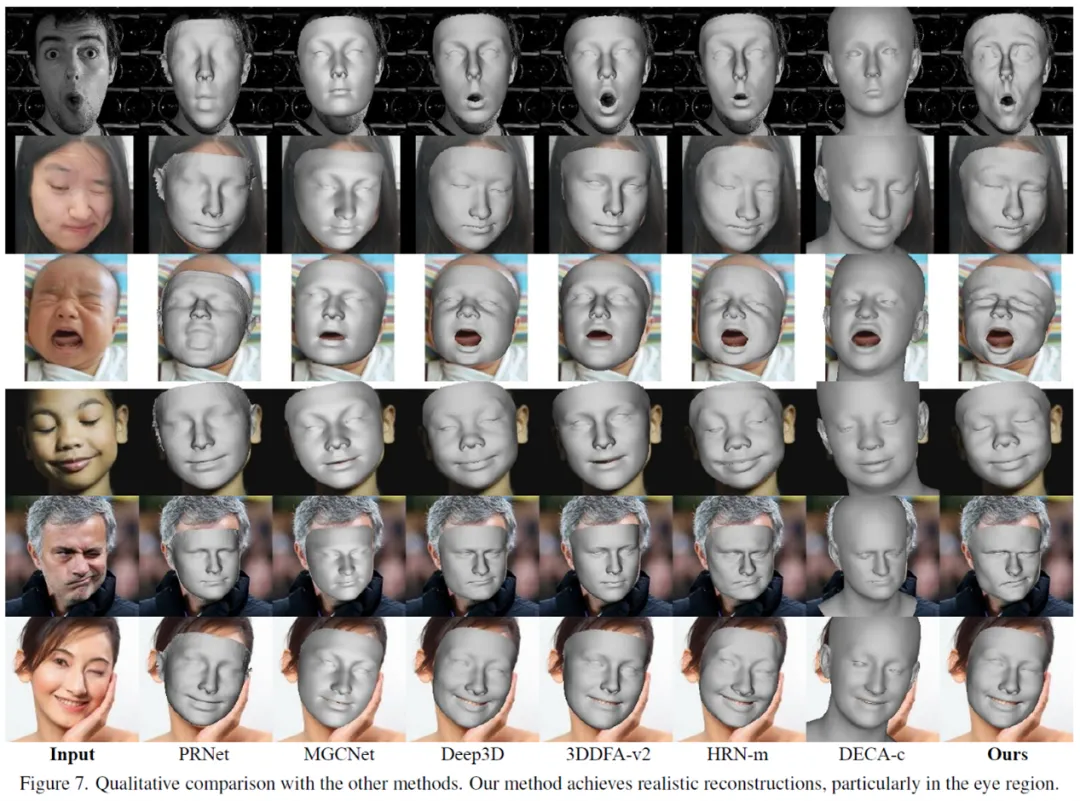
图2. 与其他SOTA方法进行定性比较。 论文链接: https://arxiv.org/abs/2312.00311 代码链接: https://github.com/wang-zidu/3DDFA_V3
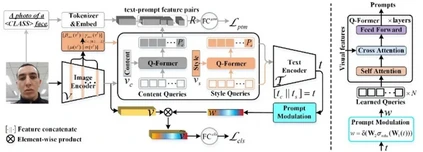
**26. **基于免类别提示学习的域泛化人脸活体检测
CFPL-FAS: Class Free Prompt Learning for Generalizable Face Anti-spoofing 论文作者:刘阿建、薛帅、甘剑文、万军、梁延研、邓健康、Sergio Escalera、雷震 在基于领域泛化(DG)的面部反欺诈(FAS)领域中,传统方法常依赖于领域标签来对齐不变的特征空间,或是从整体样本中分离出可泛化的特征,这两种方式都可能导致语义特征结构的扭曲,从而限制了模型的泛化能力。本工作针对现有基于域泛化的人脸防伪模型存在的泛化性能不足问题,设计了一种新型的免类别提示学习(CFPL)方法。该方法不直接操作视觉特征,而是利用大规模视觉语言模型(如CLIP)和文本特征,动态调整分类器的权重,以探索可泛化的视觉特征。CFPL通过两个轻量级变换器内容Q-Former(CQF)和风格Q-Former(SQF),利用一组可学习的查询向量,分别根据内容和风格特征学习不同的语义提示。通过引入提示文本匹配(PTM)监督和多样化风格提示(DSP)技术,进一步提升了模型的泛化能力。学到的文本特征通过设计的提示调制(PM)机制来调节视觉特征,以实现泛化。最终在多个数据集上达到了优于现有先进算法的性能。
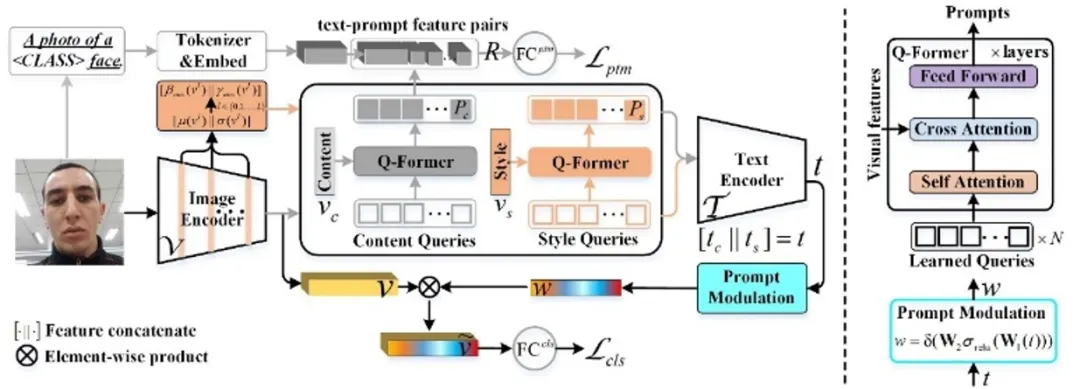
图. 基于免类别提示学习的域泛化人脸活体检测框架
