这篇博客解释了如何训练和微调大型语言模型(LLMs)以创建像Chat-GPT这样的系统。我们将讨论模型的预训练、少样本学习、有监督微调、基于人类反馈的强化学习(RLHF)以及直接偏好优化。我们之前的博客以高层次地介绍了这些观点。在本文中,我们力图让这些概念在数学上更为精确,并提供关于为什么使用特定技术的洞察。
大型语言模型
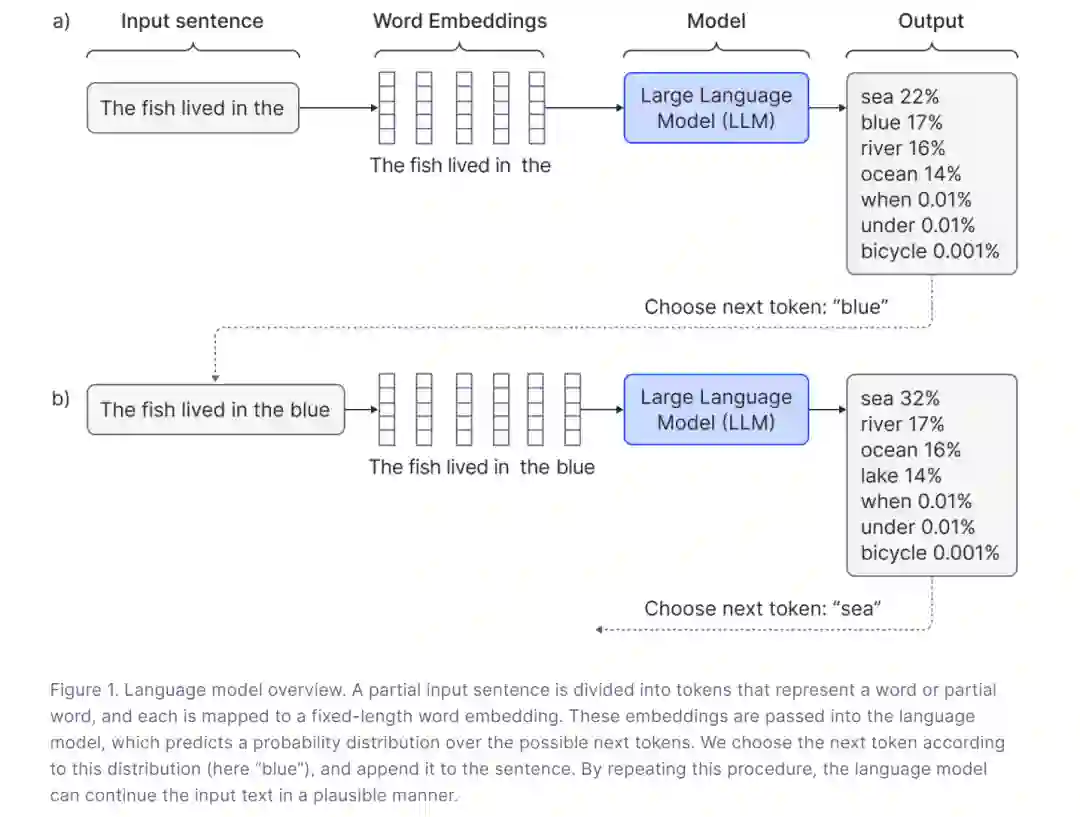
对于本博客的目的,我们将假定大型语言模型是一个变换器解码器网络。解码器网络的目标是预测部分完成的输入字符串中的下一个词。更准确地说,这个输入字符串被划分为令牌(tokens),每一个令牌都代表一个词或部分词。每个令牌被映射到一个相应的固定长度的嵌入(embedding)。代表这个句子的一系列嵌入被送入解码器模型中,该模型预测序列中可能下一个令牌的概率分布(图 1)。