![]()
来自清华大学计算机科学与技术系、中国人民大学信息学院等机构的多位学者深入地研究了预训练模型的历史和发展趋势,并在这篇综述论文中从技术的角度理清了预训练的来龙去脉。
BERT 、GPT 等大规模预训练模型(PTM)近年来取得了巨大成功,成为人工智能领域的一个里程碑。由于复杂的预训练目标和巨大的模型参数,大规模 PTM 可以有效地从大量标记和未标记的数据中获取知识。通过将知识存储到巨大的参数中并对特定任务进行微调,巨大参数中隐式编码的丰富知识可以使各种下游任务受益。现在 AI 社区的共识是采用 PTM 作为下游任务的主干,而不是从头开始学习模型。
本文中,来自清华大学计算机科学与技术系、中国人民大学信息学院等机构的多位学者深入研究了预训练模型的历史,特别是它与迁移学习和自监督学习的特殊关系,揭示了 PTM 在 AI 发展图谱中的重要地位。
![]()
论文地址:http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf
清华大学教授、悟道项目负责人唐杰表示:这篇 40 多页的预训练模型综述基本上算是从技术上理清了预训练的来龙去脉。
![]()
此外,该研究还回顾了 PTM 的最新突破。这些突破得益于算力的激增和数据可用性的增加,目前正在向四个重要方向发展:设计有效的架构、利用丰富的上下文、提高计算效率以及进行解释和理论分析。最后,该研究讨论了关于 PTM 一系列有待解决的问题和研究方向,并且希望他们的观点能够对 PTM 的未来研究起到启发和推动作用。
![]()
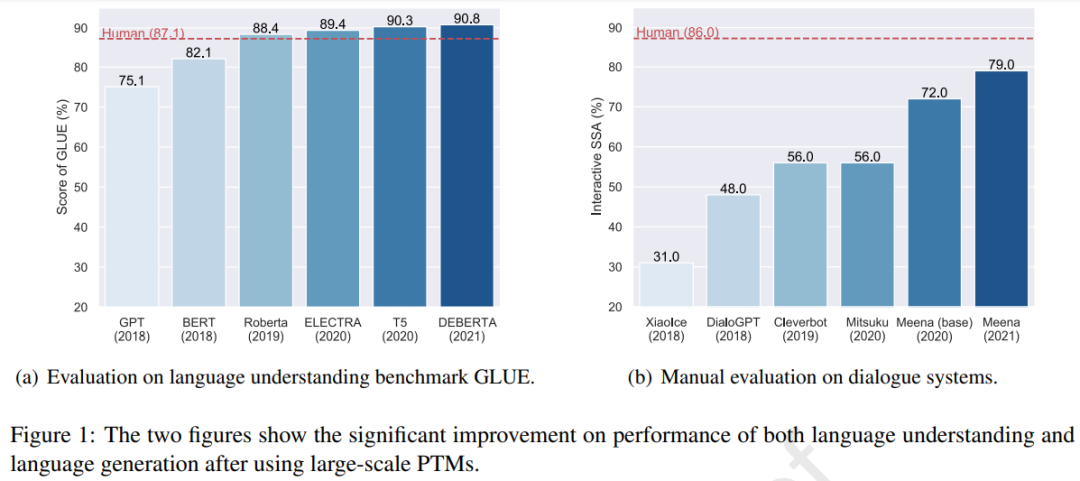
使用大规模 PTM 后语言理解和语言生成任务上性能出现了显著提升。
![]()
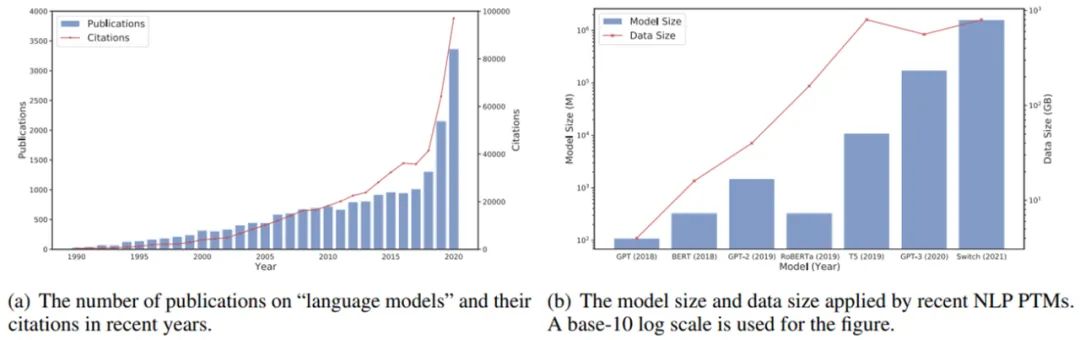
图(a)近年来语言模型相关的发表文章的数量,图(b)近年来应用 NLP PTM 后模型大小和数据大小的增长趋势。
