

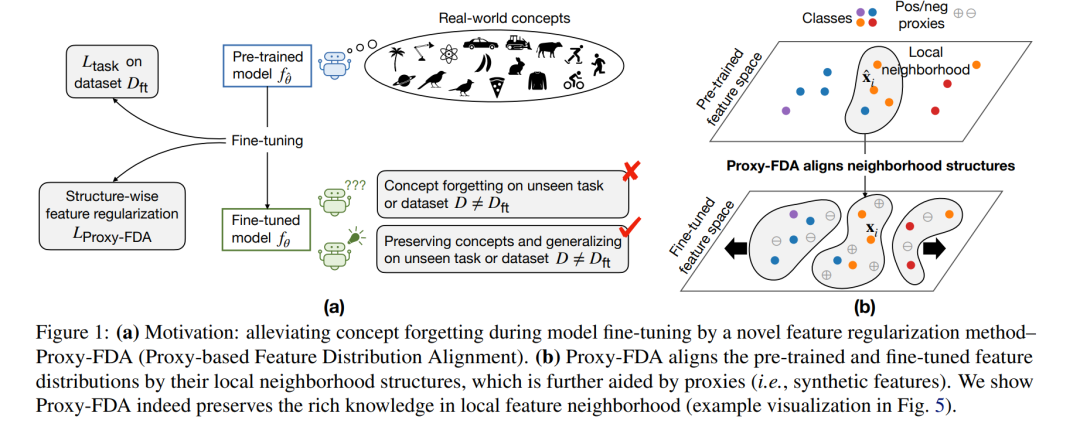
视觉基础模型在大规模数据上预训练后,能够编码现实世界概念的丰富表示,并可通过微调适配到下游任务。然而,在某一任务上对基础模型进行微调,往往会引发概念遗忘(concept forgetting)的问题,导致模型在其他任务上的知识能力下降。近年来,一些鲁棒微调方法致力于缓解遗忘问题,同时不影响微调性能。这些方法通常通过匹配原始模型与微调模型的权重或特征对来保留知识。然而,这种逐点匹配(point-wise matching)可能过于强硬,忽视了特征邻域结构中所蕴含的丰富知识。 为此,我们提出了一种新颖的正则化方法 Proxy-FDA,能够显式保留特征空间中的结构化知识。Proxy-FDA 利用最近邻图(nearest neighbor graphs)在预训练与微调特征空间之间执行特征分布对齐(Feature Distribution Alignment),并通过动态生成的信息丰富的代理点(informative proxies)来增强数据多样性,从而进一步提升对齐效果。 实验结果表明,Proxy-FDA 在微调过程中显著降低了概念遗忘,并揭示了遗忘程度与一种分布距离度量(相比于 L2 距离)之间存在强相关性。此外,我们在多种微调设定(如端到端微调、少样本学习、持续微调)和不同任务(图像分类、图文描述、视觉问答)上验证了 Proxy-FDA 的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日