**27. **基于密度引导和双空间困难采样的3D半监督语义分割
Density-guided Semi-supervised 3D Semantic Segmentation with Dual-space Hardness Sampling 论文作者:李嘉楠,董秋雷 现有的3D半监督语义分割通常使用点对点的对比学习,但这种技术容易受到外点影响,为解决该问题,我们提出了DDSemi。其中,DDSemi使用密度引导的点对锚的对比学习。考虑到聚类中心通常位于密度较大的区域,我们使用特征存储体中密度较大的特征来为每个类别估计一个锚向量。为了从无标签数据中挖掘出有效信息,我们使用不同的数据增强技术处理不同分支中的无标签点云,并分别计算分支内的点对锚对比损失和分支间的点对锚对比损失。除此之外,为了给位于密度较低区域的点更多的关注,我们提出了双空间困难采样技术,该技术能够基于每个点在几何空间和特征空间中的密度为其赋予不同的损失权重。在室内和室外的公开数据集中的分割结果表明DDSemi的性能超过了现有的3D半监督语义分割方法。
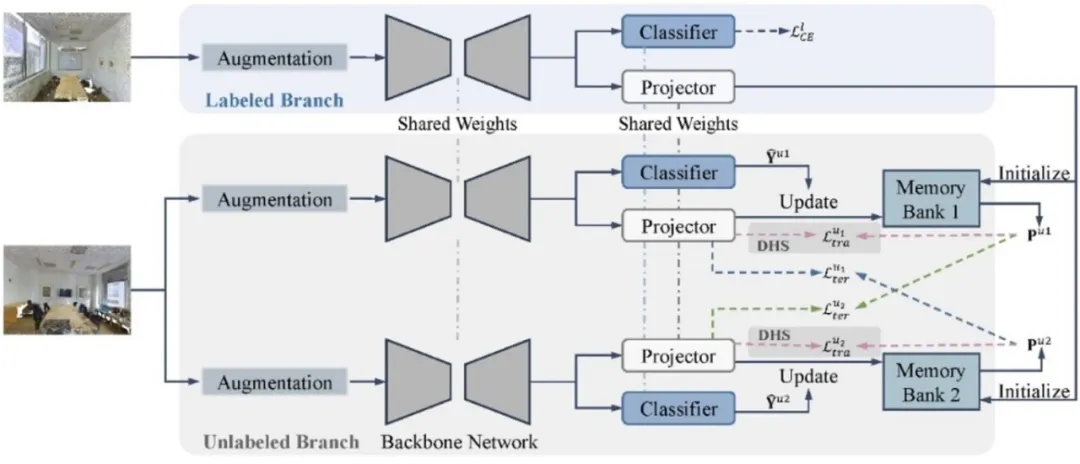
图. DDSemi的结构图
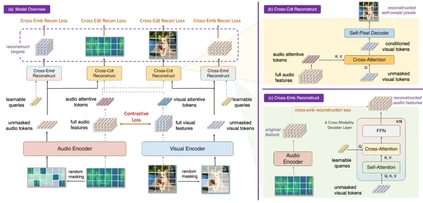
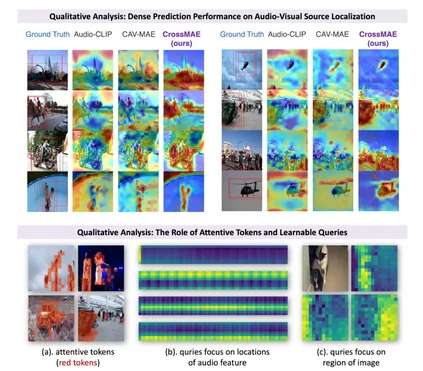
**28. **CrossMAE: 基于MAE的跨模态区域感知视听预训练模型
CrossMAE: Cross-Modality Masked Autoencoders for Region-Aware Audio-Visual Pre-Training
论文作者:郭雨欣、孙思洋、马帅磊、郑可成、包笑一、马时杰、邹伟、郑赟 模态对齐的表征是视听学习中不可或缺的部分,然而现有视听预训练方法仅关注了全局特征以及分类或检索任务,忽略了细粒度特征的交互和对齐,导致下游密集预测任务出现次优性能。针对上述问题,我们研究了可局部区域感知的视听预训练,提出具有出色的跨模态交互和局部区域对齐能力的通用视听预训练模型:CrossMAE。具体来说,我们提出了像素级和特征级两个难度递进的MAE子任务。以视觉模态为例(反之亦然),首先,被随机掩码的视觉模态在听觉模态的attentive tokens的指导下重建图像像素,从而有效关注细粒度特征并促进区域感知能力;进一步地,视觉模态在可学习learnable queries的指导下重建听觉模态的完整特征,从而有效加强模态间交互。