最近 PTM 引起了研究人员的关注,但预训练并不是一种新颖的机器学习工具。事实上,预训练作为机器学习的一种范式已经发展很多年了。本节介绍了 AI 领域中预训练的发展,从早期监督预训练到当前的自监督预训练,了解这些有助于了解 PTM 的背景。
早期预训练的研究主要涉及迁移学习。迁移学习的研究很大程度上是因为人们可以依靠以前学到的知识来解决新问题,甚至取得更好的结果。更准确的说,迁移学习旨在从多个源任务中获取重要知识,然后将这些知识应用到目标任务中。
在迁移学习中,源任务和目标任务可能具有完全不同的数据域和任务设置,但处理这些任务所需的知识是一致的。一般来说,在迁移学习中有两种预训练方法被广泛探索:特征迁移和参数迁移。
在一定程度上,表征迁移和参数迁移奠定了 PTM 的基础。词嵌入是在特征迁移框架下建立起来的,被广泛应用于 NLP 任务的输入。
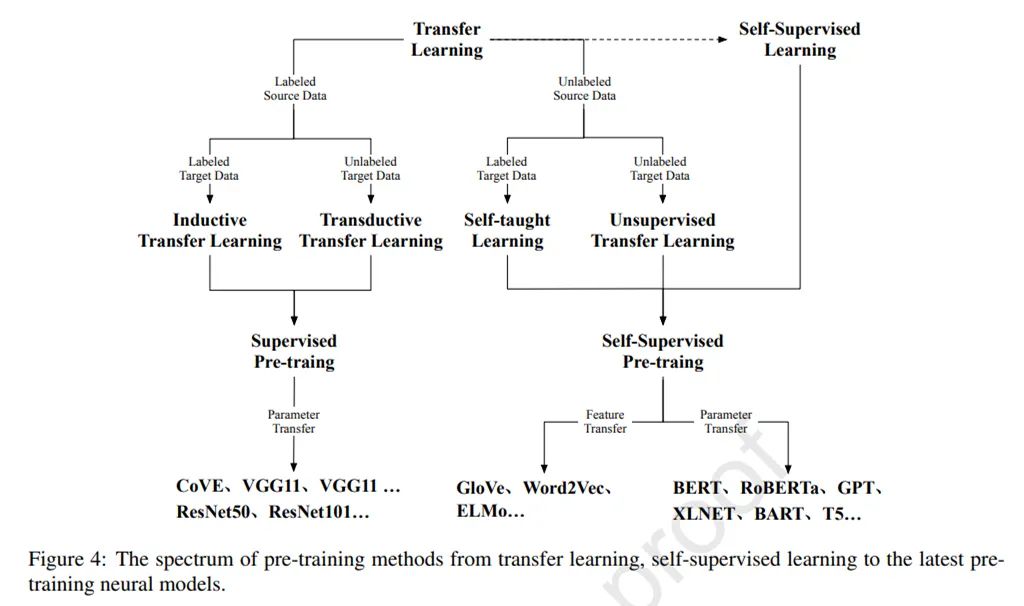
如图 4 所示,迁移学习可以分为四个子设置:归纳(inductive)迁移学习、transductive 迁移学习、自我(self-taught)学习和无监督迁移学习。
![]()
在这四种设置中,归纳和 transductive 设置是研究的核心,因为这两种设置旨在将知识从有监督的源任务迁移到目标任务。
自监督学习和无监督学习在它们的设置上有许多相似之处。在一定程度上,
自监督学习可以看作是无监督学习的一个分支,因为它们都适用于未标记的数据
。然而,无监督学习主要侧重于检测数据模式(例如,聚类、社区发现和异常检测),而自监督学习仍处于监督设置(例如分类和生成)的范式中。
自监督学习的发展使得对大规模无监督数据进行预训练成为可能。与作为深度学习时代 CV 基石的监督预训练相比,自监督预训练在 NLP 领域取得了巨大进步。
