

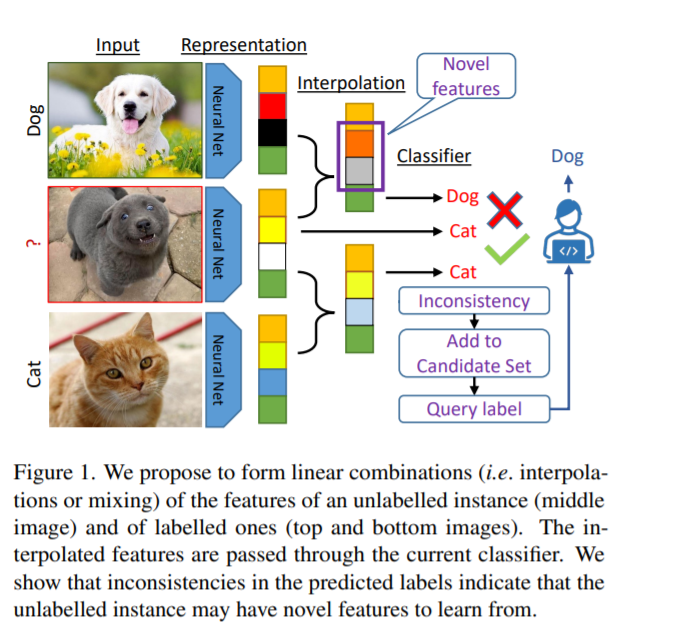
主动学习(AL)的前景是通过从一组未标记的数据中选择最有价值的例子进行注释来降低标签成本。在高维数据(如图像、视频)和低数据状态下,识别这些样例尤其具有挑战性**。在本文中,我们提出了一种新的批量主动学习的方法,称为ALFA-Mix**.我们通过寻找对其表征的干预所导致的预测的不一致性,来识别具有足够明显特征的未标记实例。我们在带标签和未带标签的实例之间构建插值,然后检查预测的标签。我们表明,这些预测中的不一致性有助于发现模型在未标记的实例中无法识别的特征。我们推导了一个有效的实现基于一个封闭的解决方案的最优插值引起变化的预测。我们的方法在图像、视频和非视觉数据的12个基准上,在30种不同的设置下,比最近所有的人工智能方法表现都好。这种改进在低数据状态下和自训练的视觉transformers上尤为显著,其中ALFA-Mix在试验中分别有59%和43%的表现优于目前的先进水平。
https://arxiv.org/abs/2203.07034
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年4月15日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日