

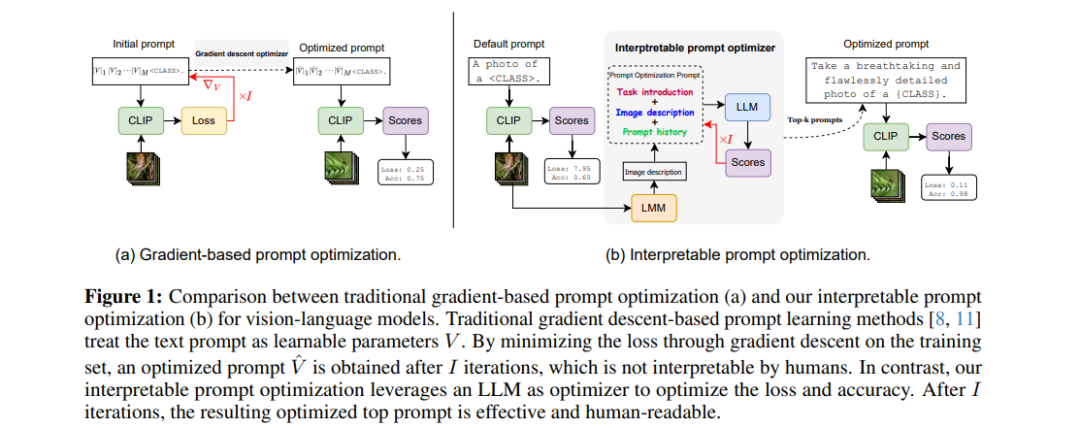
预训练的视觉-语言模型(如CLIP)已经成功适应了多种下游任务。然而,它们的性能很大程度上依赖于输入文本提示的具体性,这需要精心设计提示模板。当前的提示优化方法通常通过梯度下降来学习提示,将提示视为可调参数。然而,这些方法容易导致在训练时看到的基础类别上的过拟合,并且生成的提示通常不再为人类所理解。
本文提出了一种简单但可解释的提示优化器(IPO),它利用大型语言模型(LLM)动态生成文本提示。我们引入了一个提示优化提示(Prompt Optimization Prompt),它不仅引导LLM创建有效的提示,还存储了过去提示及其性能指标,提供了丰富的上下文信息。此外,我们结合了一个大型多模态模型(LMM),通过生成图像描述,基于视觉内容进行调整,增强了文本和视觉模态之间的交互。这样可以为数据集创建特定的提示,既提高了泛化性能,又保持了人类的可理解性。**
通过在11个数据集上的广泛测试,我们发现IPO不仅提升了现有基于梯度下降的提示学习方法的准确性,还显著提高了生成提示的可解释性。通过利用LLM的优势,我们的方法确保生成的提示保持人类可理解性,从而促进了视觉-语言模型的透明度和可监督性。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日