随着用于 NLP 任务的 PTM 的最新进展,基于 Transformer 的 PTM 作为 NLP 任务的主干已成为流程标准。受 NLP 中自监督学习和 Transformers 成功的启发,一些研究人员探索了自监督学习和 Transformers 用于 CV 任务。这些初步努力表明,自监督学习和 Transformer 可以胜过传统的有监督 CNN。
论文的第三部分从占主导地位的基本神经架构 Transformer 开始,然后介绍了两个具有里程碑意义的基于 Transformer 的 PTM,GPT 和 BERT,它们分别使用自回归语言建模和自编码语言建模作为预训练目标。这部分的最后简要回顾了 GPT 和 BERT 之后的典型变体,以揭示 PTM 的最新发展。
在 Transformer 之前,RNN 长期以来一直是处理序列数据(尤其是自然语言)的典型神经网络。与 RNN 相比,Transformer 是一种编码器 - 解码器结构,它应用了自注意力机制,可以并行建模输入序列的所有词之间的相关性。
在 Transformer 的编码和解码阶段,Transformer 的自注意力机制计算所有输入词的表征。下图 5 给出了一个示例,其中自注意力机制准确地捕获了「Jack」和「he」之间的参考关系,从而产生了最高的注意力分数。
![]()
由于突出的性质,Transformer 逐渐成为自然语言理解和生成的标准神经架构。
GPT 是第一个将现代 Transformer 架构和自监督预训练目标结合的模型。实验表明,GPT 在几乎所有 NLP 任务上都取得了显著的成功,包括自然语言推断、问答等。
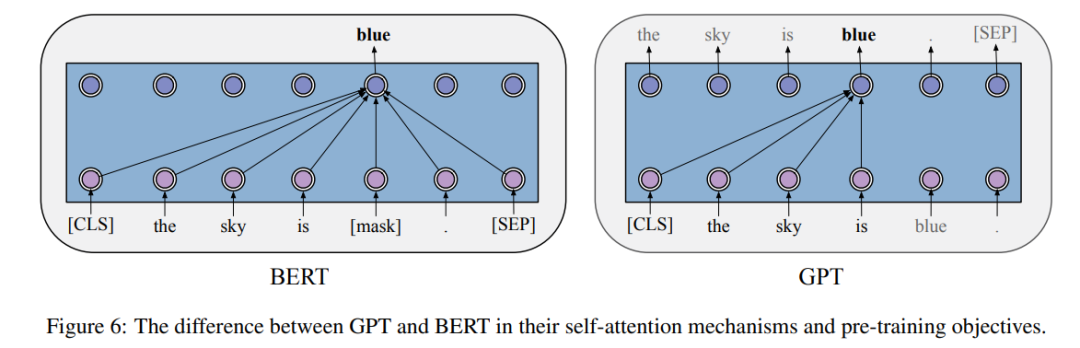
在 GPT 的预训练阶段,每个词的条件概率由 Transformer 建模。如下图 6 所示,对于每个词,GPT 通过对其前一个词应用多头自注意力操作,再通过按位置的前馈层来计算其概率分布。
![]()
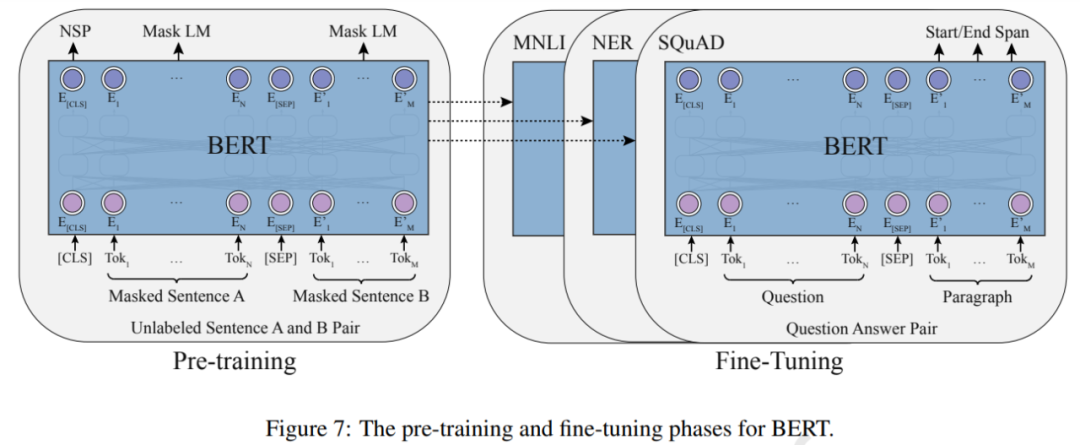