实验表明,CrossMAE能够在分类,检索,定位,分割,事件定位等多个任务上均取得SOTA性能,证明了所提出预训练模型的有效性。同时,我们探究了模态交互及局部区域对齐对于单模态和跨模态表征能力的提升,并深入分析了所提出的attentive tokens和learnable queries具体的作用机理,证明了本模型的有效性。
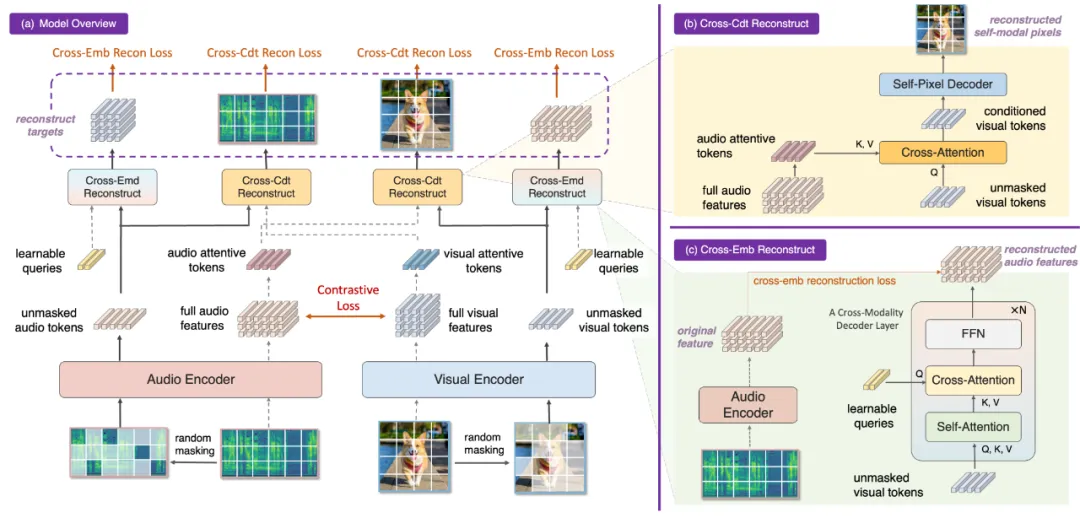
图1. CrossMAE框架图
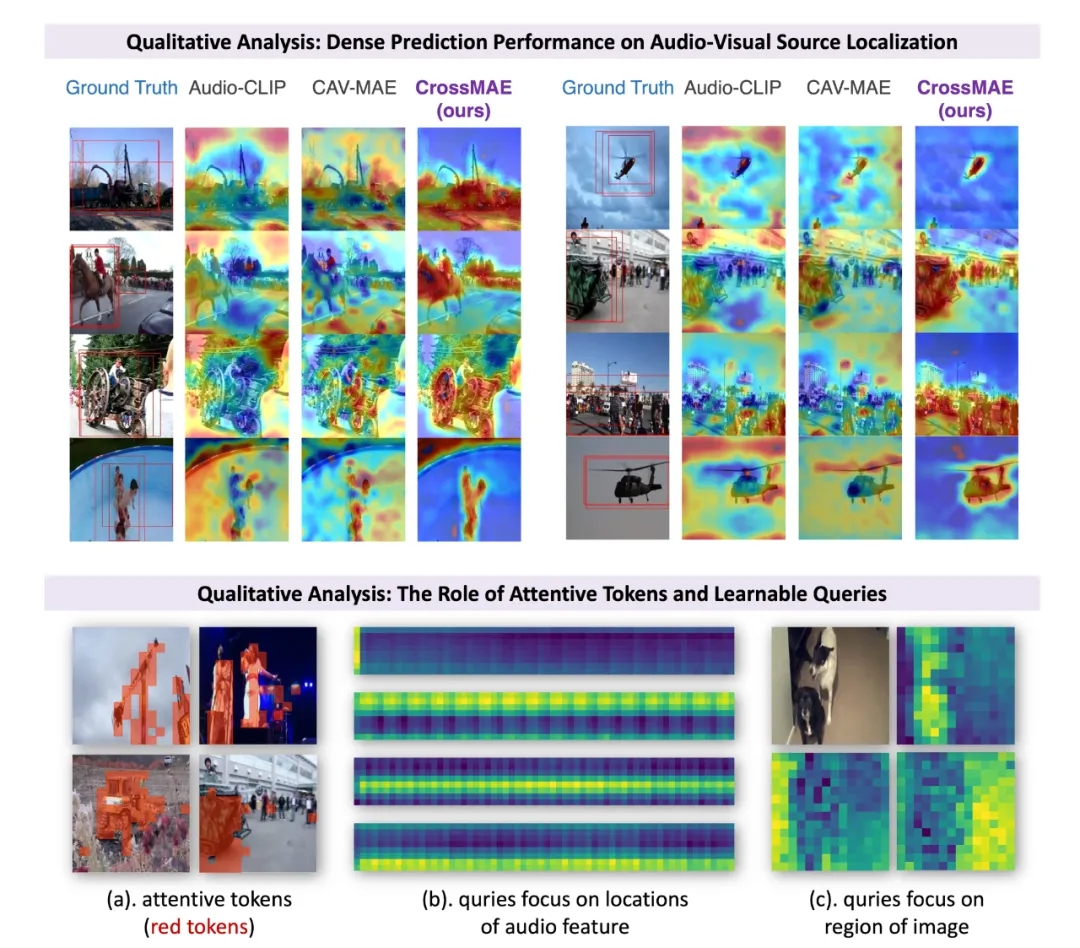
图2. 定性分析图
**29. **开放场景自监督学习
Self-Supervised Representation Learning from Arbitrary Scenarios 论文作者:李朝闻、朱优松、陈志扬、高宗鑫、赵瑞、赵朝阳、唐明、王金桥 当前,自监督方法主要分为对比学习和掩码图像模型两大类。目前性能最强大的自监督模型正是组合这两种方法所构建的。然而,本文指出,组合方法本质上加强了全局一致性,却没有考虑对比学习和掩码图像模型之间的潜在冲突,这严重影响了它们在开放场景下的学习能力。本文从理论上证实了掩码图像模型实质上是一种基于区域级别的对比学习方法,图像中的每个区域被视为一个不同的类别。这与全局级别的对比学习形成了显著的冲突,后者将图像中的所有区域视为相同的类别。 为了解决这一冲突,本文放弃了全局性约束,并提出了一种显式的区域性学习解决方案。具体来说,本文提出的技术在训练阶段采用了一种区域特征增强策略来构建解码双分支学习方案。这种学习方案使模型能够从开放场景中提取非同质化的特征表示,解决了组合方法中的学习冲突。通过在多个公开和混合数据集上的实验,本文证明了其在开放场景下的学习能力。
