

强化学习(RL)在具有明确定义的奖励函数的应用中取得了显著的成功,例如最大化视频游戏中的得分或优化算法的运行时间。然而,在许多现实世界的应用中,并没有明确定义的奖励功能。相反,基于人类反馈的强化学习(RLHF)允许RL代理从人类提供的数据中学习,例如轨迹的评估或排名。在许多应用中,人类反馈的收集成本很高;因此,从有限的数据中学习鲁棒的策略至关重要。
在这篇论文中,我们提出了新的算法来增强RLHF的样本效率和鲁棒性。首先,我们提出了主动学习算法,通过选择用户标记的最具信息性的数据点和根据关于用户偏好的不确定性来探索环境,从而提高RLHF的样本效率。我们的方法为RLHF的主动学习提供了概念上的清晰性,并提供了理论样本复杂性的结果,受到多臂老虎机和贝叶斯优化的启发。此外,我们在模拟中提供了大量的实证评估,证明了RLHF的主动学习的好处。 其次,我们将RLHF扩展到从人类偏好中学习约束,而不是或者除了奖励。我们认为,在安全关键的应用中,约束是人类偏好的一种特别自然的表示。我们开发了算法,从未知奖励的示范中有效地学习约束,并从人类反馈中主动学习约束。我们的结果表明,将人类偏好表示为约束可以导致更安全的策略,并扩展了RLHF的潜在应用。 所提出的奖励和约束学习算法为未来的研究提供了基础,以增强RLHF的效率、安全性和适用性。
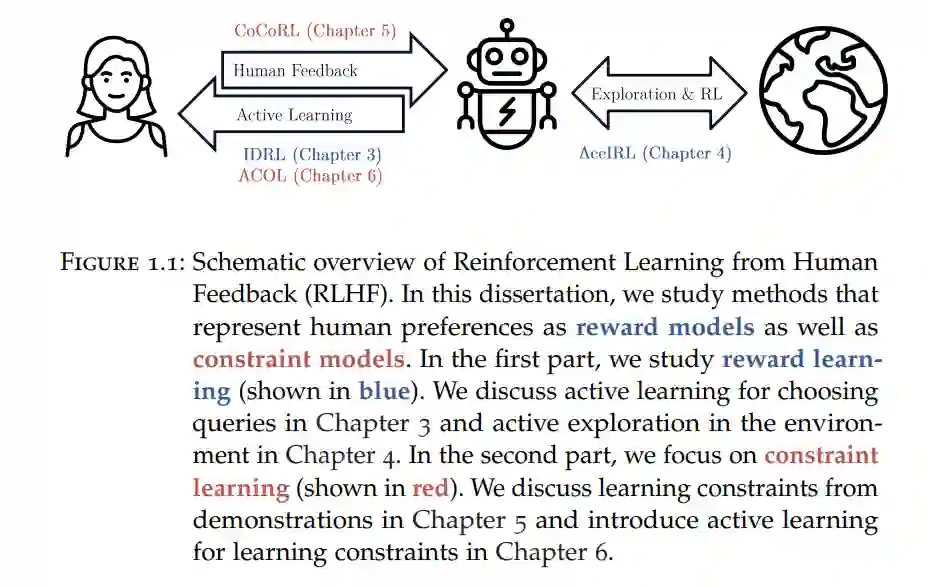
强化学习(RL; [1])旨在构建从经验中学习的AI系统。一个RL代理与环境互动,并通过试错,由奖励信号引导,改善其行为。RL代理已经在许多令人印象深刻的任务上取得了成功,包括玩复杂的棋盘游戏(例如,国际象棋[2]、围棋[3]和斯特拉戈[4])、视频游戏(例如,Dota[5]和星际争霸[6]),以及优化数据中心冷却[7]、视频压缩[8]和排序算法[9]。所有这些应用都有一个明确定义和可测量的奖励信号,例如,游戏是否赢得或算法使用了多少时间或内存。 然而,在许多实际任务中指定奖励函数可能是具有挑战性的[10]。例如,考虑为自动驾驶设计一个奖励函数。人们在驾驶时考虑了许多不同的目标,包括安全、舒适和效率。自动驾驶的奖励函数必须考虑所有这些因素,同时还要为代理提供足够密集的信号进行学习。Knox等人[11]发现,自动驾驶文献中提出的许多奖励函数未通过基本的一致性检查,例如,错过了重要的属性,有漏洞代理可以利用,或有可以导致不安全行为的奖励塑造条款。 基于人类反馈的强化学习(RLHF; [12])解决了设计奖励函数的困难。在RLHF中,代理不仅仅依赖预定义的奖励函数,而是使用人类反馈,例如评估或对代理在之前情境中的行为进行排名(图1.1)。RLHF提供了一种更直观和灵活的方式教RL代理复杂的行为,并承诺使RL适用于更广泛的任务。
