

历史上,科学发现是一个漫长且昂贵的过程,从最初的构想到最终的结果需要大量的时间和资源。为了加速科学发现,降低研究成本,并提高研究质量,我们提出了智能体实验室(Agent Laboratory),一个基于大语言模型(LLM)的自主框架,能够完成整个研究过程。该框架接受由人工提供的研究思路,并经过三个阶段——文献回顾、实验设计与执行、报告撰写——最终生成全面的研究成果,包括代码库和研究报告,同时在每个阶段允许用户提供反馈和指导。我们使用多个先进的大语言模型部署智能体实验室,并邀请多位研究人员通过参与调查、提供人工反馈以指导研究过程、以及评估最终论文来评估其质量。我们发现:(1)由 o1-preview 驱动的智能体实验室产生了最佳的研究成果;(2)生成的机器学习代码相较于现有方法能够达到最先进的性能;(3)人工参与、在每个阶段提供反馈,显著提高了整体研究质量;(4)智能体实验室显著降低了研究开销,相较于以往的自主研究方法,减少了 84%。我们希望智能体实验室能够使研究人员将更多精力集中在创造性构思上,而不是低层次的编码和写作,从而加速科学发现。 https://arxiv.org/abs/2501.04227

1. 引言
科学家常常面临限制,限制了他们在任何给定时间可以探索的研究思路数量,从而导致研究思路根据预测的影响力进行优先排序。虽然这一过程有助于确定哪些概念值得投入时间,以及如何有效地分配有限的资源,但许多高质量的研究思路仍未得到探索。如果探索研究思路的过程能够减少这些限制,研究人员就能同时探索多个概念,从而增加科学发现的可能性。 为实现这一目标,近期的研究探讨了大语言模型(LLM)在研究构思和自动化论文生成方面的能力,其中LLM智能体扮演了人类科学家的角色(Baek et al. (2024); Ghafarollahi & Buehler (2024b); Lu et al. (2024a); Swanson et al. (2024))。Baek et al. (2024)的研究介绍了ResearchAgent,该系统自动生成研究思路、方法和实验设计,并通过多个模拟同行讨论的评审智能体的反馈迭代地改进这些思路,利用与人类对齐的评估标准来提升输出的质量。Lu et al. (2024a)则探讨了完全自动化的论文生成,AI Scientist框架能够生成新的研究思路、编写代码、进行实验,并创建完整的科学论文,同时通过自动化同行评审系统评估研究成果。尽管这些工作展示了当前的LLM能够生成被认为比人类专家提出的思路更具创新性的研究思路,但Si et al. (2024)指出,LLM在可行性和实施细节上仍然存在不足,表明LLM在研究中的作用应当是补充性的,而非替代性的。因此,我们的目标是设计一个自主智能体流水线,帮助人类实现自己的研究思路。 在本工作中,我们介绍了智能体实验室(Agent Laboratory),一个加速个人进行机器学习研究的自主流水线。