
选择要攻击的威胁是战场上最重要的决策之一。该决策问题表现为武器-目标分配问题(WTA)。在以往的研究中,动态编程、线性规划、元启发式和启发式方法已被用于解决这一问题。然而,以往的研究因建模过于简化、计算负担重、缺乏对干扰事件的适应性以及问题规模变化时的重新计算等问题而受到限制。为了克服这些局限性,本研究旨在利用强化学习和图神经网络来解决 WTA 问题。所提出的方法反映了现实世界的决策框架--OODA-loop(观察-定向-决策),具有很高的实用性。在各种环境中进行了实验,并通过与现有的启发式和元启发式方法进行比较,证明了所提方法的有效性。所提出的方法为战术指挥与控制中的智能决策引入了一种开创性的方法,传统上被认为是人类专家的专属方法。

本研究将强化学习与图形神经网络(GNN)相结合。强化学习与 GNN 的结合是最有前途的领域之一,因为 GNN 能有效地表示复杂的交互作用。为了应用强化学习,DWTA 被建模为 POMDP(部分可观测马尔可夫决策过程)。为了优化强化学习智能体的策略,采用了近端策略优化(PPO)。学习环境是一个仿真模型,反映了对真实世界的详细描述。本研究的贡献如下。
-
本研究利用深度强化学习和图神经网络在各种情况下做出优化决策,为复杂性和不确定性主导的情况提供丰富的目标导向表征。
-
图神经网络有助于提高我们方法的可扩展性,从而增强其实际用途。
-
提出的方法通过人工智能技术的增强,为传统上由人类专家主导的领域(如战术指挥和控制)的决策制定带来了创新。
-
从整数编程中定义的问题出发,利用马尔可夫状态的理论基础和图建模技术系统地构建了 POMDP。与依靠直觉和经验法则推导 POMDP 的传统方法相比,这是一种更有条理的方法,更容易看出 POMDP 与所定义问题之间的联系。
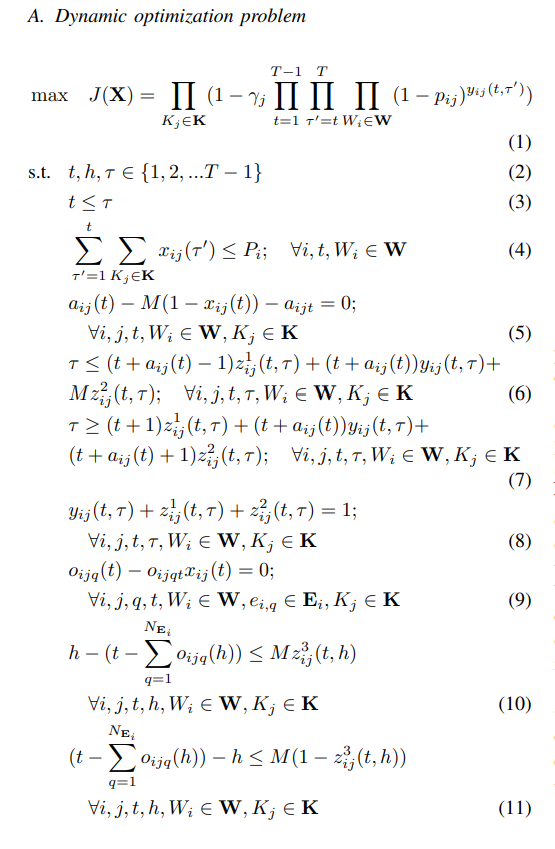
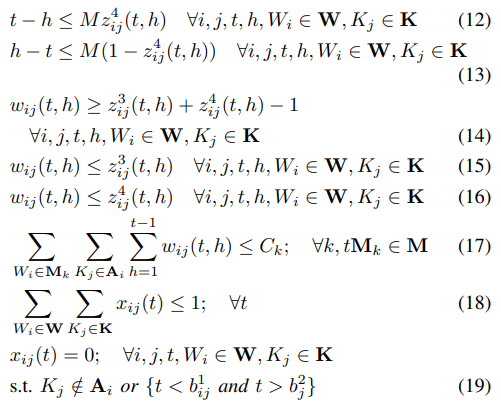
成为VIP会员查看完整内容
相关内容

Physics-informed neural networks (PINNs) for numerical model error approximation and superresolution
Arxiv
0+阅读 · 2024年11月14日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
89+阅读 · 2021年10月21日



相关VIP内容
相关资讯
相关论文
Physics-informed neural networks (PINNs) for numerical model error approximation and superresolution
Arxiv
0+阅读 · 2024年11月14日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
89+阅读 · 2021年10月21日