**30. **SC-Tune:解锁视觉语言模型的自洽指代理解能力
SC-Tune: Unleashing Self-Consistent Referential Comprehension in Large Vision Language Models 论文作者:岳同天、程杰、郭龙腾、戴星原、赵子嘉、何兴建、熊刚、吕宜生、刘静 当前大型视觉语言模型的研究日益聚焦于超越通用图像理解,朝向更细致的、目标级别的指代性理解。在本文中,我们提出并深入探讨了大型视觉语言模型的自恰性。这反映在模型具备既能为特定目标生成准确详细的描述,又能利用这些描述准确地重新定位原始目标的“闭环”式能力。该能力在很大程度上反映了模型细粒度视觉-语言理解的精确性和可靠性。然而先期实验表明,现有模型的自恰性水平未能达到预期,极大限制了它们的实际应用性和潜力。为了解决这一差距,我们引入了一种新颖的微调范式SC-Tune。它实现了模型描述-定位能力的循环式互促学习。这一范式不仅数据高效,而且在多个模型上展现了广泛的泛化能力。实验表明,SC-Tune显著提升了基线模型在一系列目标级视觉-语言基准测试中的性能,并在图像级视觉-语言基准测试中同样具备性能改善。
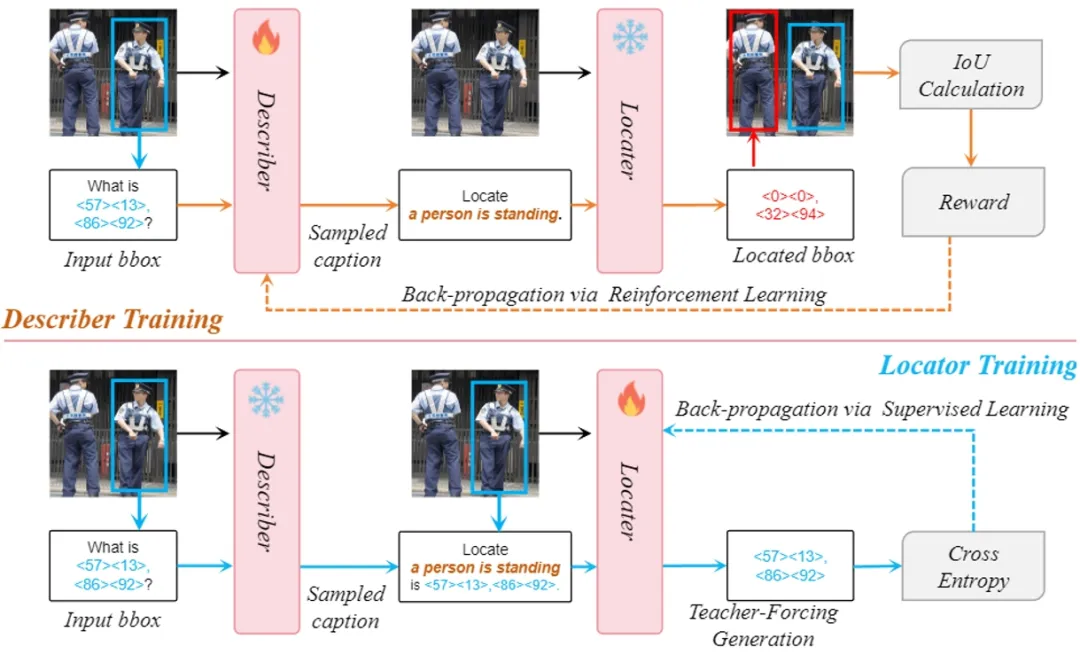
图. SC-Tune训练框架
**31. **联合目标及其部件的精细粒度指代分割
Unveiling Parts Beyond Objects: Towards Finer-Granularity Referring Expression Segmentation 论文作者:王文轩、岳同天、张毅思、郭龙腾、何兴建、王鑫龙、刘静 指代分割任务(RES)旨在分割与描述性自然语言表达相匹配的前景实体掩膜。以往的数据集和经典的指代分割方法严重依赖于一个假设,即一条文本表达必须指向对象级目标。在本文中,我们进一步深入探索更细粒度的部件级指代分割任务。为了推动对象级指代分割任务朝着更细粒度的视觉语言理解发展,我们提出了一个全新的多粒度指代分割(MRES)任务,并通过手工注释的方式构建了一个名为RefCOCOm的评估基准。通过使用我们搭建的模型辅助的自动数据生成引擎,我们构建了迄今为止最大的视觉定位数据集,即MRES-32M,它包含提供的100万图像上的超过3220万个高质量视觉掩膜和相应的文本描述。此外,我们设计了一个简单而强大的基线模型UniRES,用以完成统一的对象级和部件级视觉定位任务。在我们的RefCOCOm上针对MRES任务的广泛实验以及三个经典RES任务的数据集(即RefCOCO、RefCOCO+和RefCOCOg)上的实验,证明了我们的方法相较于以往最先进方法的优越性。