与以往的研究方法不同,在这些方法中,智能体独立进行研究构思,不依赖于人类输入(Baek et al. (2024); Lu et al. (2024b)),智能体实验室旨在通过语言智能体帮助人类科学家执行他们自己的研究思路。智能体实验室接受人工提供的研究思路作为输入,输出由自主语言智能体生成的研究报告和代码库,并允许根据用户偏好在每个阶段提供不同程度的人工参与与反馈。我们的贡献包括以下几点:
- 我们介绍了智能体实验室,一个开源的LLM智能体框架,旨在加速个人进行机器学习研究的能力。为了适应所有用户,智能体实验室具有灵活的计算资源分配功能,可以根据用户对计算资源(例如CPU、GPU、内存)和模型推理预算的访问情况,分配不同级别的计算资源。
- 人类评审者对使用智能体实验室生成的论文进行了评估,涉及实验质量、报告质量和实用性。结果表明,虽然o1-preview后端被认为是最有用的,但o1-mini在实验质量得分上最高,而gpt-4o在所有指标上都较为落后。
- NeurIPS风格的评估显示,o1-preview在所有后端中表现最佳,尤其在清晰度和合理性方面,获得了人类评审者的高度评价。然而,自动评估与人工评估之间存在明显差距,自动评分显著高估了质量(6.1/10对比3.8/10)。在清晰度和贡献指标上也出现了类似的差异,表明需要人工反馈来补充自动评估,以便更准确地评估研究质量。
- 在智能体实验室中,联合飞行模式(Co-pilot Mode)在定制主题和预选主题下进行了评估,显示出相较于自主模式更高的整体得分。联合飞行模式生成的论文在实验质量和实用性方面存在权衡,反映了智能体输出与研究者意图对齐的挑战。
- 在人类用户评价中,智能体实验室的联合飞行模式整体被认为具有较高的实用性和可用性,大多数参与者表示愿意在体验后继续使用该功能。
- 提供了详细的成本和推理时间统计数据,以及不同模型后端的每个阶段成本拆解,展示了智能体实验室在自动化研究方面的优势,与其他研究相比,大大降低了价格(使用gpt-4o后端时,每篇论文仅需2.33美元)。
- 在使用所提出的mle-solver解决一部分MLE-Bench挑战时,智能体实验室展示了领先的性能,达到了比其他解算器更高的一致性和得分,获得了比MLAB、OpenHands和AIDE更多的奖牌,包括金奖和银奖。
我们希望本工作能够加速机器学习领域的科学发现,帮助研究人员将更多精力投入到创造性构思和实验设计上,而不是低层次的编码和写作。
2. 背景与相关工作
2.1 大型语言模型(LLMs)