最近,在自然语言处理中,RLHF显示出特别的成功,其中奖励函数很难指定。基于大型语言模型,使用RLHF训练的代理可以总结文本[13],遵循指示[14],或充当完整的对话代理[15]。尽管有潜力,但RLHF在多个方面面临挑战(参见Casper等人的综述[16])。这些挑战包括建模和算法设计的考虑(参见例如[17]),以及以人为中心的因素(参见例如[18])。在这篇论文中,我们关注与RLHF的样本效率和鲁棒性相关的算法挑战。 高质量的人类反馈是昂贵的,且当前方法需要大量反馈才能稳健地学习。人类的反馈对于学习过程是非常有价值的[13],但提供此反馈所需的时间、努力和专长往往是禁止的[19]。因此,我们考虑的第一个挑战是如何从有限的人类反馈中最大化价值。当前的RLHF方法为单一(学习到的)奖励函数进行优化,而人们通常有多个目标和偏好[20]。此外,一些偏好可能作为代理行为的约束,而不是奖励函数中的附加条款。例如,我们可以设计一个自动驾驶的奖励函数,同时测量安全性、舒适性和效率。然而,我们通常不想优化所有这些目标,而是在确保其他目标满足的同时优化一个目标。例如,我们可能希望在驾驶安全的同时尽快到达目的地。约束可以是人类偏好的自然表示的观察激发了我们考虑的第二个挑战:如何从人类反馈中学习约束。 我们现在到达了我们在这篇论文中研究的两个主要研究问题:
• 我们如何使RLHF更加样本高效? • 我们如何从人类反馈中学习约束?
解决第一个研究问题的主要方法是主动学习[21],即选择人类标记的最具信息性的数据点。先前的工作通常将标准的主动学习方法适应于RLHF(例如[22])。然而,RL的情况与监督学习有两个方面的不同。首先,在RL中,我们不想很好地近似“真实”的奖励函数,而是找到一个好的策略,使情况更像贝叶斯优化而不是主动学习。其次,在RL中,我们必须探索环境以收集供人类标记的数据,这在监督学习中是不必要的。这些差异激励我们为RLHF的主动学习定义替代目标,受到多臂老虎机和贝叶斯优化的工作的启发。
在许多安全关键的强化学习应用中,如机器人技术,约束是至关重要的。我们认为,在这样的领域中,我们应该从人类反馈中学习约束模型,而不仅仅是学习奖励模型。为了实现这一点,我们开发了算法来有效地学习约束,从而解答了我们的第二个研究问题。首先,我们专注于从带有未知奖励的示范中学习约束。其次,我们结合这种方法和主动学习来开发一种算法,从人类反馈中主动学习约束。
通过改进我们用来从人类反馈中学习奖励和约束的算法,我们可以扩大RLHF的可能应用范围。而且,学习更好的奖励和约束模型可能导致更鲁棒、可靠和安全的AI系统,能够处理复杂的任务。这篇论文中提出的算法可以为未来关于使RLHF变得更加高效和安全的研究和开发提供基础。
本论文分为两部分。第一部分关注学习奖励模型。我们提出了一种针对主动奖励学习的通用方法,该方法专注于学习一个好的策略,而不仅仅是减少近似误差(第3章),以及一种主动探索环境以收集数据并向专家查询的方法(第4章)。第二部分关注学习约束模型。我们认为约束可能是学习人类偏好的特别有用的表示,并提出了从一组带有未知奖励的示范中学习约束的方法(第5章),以及从关于轨迹安全性的反馈中主动学习约束的方法(第6章)。 图1.1概述了我们的贡献如何与典型的RLHF设置的不同部分相关。在以下内容中,我们总结了各章节的贡献。




