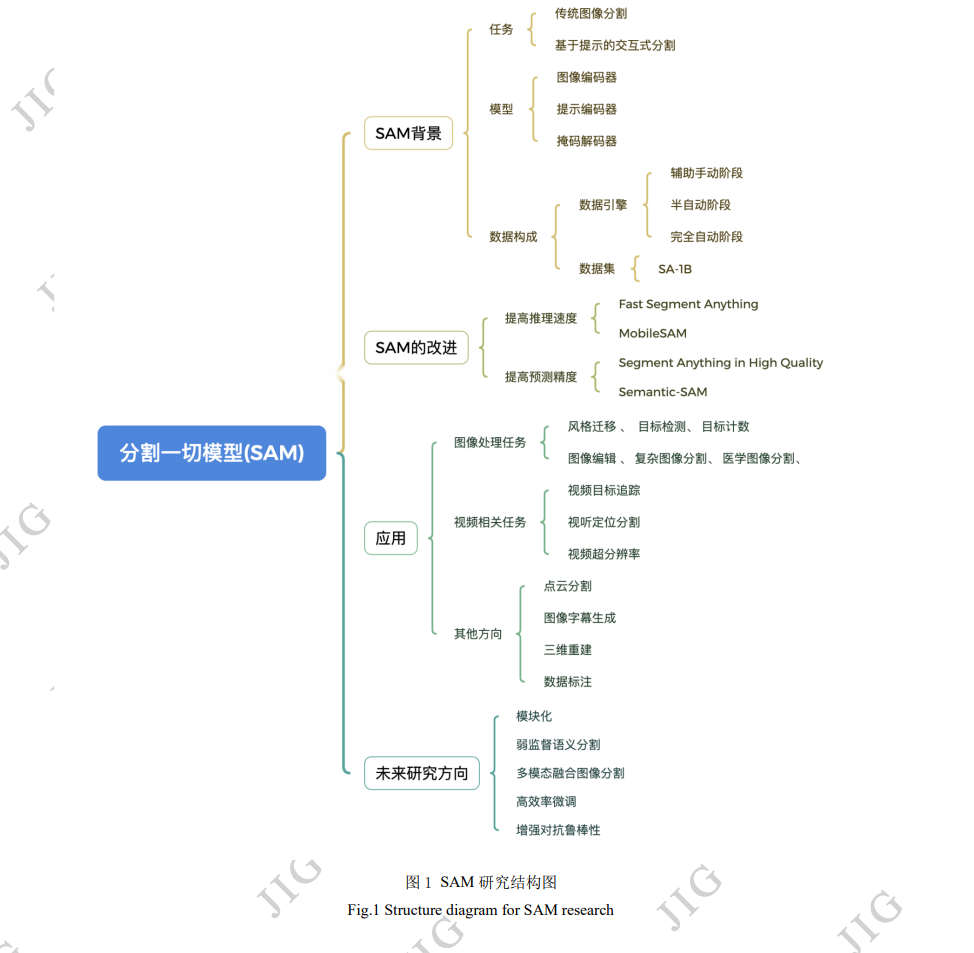
随着基于对比文本-图像对的预训练方法或者模型(contrastive language-image pre-training,CLIP)、聊天生成预训练转 换器(chat generative pre-trained transformer,ChatGPT)、生成预训练转换器4(generative pre-trained transformer-4,GPT-4)等基础 大模型的出现,通用人工智能(artificial general intelligence, AGI)的研究得到快速发展。AGI旨在为人工智能系统赋予更强大的 执行能力,使其能够自主学习、不断进化,解决各种问题和处理不同的任务,从而在多个领域得到广泛应用。这些基础模型 在大规模数据集上进行训练后,能够成功应对多样的下游任务。在这一背景下,Meta公司提出的分割一切模型(segment anything model,SAM)于2023年取得重要突破,在图像分割领域获得了优异的性能,以至于被称为图像分割终结者。其原因之一是, 通过SAM数据引擎方法用三阶段采集的、包含110万图像和超过10亿的掩码的分割一切-十亿(segment anything 1 billion,SA1B)图像分割数据集,同时保证了掩码的品质和多样性,继续导致在分割领域的突破。在SAM开源后不久,科研人员提出了一 系列改进的方法和应用。为了能全面深入了解分割一切模型的发展脉络,优势与不足,本文对SAM的研究进展进行了梳理和 综述。首先,本文从基础模型、数据引擎和数据集等多个方面简要介绍了分割一切模型的背景和核心框架。在此基础上,本 文详细梳理了目前分割一切模型的改进方法,包括提高推理速度和增进预测精度两个关键方向。然后,深入探讨分割一切模 型在图像处理任务、视频相关任务以及其他领域中的广泛应用。这一部分将详细模型在各种任务和数据类型上的卓越性能, 突出其在多个领域的泛用性和发展潜力。最后,对分割一切模型未来的发展方向和潜在应用前景进行了深入分析和讨论。