Agent Laboratory 中的研究智能体基于自回归大型语言模型(LLMs),这些模型通过大量的文本语料库进行训练,能够预测词序列的条件概率 p(xt∣xϵ;θ)),并通过采样生成文本补全。LLMs 使用Transformer架构(Vaswani, 2017)来捕捉文本中的长距离依赖关系。这些模型,如Claude(Anthropic, 2024)、Llama(Dubey et al., 2024; Touvron et al., 2023a, 2023b)和ChatGPT(Achiam et al., 2023; Hurst et al., 2024; OpenAI, 2022),利用大规模数据集和扩展技术,能够执行多种基于语言的任务,如翻译、摘要和推理。
2.2 LLM智能体
尽管LLMs在理解和推理方面表现出色,但在实际任务执行中仍面临挑战。为了克服这些限制,LLMs的能力通过结构化框架得到扩展,使其能够自主或半自主地执行任务(Chen et al., 2023b; Li et al., 2023; Qian et al., 2024; Wu et al., 2023)。这些系统被称为智能体,利用诸如链式思维提示(Wei et al., 2022)、迭代优化(Shinn et al., 2024)、自我改进(Huang et al., 2022)和外部工具集成等技术来执行复杂的工作流程(Hao et al., 2024; Qin et al., 2023; Schick et al., 2023)。LLM智能体在解决现实世界中的任务方面取得了显著进展,如软件工程(Jimenez et al., 2023; Wang et al., 2024b; Yang et al., 2024)、网络安全(Abramovich et al., 2024; Fang et al., 2024; Wan et al., 2024)和医疗诊断(McDuff et al., 2023; Schmidgall et al., 2024; Tu et al., 2024)。
2.3 自动化机器学习
自动化机器学习是一个活跃的研究领域,许多方法使用Kaggle(一个在线机器学习竞赛平台)作为评估智能体性能的基准。值得注意的是,MLE-Bench(Chan et al., 2024)、DS-bench(Jing et al., 2024)和MLAgentBench(Huang et al., 2024)分别提出了使用75、74和6个Kaggle挑战作为基准,以衡量ML智能体在数据准备、模型开发和提交等任务中的能力。多个ML“求解器”已经被引入,如AIDE(Schmidt et al., 2024)、CodeActAgent(Wang et al., 2024b)和ResearchAgent(Huang et al., 2024),这些求解器能够自动化特征实现、错误修复和代码重构,具有较高的成功率。
2.4 AI在科学发现中的应用