BERT 的出现也极大地推动了 PTM 领域的发展。理论上,不同于 GPT ,BERT 使用双向深度 Transformer 作为主要结构。还有两个独立的阶段可以使 BERT 适应特定任务,即预训练和微调(如下图 7 所示)。
![]()
经过预训练,BERT 可以获得下游任务的稳健参数。GPT 之后,BERT 在 17 个不同的 NLP 任务上进一步取得了显著的提升,包括 SQuAD(优于人类的表现)、GLUE(7.7% 的绝对提升)、MNLI(4.6% 的绝对提升)等。
在 GPT 和 BERT 之后也出现了一些改进模型,例如 RoBERTa 和 ALBERT。
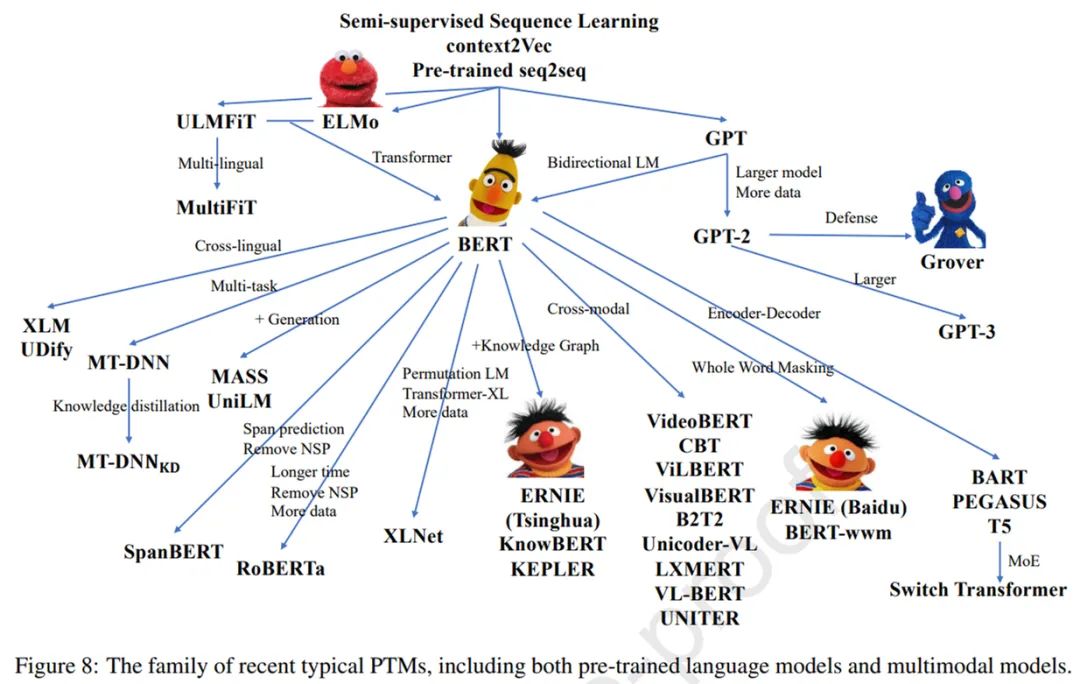
如下图 8 所示,为了更好地从未标记的数据中获取知识,除了 RoBERTa 和 ALBERT 之外,近年来还提出了各种 PTM。一些工作改进了模型架构并探索了新的预训练任务,例如 XLNet、MASS、SpanBERT 和 ELECTRA。
![]()
在这一部分中,论文更深入地探究了 after-BERT PTM。基于 Transformer 的 PTM 的成功激发了一系列用于自然语言及其他序列建模的新架构。一般来说,所有用于语言预训练的 after-BERT Transformer 架构都可以被归类为两个动机:统一序列建模和认知启发架构。此外,论文还在第三小节中简述了其他重要的 BERT 变体,它们主要侧重于改进自然语言理解。
研究者发现,一系列新架构都在寻求将不同类型的语言任务与一个 PTM 统一起来。论文中阐述了这一方面的发展,并探讨了它们为自然语言处理的统一带来的灵感。
结合自回归和自编码建模,包括 XLNet (Yang 等, 2019) 和 MPNet (Song 等, 2020)。除了排列语言建模,还有一个方向是多任务训练,例如 UniLM (Dong 等, 2019)。最近,GLM(Du 等,2021)提出了一种更优雅的方法来结合自回归和自编码。
