

无条件生成——在不依赖人工标注标签的情况下建模数据分布——是生成模型中一个长期存在的基本挑战,具备从大规模未标记数据中学习的潜力。在文献中,无条件方法的生成质量远不如其条件对应方法。这一差距可以归因于标签提供的语义信息的缺乏。在本研究中,我们展示了通过在自监督编码器生成的表征空间中生成语义表征,可以缩小这一差距。这些表征可用于为图像生成器提供条件。该框架称为表征条件生成(RCG),为无条件生成问题提供了一种有效的解决方案,无需使用标签。通过全面的实验,我们观察到 RCG 显著提高了无条件生成质量:例如,它在 ImageNet 256×256 上达到了新的最先进的 FID 值 2.15,相较于之前最佳的 5.91 大幅降低了 64%。我们的无条件结果与领先的类条件结果处于同一层级。我们希望这些鼓舞人心的观察能引起社区对无条件生成这一基本问题的关注。代码可在 https://github.com/LTH14/rcg 获取。
生成模型在历史上作为无监督学习方法得到了长时间的发展,例如,开创性的工作包括 GAN [27]、VAE [39] 和扩散模型 [57]。这些基本方法专注于学习数据的概率分布,而不依赖于人类注释的可用性。这个问题,通常被今天的社区归类为无条件生成,旨在利用大量未标注数据学习复杂的分布。
然而,与其条件对应方法相比,无条件图像生成在很大程度上停滞不前。最近的研究 [18, 54, 10, 11, 24, 50] 在依赖人类提供的类别标签或文本描述时展示了引人注目的图像生成质量,但在没有这些条件的情况下,其质量显著下降。缩小无条件生成和条件生成之间的差距是一个具有挑战性且科学价值的问题:这是释放大规模未标注数据潜力的必要步骤,这也是今天深度学习社区的共同目标。
我们假设这种性能差距的原因在于人类注释的条件引入了丰富的语义信息,从而简化了生成过程。在本研究中,我们通过借鉴一个密切相关的领域——无监督/自监督学习,来大幅缩小这一差距。我们观察到,强大的自监督编码器(例如 [30, 12, 8, 14])生成的表征可以在没有人类监督的情况下捕捉到许多语义属性,这在文献中的迁移学习表现中得到了体现。这些自监督表征可以作为一种条件形式,而不会违反无条件生成的无监督特性,从而创造出摆脱对人工注释标签的重度依赖的机会。
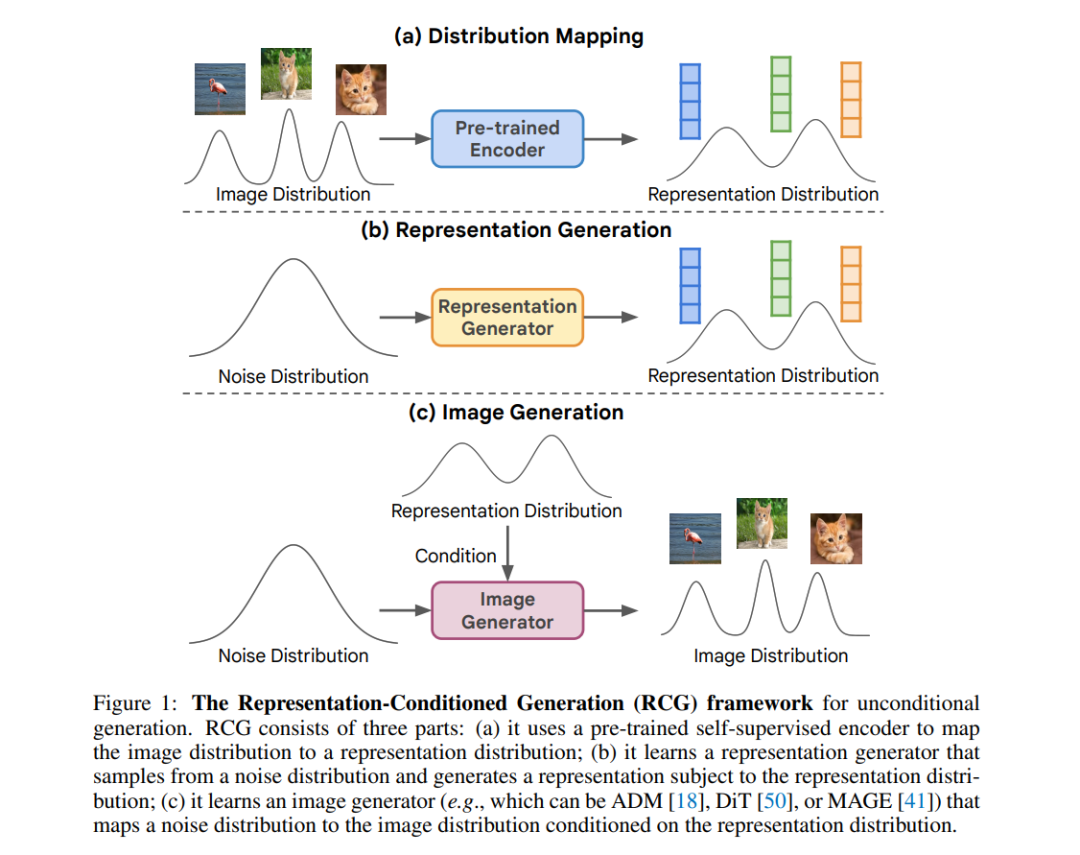
基于这一观察,我们提出首先无条件生成自监督表征,然后基于该表征生成图像。作为预处理步骤(图 1a),我们使用一个预训练的自监督编码器(例如 MoCo [14])将图像分布映射到相应的表征分布。在这个表征空间中,我们训练一个没有任何条件的表征生成器(图 1b)。由于这个空间是低维且紧凑的 [65],学习表征分布通过无条件生成变得可行。在实践中,我们将其实现为一个非常轻量的扩散模型。给定这个表征空间,我们训练第二个生成器,该生成器以这些表征为条件并生成图像(图 1c)。这个图像生成器在概念上可以是任何图像生成模型。整体框架称为表征条件生成(RCG),为无条件生成提供了一种新范式。
RCG 在概念上简单灵活,但在无条件生成方面却极为有效。无论具体选择哪个图像生成器,RCG 都显著提高了无条件生成质量(图 2),分别将 LDM-8、ADM、DiT-XL/2 和 MAGE-L 的 FID 降低了 71%、76%、82% 和 51%。这表明 RCG 在很大程度上减少了当前生成模型对人工标签的依赖。在具有挑战性的 ImageNet 256×256 基准上,RCG 实现了无条件生成前所未有的 2.15 FID。这一性能不仅显著优于之前的无条件方法,更令人惊讶的是,它能够赶上以类别标签为条件的强大领先方法。我们希望我们的方法和鼓舞人心的结果能重新点燃社区对无条件生成这一基本问题的兴趣。