下一个令牌可以通过从这个分布中随机抽样来选择,然后将扩展的序列反馈到模型中。通过这种方式,字符串逐渐得到扩展。这个过程被称为解码。请参见我们之前的博客了解其他解码方法。
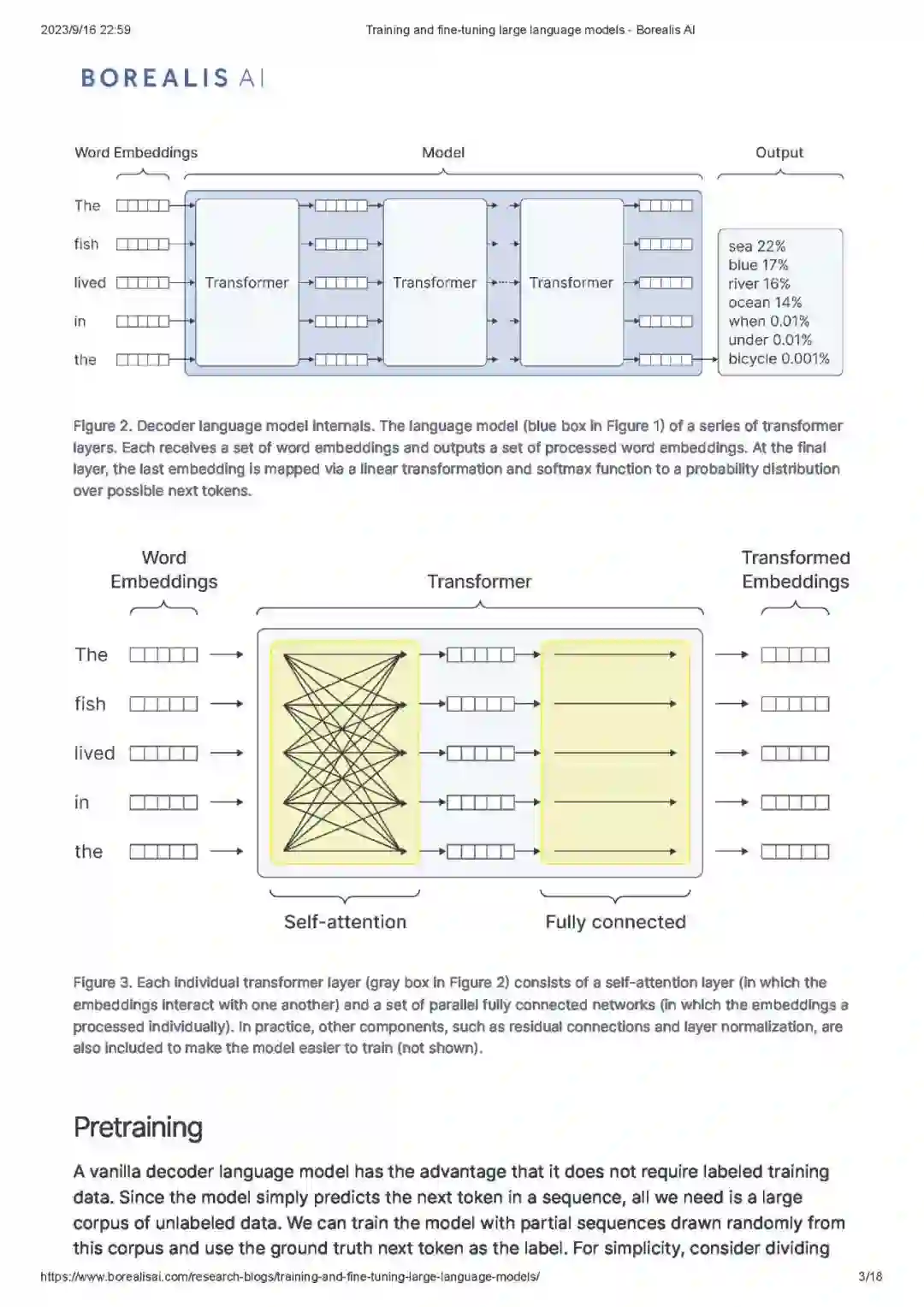
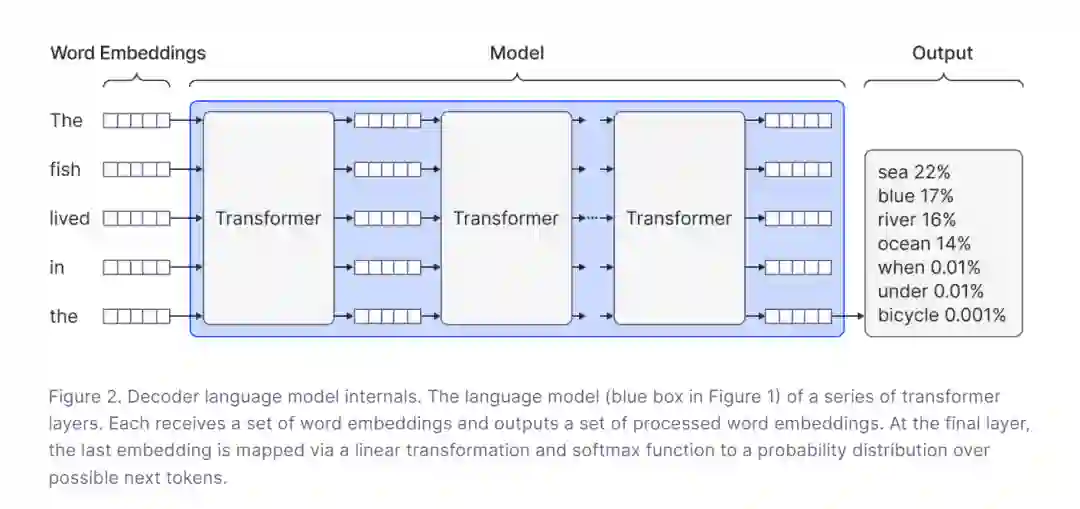
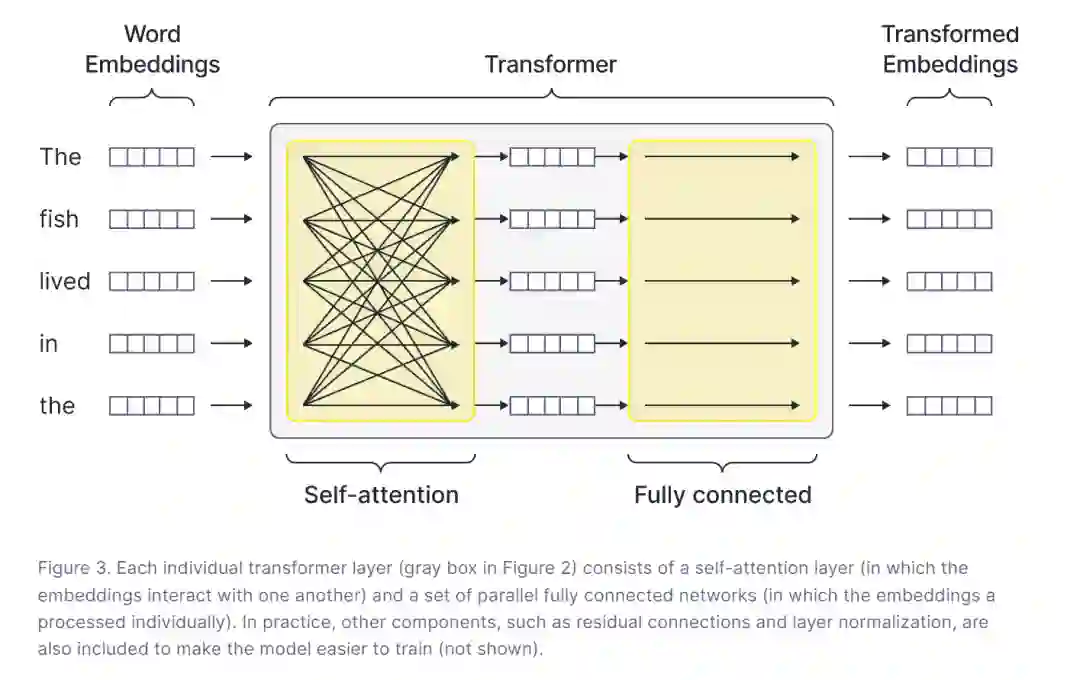
解码器网络由一系列变换器层组成(图 2)。每一层(图 3)都通过自注意力机制(self-attention mechanism)混合来自令牌嵌入(token embeddings)的信息,并通过并行的全连接网络独立地处理这些嵌入。当嵌入通过网络传递时,它们逐渐融入了更多关于整个序列含义的信息。部分序列中最后一个令牌的输出嵌入通过线性变换和softmax函数映射到后续令牌可能值的概率分布上。有关变换器层和自注意力的更多信息可以在我们之前的一系列博客中找到。
Large language models: 大型语言模型 * Pretraining: 预训练
Masked self-attention: 掩码自注意力 * Is this model useful?: 这个模型有用吗? * Supervised fine-tuning: 监督微调 * Reinforcement learning from human feedback: 从人类反馈中进行强化学习
Reward model: 奖励模型 * Multiple comparisons: 多重比较 * Using the reward model: 使用奖励模型 * Practical matters: 实用问题 * Direct Preference Optimization: 直接偏好优化 * Summary: 总结