在深度学习之后的时代,Transformer架构在预训练的大型模型和各种下游任务中展示了其强大的性能。然而,这一架构巨大的计算需求已经让许多研究者望而却步。为了进一步降低注意力模型的复杂性,许多努力已经被投入到设计更高效的方法中。其中,状态空间模型(SSM)作为一种可能替代基于自监督学习的Transformer模型的方案,近年来越来越受到关注。在这篇论文中,我们首次提供了这些工作的综述,并提供实验比较和分析,以更好地展示SSM的特征和优势。具体来说,我们首先详细描述了原理,以帮助读者快速把握SSM的关键思想。之后,我们深入综述了现有的SSM及其在自然语言处理、计算机视觉、图形、多模态和多媒体、点云/事件流、时间序列数据等领域的各种应用。此外,我们提供了这些模型的统计比较和分析,希望能帮助读者理解不同结构在各种任务上的有效性。然后,我们提出了可能的研究方向,以更好地促进SSM理论模型和应用的发展。更多相关工作将在以下GitHub上持续更新:https://github.com/Event-AHU/Mamba State Space Model Paper List。 https://www.zhuanzhi.ai/paper/b84be72b4ad41b3ec43132c107bd2e7a
人工智能在2010年开始的第三波快速发展中,其中基于联结主义的深度学习技术扮演了极其重要的角色。深度学习的奇点可以追溯到AlexNet[1]的提出,该模型在ImageNet[2]比赛中取得了最佳性能(远超第二名)。此后,各种卷积神经网络(CNN)相继被提出,例如VGG[3]、ResNet[4]、GoogleNet[5]等。块、残差连接和Inception的思想启发了许多后续深度神经网络的设计[6]、[7]。另一方面,循环神经网络(RNN)家族,如长短时记忆网络(LSTM)[8]和门控循环单元(GRU)[9],主导了基于序列的学习领域,包括自然语言处理和音频处理。为了进一步扩展深度神经网络在图数据上的应用,提出了图神经网络(GNNs)[10]、[11]。然而,这些主流模型在数据集和计算力支持达到最大时仍面临瓶颈。 为了解决CNN/RNN/GNN模型仅能捕捉局部关系的问题,2017年提出的Transformer[13]能够很好地学习长距离特征表示。核心操作是自监督学习机制,它将输入的令牌转换为查询、键和值特征,并通过查询和键特征之间的乘积得到的相似性矩阵与值特征相乘,输出长距离特征。Transformer架构首先在自然语言处理社区借助预训练和微调范式[14]得到广泛应用,例如BERT[15]、ERNIE[16]、BART[17]、GPT[18]。