AI在多个学科中支持科学发现已有数十年历史。例如,AI在数学(Romera-Paredes et al., 2024)、材料科学(Merchant et al., 2023; Pyzer-Knapp et al., 2022; Szymanski et al., 2023)、化学(Hayes et al., 2024; Jumper et al., 2021)、算法发现(Fawzi et al., 2022)和计算生物学(Ding et al., 2024)等领域都有应用。这些方法将AI定位为工具,而不是自主研究的智能体。
2.5 LLMs在研究相关任务中的应用
LLMs在多种研究相关任务中表现出强大的能力,如代码生成(Chen et al., 2021; Nijkamp et al., 2022)、端到端软件开发(Hai et al., 2024; Phan et al., 2024; Qian et al., 2023, 2024)、研究问题回答(Chen et al., 2024a; Lala et al., 2023; Lin et al., 2024; Song et al., 2024)、研究构思(Baek et al., 2024; Ghafarollahi & Buehler, 2024b; Li et al., 2024a; Si et al., 2024)、自动化论文评审(D'Arcy et al., 2024; Liang et al., 2024; Lu et al., 2024b; Weng et al., 2024)、文献搜索(Ajith et al., 2024; Kang & Xiong, 2024; Li et al., 2024b; Press et al., 2024)和实验结果预测(Ashokkumar et al., 2024; Lehr et al., 2024; Luo et al., 2024; Manning et al., 2024; Zhang et al., 2024)。 尽管LLMs在上述任务中取得了显著进展,但在构思方面仍存在挑战。一些研究表明,LLMs的构思比人类更具新颖性(Si et al., 2024),而另一些研究则显示其创造力较低(Chakrabarty et al., 2024),并且存在同质化效应(Anderson et al., 2024; Zhou et al., 2024),这可能会限制创造性发现,尤其是在缺乏人类指导的情况下。
2.6 LLMs在自主研究中的应用
近年来,自动化科学工作流的进展主要集中在利用LLMs模拟研究过程。Swanson et al. (2024) 引入了一组LLM智能体,与人类研究人员一起工作,最终目标是设计针对SARS-CoV-2新变种的纳米抗体。ChemCrow(M. Bran et al., 2024)和Coscientist(Boiko et al., 2023)展示了在化学领域进行自主构思和实验的能力。ResearchAgent(Baek et al., 2024)通过评审智能体的反馈自动化研究构思、实验设计和迭代优化。The AI Scientist(Lu et al., 2024b)进一步扩展了这一自动化过程,涵盖端到端的科学发现,包括编码、实验执行和自动化同行评审以生成手稿。 尽管这些进展显著,Si et al. (2024) 等研究指出,LLMs在构思的可行性和实施细节方面仍存在局限性,表明LLMs在自主研究中的角色是补充而非替代。