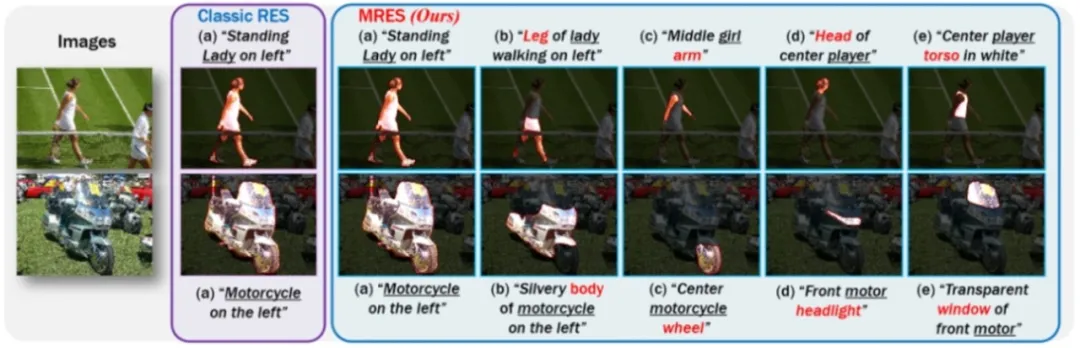
图1. 经典的指代分割任务(RES)仅支持表示单一目标对象的自然语言表达,例如(a)。与经典RES相比,我们提出的联合目标及其部件的多粒度指代分割任务(MRES)支持表示目标对象的特定部分级区域的自然语言表达,例如,我们新构建的RefCOCOm基准测试集中的部分级自然语言表达(b)到(e)。 
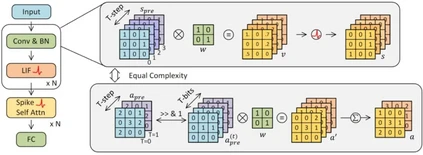
**32. **传统的 SNN 真的高效吗?从模型量化的视角出发
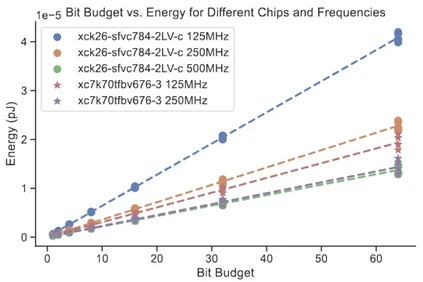
Are Conventional SNNs Really Efficient? A Perspective from Network Quantization 论文作者:申国斌、赵东城、李腾龙、李金东、曾毅 脉冲神经网络(SNN)以其事件驱动特性而闻名,展示出高能效和巨大的发展潜力。然而,对SNN与量化人工神经网络(QANN)进行深入的比较和相关性研究仍然不足,导致对这两者的评估可能缺乏公平性。我们引入了一种新的视角,发现SNN中的时间步长与QANN中激活值的量化位宽有着相似的表征特性。基于此,我们提出了一种更加实用和精确的方法来计算SNN的能量消耗。我们推出的“比特预算”(Bit Budget)概念,不同于传统的突触操作(SynOps),使我们能够在严格的硬件限制下深入探讨如何在权重、激活值和时间步长之间进行合理的计算和存储资源分配。在“比特预算”指导下,我们认识到对SNN而言,关注脉冲模式和权重量化比时间步长更能显著影响模型性能。利用比特预算进行SNNs的综合设计,可提升模型在不同数据类型(包括静态图像和神经形态数据集)中的性能。我们的研究不仅加深了对SNN与量化ANN之间相互关系的理解,也为未来高效能神经计算领域的探索指明了方向。