然后,其他领域也通过这些网络得到推动,例如在计算机视觉中发布的ViT[19]和Swin-Transformer[20]。许多研究者还通过结合Transformer和其他网络,或适应Transformer于多模态研究问题[21]、[22],探索混合网络架构。在当前阶段,大型基础模型正在出现,参数高效微调(PEFT)策略[23]也得到了极大的发展。然而,当前基于Transformer的模型仍需要配备大内存的高端显卡进行训练和测试/部署,这极大地限制了它们的广泛应用。
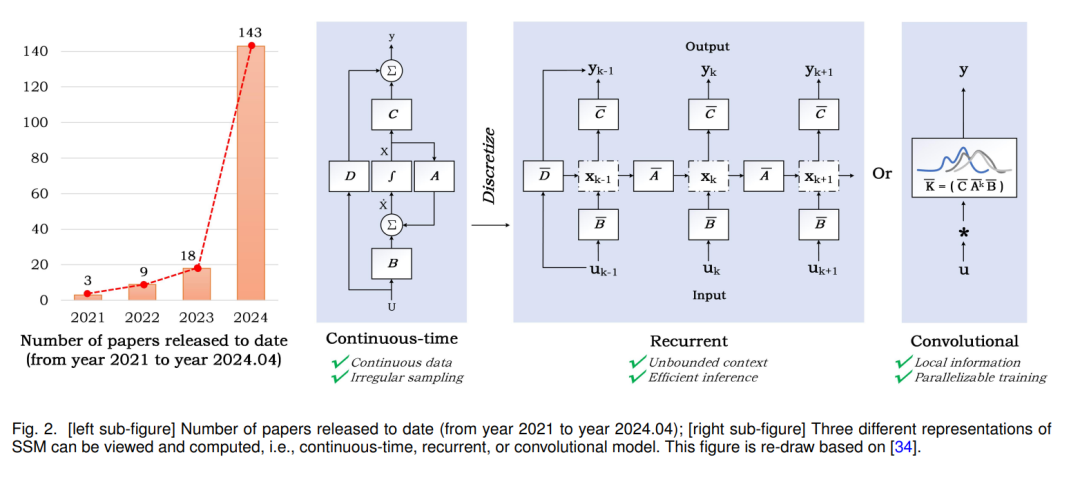
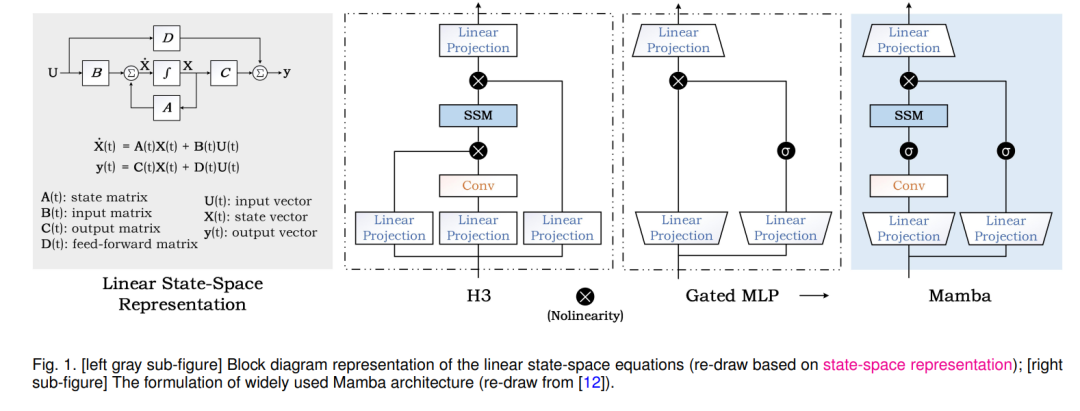
为了进一步降低计算成本,同时捕捉长距离依赖并保持高性能,许多新的基于稀疏注意力的模型或新的神经网络范式被提出[24]–[28]。其中,状态空间模型(例如,Mamba [12],S4 [29],S4nd [30]),如图1所示,成为关注的中心。如图2左部分所示,与SSM相关的论文发布量显示出爆炸性增长的趋势。状态空间模型(SSM)最初是为了使用状态变量来模拟控制理论、计算神经科学等领域的动态系统而提出的框架。当将这一概念适用于深度学习时,我们通常指的是线性不变(或稳定)系统。原始的SSM是一个连续动态系统,可以离散化以适应计算机处理的递归和卷积视角。SSM可以用于各种数据处理和特征学习,包括图像/视频数据、文本数据、结构化图数据、事件流/点云数据、多模态/多媒体数据、音频和语音、时间序列数据、表格数据等。它还可以用来构建高效的生成模型,如基于SSM的扩散生成模型[31]–[33]。为了帮助读者更好地理解SSM并跟踪最新的研究进展和各种应用,本文对该领域进行了系统的综述,并通过实验验证了SSM模型在下游任务中的性能。希望这篇综述能更好地引导和促进SSM领域的发展。
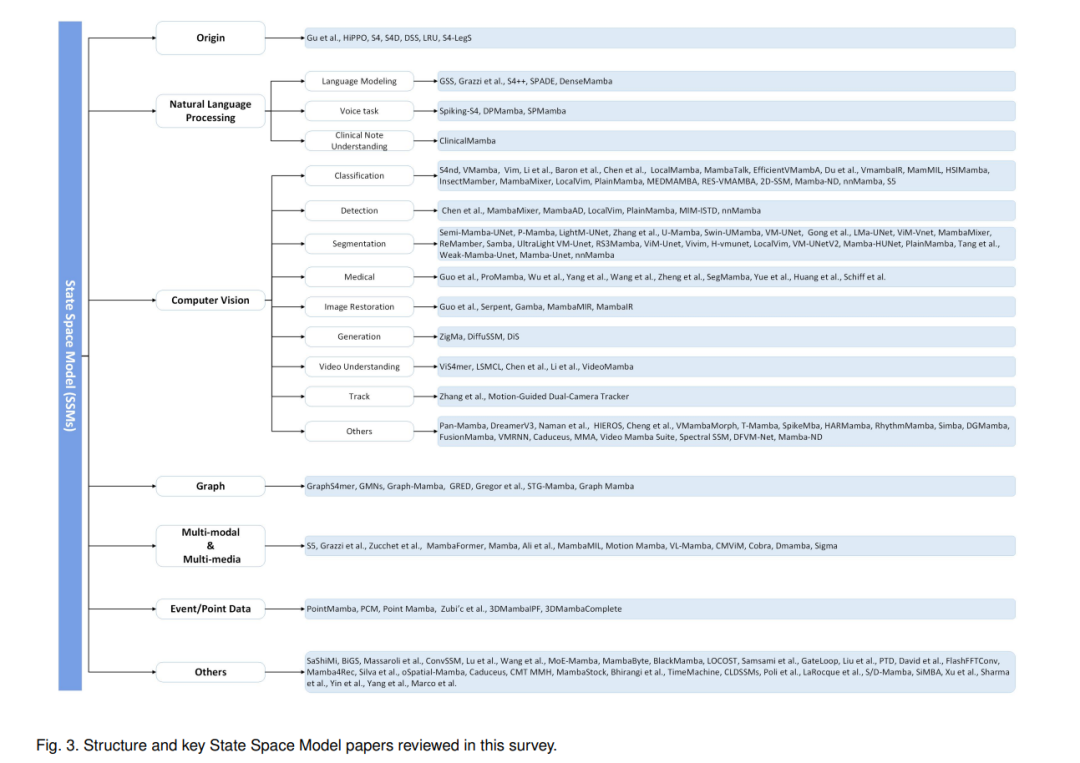
本综述的组织。在本文中,我们首先在第2节提供状态空间模型工作原理的初步预览。然后,在第3节,我们专注于从多个方面综述SSM的相关工作,包括SSM的起源和变体、自然语言处理、计算机视觉、图形、多模态和多媒体、点云/事件流、时间序列数据和其他领域。在本综述中审查的结构和关键状态空间模型相关论文的概览在图3中说明。更重要的是,我们在第4节对多个下游任务进行了广泛的实验,以验证SSM在这些任务中的有效性。下游任务涉及单/多标签分类、视觉对象跟踪、像素级分割、图像到文本生成和人员/车辆重识别。我们还在第5节提出了几个可能的研究方向,以促进SSM的理论和应用。最后,在第6节中我们对本文进行了总结。