3. Agent Laboratory 框架
3.1 概述
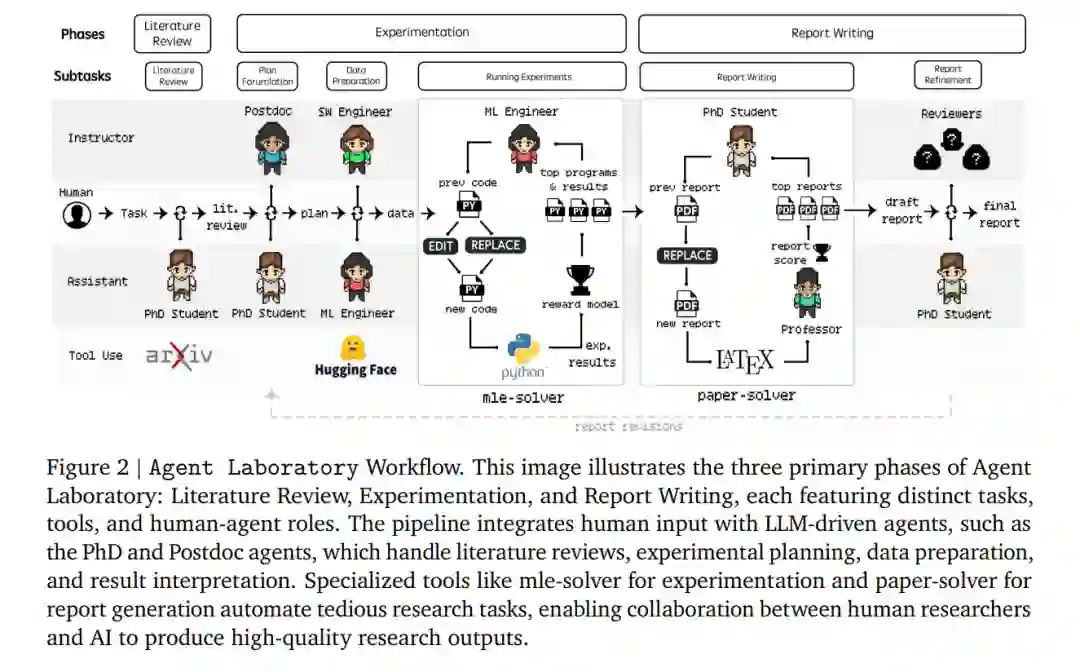
Agent Laboratory 的总体工作流程包括三个主要阶段:文献综述、实验和报告撰写。每个阶段都有专门的智能体负责执行相应的任务。如图2所示,整个流程集成了人类输入和LLM驱动的智能体,如PhD智能体和Postdoc智能体,它们负责文献综述、实验规划、数据准备和结果解释。此外,专门的工具如mle-solver(用于实验)和paper-solver(用于报告生成)自动化了繁琐的研究任务,使得人类研究人员与AI能够协作生成高质量的研究成果。
3.2 文献综述
文献综述阶段的目标是为给定的研究想法收集和整理相关的研究论文,为后续阶段提供参考。在此过程中,PhD智能体使用arXiv API检索相关论文,并执行三个主要操作:摘要、全文和添加论文。摘要操作检索与初始查询相关的前20篇论文的摘要,全文操作提取特定论文的完整内容,而添加论文操作则将选定的摘要或全文纳入到整理的综述中。这个过程是迭代的,智能体会执行多次查询,评估每篇论文的相关性,并逐步完善综述内容。
3.3 实验
**3.3.1 计划制定
计划制定阶段的目标是基于文献综述和研究目标,制定详细且可操作的研究计划。在此阶段,PhD智能体和Postdoc智能体通过对话协作,详细说明如何实现研究目标,包括使用哪些机器学习模型、使用哪些数据集以及实验的高层次步骤。一旦达成共识,Postdoc智能体使用plan命令提交计划,该计划将作为后续子任务的指令集。
**3.3.2 数据准备
数据准备阶段的目标是编写代码,准备用于运行实验的数据。ML Engineer智能体使用Python命令执行代码,并观察任何打印输出。ML Engineer可以访问HuggingFace数据集,并通过search HF命令进行搜索。在达成一致后,SW Engineer智能体使用submit code命令提交最终的数据准备代码。在最终提交之前,代码会通过Python编译器进行检查,以确保没有编译问题。这个过程将迭代执行,直到代码没有错误为止。
**3.3.3 运行实验
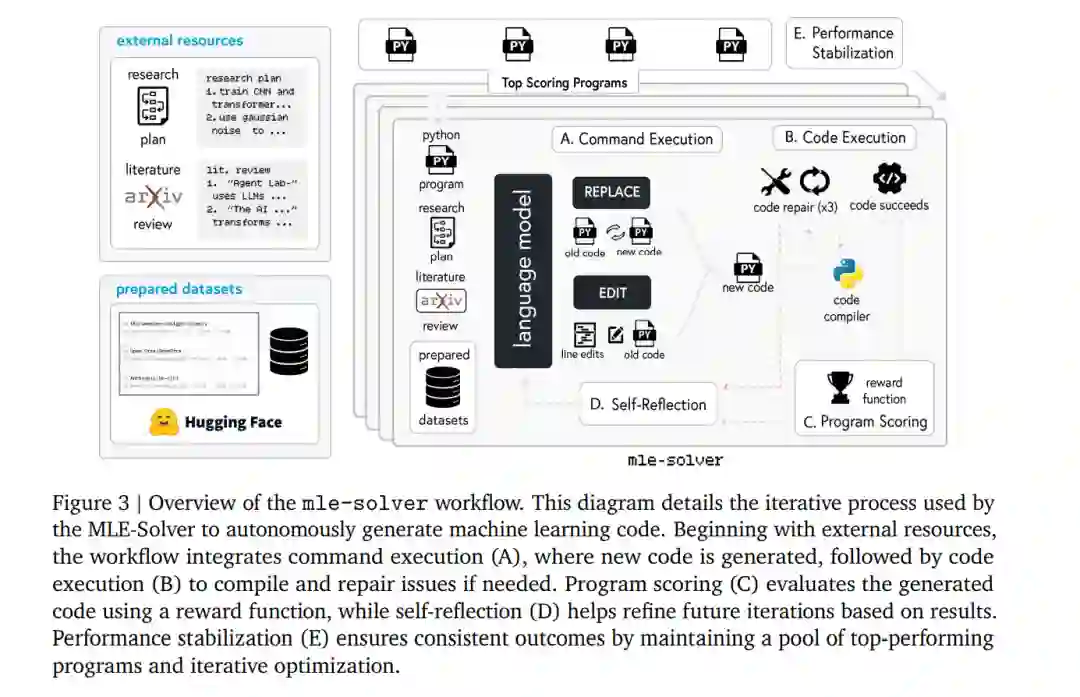
在运行实验阶段,ML Engineer智能体专注于实施和执行先前制定的实验计划。这一过程由mle-solver模块支持,该模块能够自主生成、测试和优化机器学习代码。mle-solver首先基于研究计划和文献综述的见解生成初始代码。在第一个mle-solver步骤中,程序为空,必须从头生成一个文件,该文件将作为最高得分的程序。mle-solver的工作流程如下:
- 命令执行:在命令执行阶段,从一组表现最佳的程序中采样初始程序,并通过REPLACE和EDIT操作迭代优化该程序,以更好地与实验目标对齐。
- 代码执行:代码命令执行后,新程序会通过编译器检查运行时错误。如果成功编译,则返回一个分数,并更新最高得分程序列表。如果代码未编译成功,智能体会尝试修复代码,最多尝试NrepN次(实验中Nrep=3),然后返回错误并继续下一个代码替换。
- 程序评分:如果代码成功编译,则将其发送到评分函数,该函数使用LLM奖励模型评估生成的ML代码的有效性。奖励模型根据研究计划、生成的代码和观察到的输出,给出0到1的分数。
- 自我反思:无论代码成功还是失败,都会根据实验结果或遇到的错误信号生成自我反思。mle-solver会反思其行为的结果,并在下一次迭代中改进代码。
- 性能稳定:为了防止性能漂移,mle-solver采用两种机制:最高程序采样和批量并行化。最高程序采样维护一组最高得分的程序,并在执行命令前随机采样一个程序,以确保多样性。批量并行化则涉及同时进行N次修改,并选择最佳修改替换最低得分的程序。
3.4 报告撰写
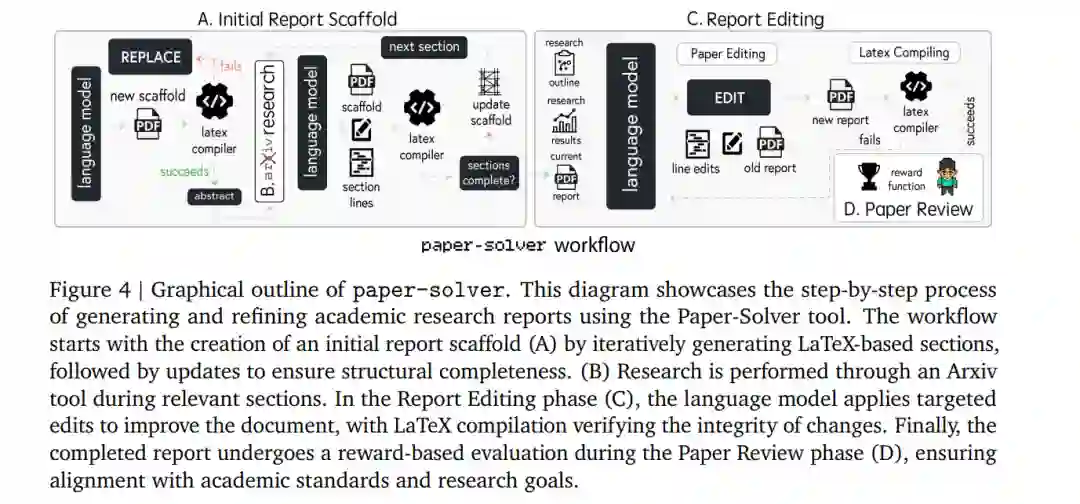
在报告撰写阶段,PhD智能体和Professor智能体将研究结果综合成一份全面的学术报告。这一过程由paper-solver模块支持,该模块迭代生成和优化报告。paper-solver的目标是生成一份人类可读的报告,总结Agent Laboratory生成的研究成果。报告遵循学术论文的标准结构,确保其符合会议提交要求。
**3.4.1 初始报告框架
paper-solver的第一个任务是生成研究报告的初始框架。该框架将文档结构划分为八个标准部分:摘要、引言、背景、相关工作、方法、实验设置、结果和讨论。在框架创建过程中,每个部分都会插入占位符,以便后续填充内容。该框架包括必要的LaTeX格式,确保生成的论文可以直接进行评审和优化。
**3.4.2 arXiv研究
在框架构建阶段,paper-solver可以访问arXiv,以探索与其撰写主题相关的文献。arXiv的访问方式与文献综述阶段相同,智能体可以根据需要扩展文献搜索范围。
**3.4.3 报告编辑
一旦框架构建完成,paper-solver使用专门的命令迭代优化生成的论文。主要的命令是EDIT,该命令允许对LaTeX代码进行逐行修改,确保内容与研究计划一致,论证清晰,并符合格式标准。在集成编辑之前,系统会编译LaTeX以验证无错误功能,从而保持文档的完整性。
**3.4.4 论文评审
为了在paper-solver迭代过程中获得论文的评分,我们采用了Lu et al. (2024b) 开发的自动化评审系统的改进版本。该系统使用基于LLM的智能体模拟NeurIPS会议的论文评审过程。评审系统根据研究计划、生成的代码和观察到的输出,给出0到1的分数。