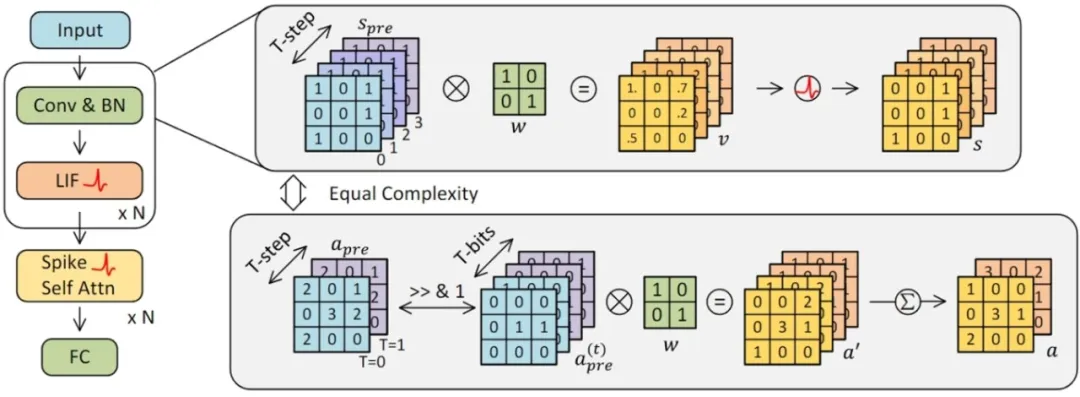
图1. 具有相同数量的特征位时,SNN 和量化 ANN 具有相同的复杂度的表示

图2. 在不同的FPGA平台和设置下, 单个突触操作的比特预算与能量消耗的关系
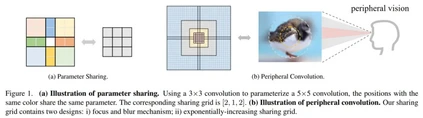
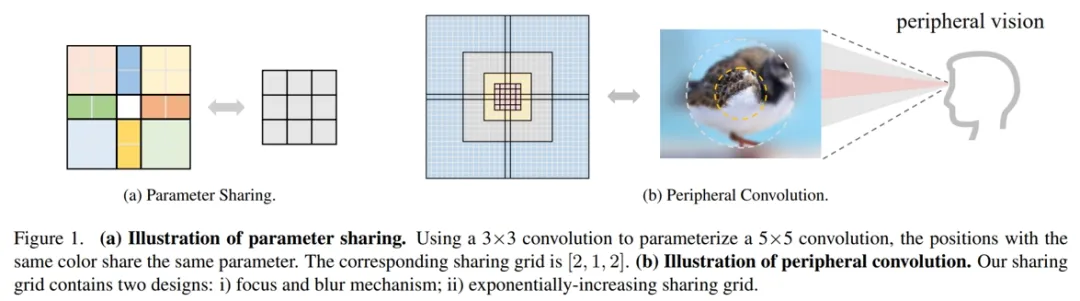
**33. **PeLK: 参数高效的大核外围卷积网络
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution 论文作者:陈宏昊、初祥祥、任泳健、赵鑫、黄凯奇 近期,一些大核卷积神经网络以其优异的性能和效率卷土重来。然而,考虑到卷积的平方复杂度,直接扩大卷积核会产生大量的参数,而急剧增长的参数会导致严重的优化问题。由于这些问题,目前的CNN妥协于以条形卷积的形式扩展到51×51(即51×5+5×51),并随着内核大小的持续增长性能开始饱和。在本文中,我们深入研究了这些关键问题,并探讨是否可以继续扩展内核以获得更多性能提升。受人类视觉的启发,我们提出了一种类似人类的外围卷积,通过参数共享有效地减少了密集网格卷积90%以上的参数计数,并将卷积核大小扩展到非常大。我们的外围卷积的特征与人类非常相似,将卷积的复杂度从O(K^2)降低到O(logK)而不会影响精度。在此基础上,我们提出了参数高效的大核网络(PeLK)。我们的PeLK在各种视觉任务上优于现代视觉Transformer和ConvNet架构,如Swin, ConvNeXt, RepLKNet和SLaK,包括ImageNet分类,ADE20K上的语义分割和MS COCO上的目标检测。我们第一次成功地将CNN的内核大小扩展到前所未有的101×101,并展示了持续的改进。
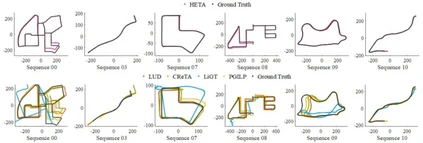
**34. **重新审视融合特征轨迹的全局式相机平移估计方法
Revisiting Global Translation Estimation with Feature Tracks
