随着 ChatGPT 等基于大模型的产品展现出强大的通用性能,学术界和工业界正积极探索如何 将这些模型适配到特定行业和应用场景中,即进行垂直领域大模型的定制化。然而,现有的通用大模 型可能无法完全适配特定领域数据的格式,或不足以捕捉该领域的独特需求。因此,本文旨在探讨垂 直领域大模型定制化的方法论,包括大模型的定义和类别、通用架构的描述、大模型有效性背后的理论 基础,以及几种可行的垂直领域大模型构建方法,期望通过这些内容为相关领域的研究者和从业者在 垂直领域大模型定制化方面提供指导和参考。
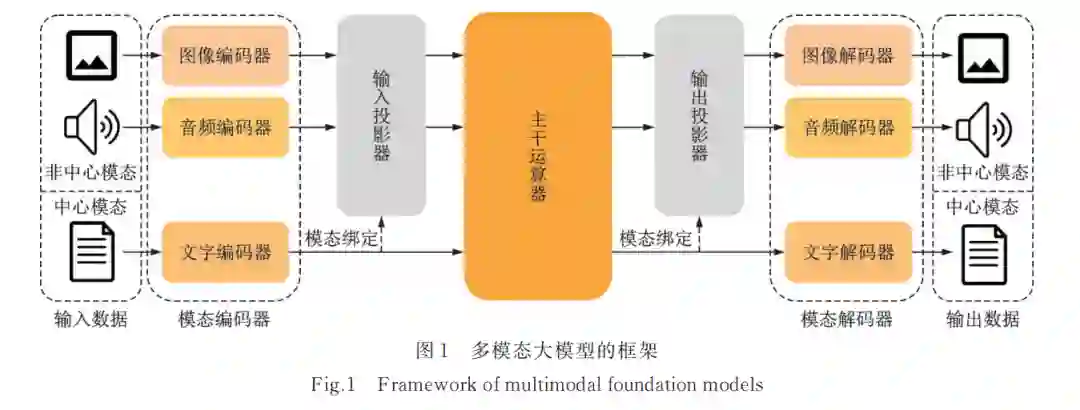
ChatGPT 以其卓越的通用性能重塑了人们对人工智能的理解。作为 ChatGPT 的核心,大语言模 型(Large language model)已经成为众多领域研究人员和专业人士改进工作流程的重要工具。通用大 模型通常在广泛的公开数据集上进行训练,这使得它们能够学习并解决各种常见问题,但这些数据集 无法完全覆盖某些特定领域的所有专业知识和技术细节,这导致尽管通用大模型具备广泛的通用知 识,却缺乏足够的知识深度来满足某些特定领域的复杂需求。因此,针对特定行业的需求来构建垂直 领域大模型变得尤为重要。垂直领域大模型,或称垂类大模型、行业大模型,是针对特定领域的数据和 应用而开发的大模型[1] 。与通用大模型相比,它们在训练过程中会使用大量特定领域的数据,从而能够 更准确地理解和生成与该领域相关的专业内容。 随着类 ChatGPT 的产品和神经网络模型的接连推出,“大模型”概念的范围也在逐步扩张[2‑4] 。鉴 于相关概念繁杂,为了确定本文的研究共识,需要对“大模型”概念进行定义并阐述其特点,从而奠定后 文对垂直领域大模型定制化的叙述基础。本文所提及的大模型(Foundation model),是在多模态大模型 (Multimodal large model)五模块框架(下文将详细介绍该框架)中,包含了能够实现其中一个或多个模 块功能的神经网络模型,且该模型符合以下特点: (1)大数据。使用覆盖了多种场景的大量数据进行模型的训练,为模型提供充足的知识。 (2)大参数。模型的参数量达到一定规模,足以将大量数据中隐含的知识固化到模型参数中。 (3)通用性。模型的输入数据格式和数据处理流程能够适配多种任务场景下的输入格式和需求。 (4)泛化性。模型拥有一定的泛化性,使其在未知数据域中依然具有良好性能。 根据大模型可处理的模态数量,可将大模型分为单模态大模型和多模态大模型: (1)单模态大模型。VGG[5] ,ResNet[6] ,GPT‑1 [7] ,GPT‑2 [8] ,GPT‑3 [9] ,GPT‑3.5 turbo[10] ,BERT[11] , GLM[12‑13] ,LLaMA[14] ,LLaMA‑2 [15] ,iGPT[16] ,LVM[17] ,BART[18] 和 T5 [19] 。 (2)多 模 态 大 模 型 。 CoDi[20],CoDi ‑ 2 [21],Claude ‑ 3 [22],GPT ‑ 4 [23],LLaVA[24],BriVL[25],Image‑ Bind[26] 和 NExT‑GPT[27] 。 在构建垂直领域大模型的过程中将面临一系列挑战,尤其是在数据获取和预处理阶段。比如,其 需要处理的垂直领域数据并不开源或难以获取,具有私密性;或是数据模态与通用大模型使用的中心 模态不同,导致无法迁移现成的大模型处理该数据;又或是垂直领域数据与预训练模型的数据域有所 不同,需要向预训练模型输入专业领域知识。垂直领域大模型应用方式灵活,涉及的应用领域繁杂,构 建难度大、开销大,涉及的技术安全问题至关重要,期望产生的经济效益高[28‑30] ,因此有必要对其构建方 法论进行深入探索和全面梳理,并总结出相应的方法论。 以往的综述文献都更多地关注大模型本身的发展[2‑4,31‑36] ,但对于垂直领域大模型的定制化方法论 方面缺乏详细的讨论。本文通过介绍垂直领域大模型定制的理论基础、垂直领域大模型的定制方法、 垂直领域大模型的应用实例,以及垂直领域大模型定制化的未来发展方向,为有意构建垂直领域大模 型应用的研究者及工作者提供模型定制方法论层面的参考。