【斯坦福博士论文】面向行业级神经推荐的数据驱动统计分片,110页pdf

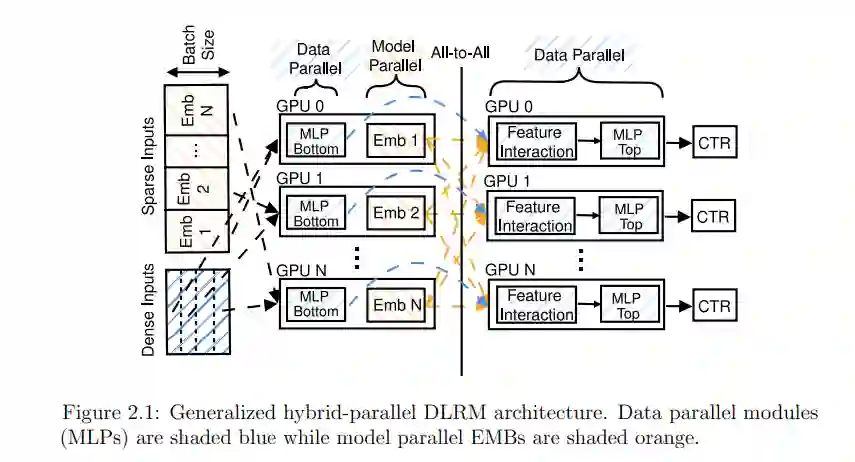
基于深度学习的推荐模型(DLRMs)构成了许多互联网规模的服务的主干,如网络搜索、社交媒体和视频流。这些模型主要由大量的嵌入表组成,可能有tb大小,需要大量的系统资源来训练和解决分片问题。分片问题是将嵌入表参数划分并放置在整个目标系统内存拓扑结构中,以使训练吞吐量最大化的任务。
本文主要工作:(1)对DLRM训练数据进行特征提取和统计,用于准确、细粒度地预测单个嵌入表行的内存需求;(2)提出了一种基于混合整数线性规划的分片方法RecShard,该方法利用这些统计信息来解决容量受限的单节点系统的分片问题,其中参数必须放置在高性能的GPU HBM和慢得多的CPU DRAM之间;减少对后者的访问;(3)提出了FlexShard,一种精确的行级分片算法,专注于跨多节点GPU训练集群对新兴的基于序列的DLRMs进行分片;利用这些统计数据可以显著减少节点间通信需求,这是向外扩展DLRM训练的瓶颈。
行业规模的DLRMs需要进行分片;然而,偏倚的DLRM训练数据幂律性质导致不精确的划分和放置决策,从而导致系统内存拓扑的负载不均衡。本文的工作为深入分析DLRM的细粒度内存访问模式提供了基础;以及两种基于此基础的新分片技术。这些技术在实际生产数据和系统部署上比之前的最先进技术有了显著改进。



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“S110” 就可以获取《【斯坦福博士论文】面向行业级神经推荐的数据驱动统计分片,110页pdf》专知下载链接



登录查看更多
相关内容
Arxiv
11+阅读 · 2019年10月30日



相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日