论文作者:陶沛霖、崔海楠、荣梦琪、申抒含 全局式相机平移估计是全局式运动恢复结构算法中极具挑战性的一步。绝大部分传统方法仅依赖于相机间相对平移作为输入,导致在低视差或相机共线运动场景下的相机位置估计出现退化问题。虽然一些方法通过融合特征点轨迹来缓解这些问题,但它们通常对异常值非常敏感。在本文中,我们首先回顾了已有利用特征点轨迹的全局式相机平移估计方法,并将其分为显式和隐式方法两类。然后,我们提出并分析了基于叉乘度量的目标函数的优越性,并提出了一种以相机相对平移和特征点轨迹同时作为输入的显式全局式相机平移估计新框架。另外,为了提高系统输入的准确性,我们使用极平面的共面性约束重新估计两视图相对平移,并提出一种简单而有效的策略来挑选可靠的特征点轨迹。通过在街景视频序列和无序互联网图像数据集上测试,并与许多最先进的技术相比,我们的方法展示了卓越的准确性和鲁棒性。
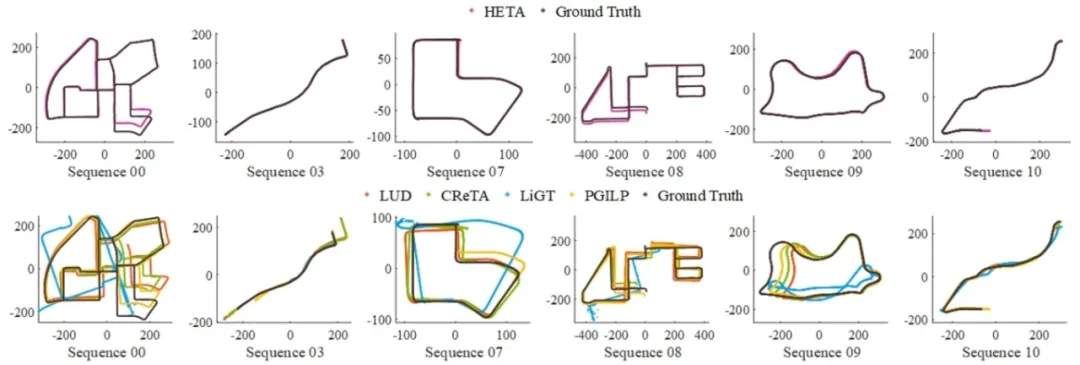
图. 该图展示了在自动驾驶数据集KITTI上,我们的方法HETA和其他SOTA方法估计的相机轨迹与真实相机轨迹对比。通过标定轨迹可以看出我们方法的准确性明显由于传统方法。其中,对比SOTA方法LUD发表于CVPR 2015,CReTA发表于ECCV 2022,LiGT发表于IEEE TPAMI 2021,PGILP发表于RAL 2019。
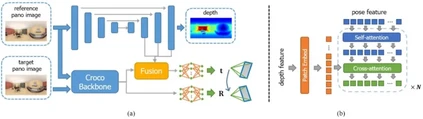
**35. **PanoPose:自监督全景图像相对位姿估计
PanoPose: Self-supervised Relative Pose Estimation for Panoramic Images 论文作者:屠殿韬、崔海楠、郑先伟、申抒含 在全局式从运动恢复结构(SfM)中,一个主要难点是估计具有尺度的相对位姿,即两张图像之间的相对旋转和具有尺度的相对平移。这个问题是由于传统的几何视觉方法(例如五点法)得到的相对平移是无尺度的。目前绝大部分方法都是在绝对位姿估计阶段解决该问题,而我们则考虑在相对位姿估计阶段解决。