3.5 自主模式与协作者模式
Agent Laboratory 可以在两种模式下运行:自主模式和协作者模式。在自主模式下,除了提供初始研究想法外,没有任何人类参与,每个子任务在完成后自动进入下一个子任务。在协作者模式下,除了提供研究想法外,每个子任务结束时都有一个检查点,人类可以审查智能体在该阶段生成的工作(如文献综述摘要或生成的报告)。人类评审者可以决定进入下一个子任务,或者要求智能体重复该子任务,并提供高层次的改进建议。
4. 结果
4.1 语言模型的质量评估
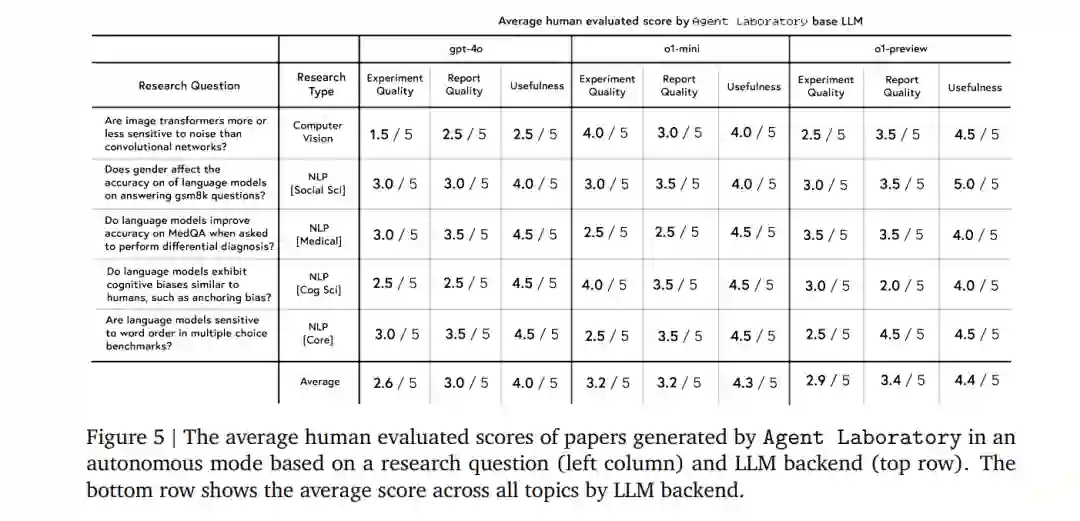
我们首先评估了Agent Laboratory在自主模式下生成的论文的质量。我们邀请了10位志愿者PhD学生,每人随机评审3篇论文,评估实验质量、报告质量和有用性。结果显示,不同LLM后端的表现存在显著差异。o1-preview在有用性和报告质量方面表现最佳,而o1-mini在实验质量方面表现最好。gpt-4o在所有指标上均落后于其他模型。
4.2 协作者模式的质量评估
在协作者模式下,我们评估了Agent Laboratory作为研究工具的效用和生成的论文质量。研究人员在自定义和预选主题上使用Agent Laboratory,结果显示协作者模式下的论文质量显著高于自主模式。研究人员普遍认为,协作者模式下的Agent Laboratory具有较高的实用性和可用性,大多数参与者决定在体验后继续使用该工具。
4.3 运行时间和成本分析
我们详细分析了Agent Laboratory在不同模型后端下的运行时间和成本。结果显示,gpt-4o在执行时间和成本方面表现最佳,整个工作流程的平均成本仅为2.33美元,显著低于其他模型。
4.4 mle-solver在MLE-Bench上的评估
为了更客观地评估mle-solver的能力,我们使用了MLE-Bench中的10个ML挑战。结果显示,mle-solver在解决一般ML问题方面优于其他方法,获得了更多的奖牌(包括金牌和银牌)。
5. 讨论与未来工作
Agent Laboratory 展示了作为研究工具的潜力,但仍存在一些局限性。未来的研究可以进一步优化工作流程,改进自我评估机制,并探索更灵活的代码和报告生成方式。此外,长期研究可以比较使用和不使用Agent Laboratory的研究成果,以更好地理解其对研究效率和科学发现的影响。
6. 结论
Agent Laboratory 是一个基于LLM智能体的自主研究框架,旨在加速机器学习研究。通过集成人类反馈和自动化工具,Agent Laboratory 能够显著降低研究成本,提高研究质量。我们希望通过这一工具,研究人员能够将更多精力集中在创造性构思和实验设计上,从而加速科学发现的进程。