所以,我们提出了PanoPose,以完全自监督的方式估计有尺度的相对运动,并为全景图像构建了一个完整的全局式 SfM 流程。PanoPose 包含一个深度网络和一个位姿网络,通过估计的深度和相对位姿从相邻图像重建参考图像来实现自监督。为了提升大视角变换下位姿估计的精度,我们提出了一种纯旋转预训练策略。为了提升相对平移尺度的精度,我们使用一个融合模块将深度信息引入位姿估计中。
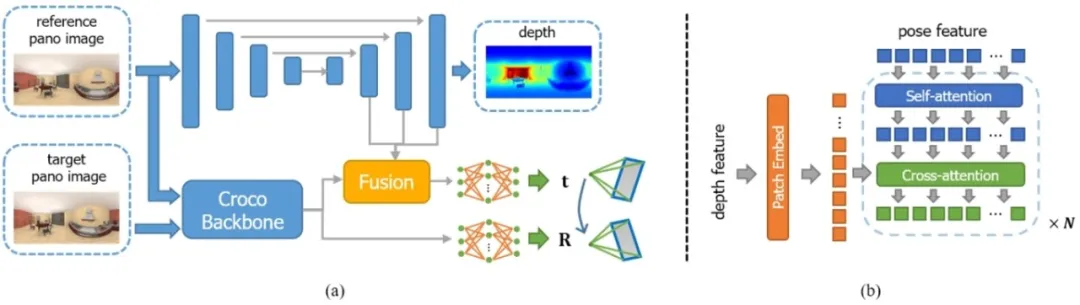
图1. (a)PanoPose的整体网络结构。(b)我们提出的融合模块的具体结构。
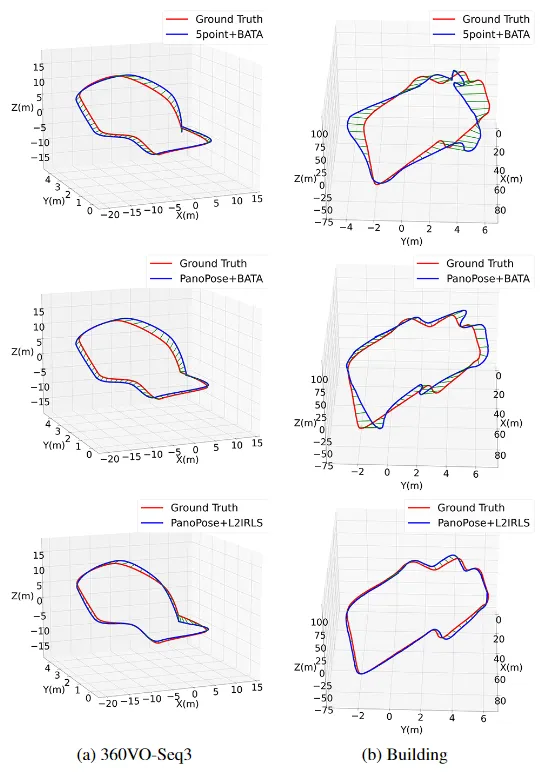
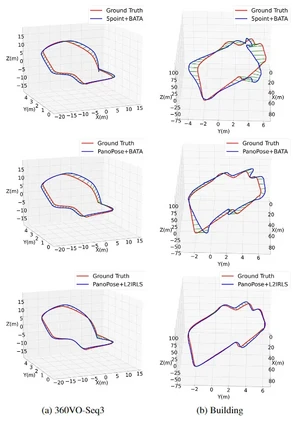
图2:在不同数据集上绝对位姿估计结果。红色轨迹是位姿的真值,蓝色的轨迹是位姿的估计值。第一行是五点法和BATA得到的结果。第二行是PanoPose和BATA的结果。第三行是PanoPose和L2IRLS的结果。
**36. **基于无监督聚类分析的免对应非刚体点集配准
Correspondence-Free Non-Rigid Point Set Registration Using Unsupervised Clustering Analysis 论文作者:赵明阳、江敬恩、马雷、辛士庆、孟高峰、严冬明本文提出了一种受无监督聚类分析启发的非刚性点集配准范式。不同于此前方法,将源点集和目标点集视作两个独立部分,本文采用整体框架,将它们分别建模为聚类中心和聚类成员,从而将点集配准过程转化为无监督聚类优化问题。为确保位移场的光滑性和鲁棒性,本文分别采用Tikhonov正则化和L1范数诱导的拉普拉斯核来约束和刻画位移场。可以证明,本文方法具有闭形式解,不依赖空间维数且可处理大形变。进一步,本文采用聚类诱导的Nyström低秩逼近算法,将Gram矩阵的计算和存储复杂性显著降低到线性,同时,本文为低秩近似结果给出了严格的理论误差界。实验表面,本文方法在各种标准数据集上都取得了最优性能,特别是对于大形变的物体。此外,本文还展示了所提出的方法在挑战性形状分析任务中的应用,包括医学数据配准和形状迁移。