有一些模型应用泛化的编码器 - 解码器,包括 MASS (Song 等, 2019)、T5 (Raffel 等, 2020)、BART (Lewis 等, 2020a) 以及在典型 seq2seq 任务中指定的模型,例如 PEGASUS (Zhang 等,2020a)和 PALM(Bi 等,2020 )。
为了追求人类水平的智能,了解我们认知功能的宏观架构,包括决策、逻辑推理、反事实推理和工作记忆 (Baddeley, 1992) 至关重要。论文中概述了受认知科学启发的新尝试,并重点阐述了可维持的工作记忆和可持续的长期记忆。
可维持的工作记忆,包括基于 Transformer 的一些架构,例如 Transformer-XL (Dai 等, 2019)、CogQA (Ding 等, 2019) 和 CogLTX (Ding 等, 2020)。
可持续的长期记忆。REALM (Guu 等, 2020) 是探索如何为Transformer构建可持续外部记忆的先驱。RAG (Lewis 等, 2020b) 将掩码预训练扩展到自回归生成。
除了统一序列建模和构建受认知启发的架构以外,当前大多数研究都集中在优化 BERT 的架构以提高语言模型在自然语言理解方面的性能。
一系列工作旨在改进掩码策略,可以将其视为某种数据增强(Gu 等, 2020),包括 SpanBERT (Joshi 等, 2020)、ERNIE (Sun 等, 2019b,c)、NEZHA (Wei 等, 2019) 和 Whole Word Masking (Cui 等, 2019)。
另一个有趣的做法是将掩码预测目标更改为更困难的目标,例如 ELECTRA(Clark 等,2020)。
本节介绍了一些利用多源异构数据的典型 PTM,包括多语言 PTM、多模态 PTM 和知识增强型 PTM。
在大规模英语语料库上训练的语言模型在许多基准测试中取得了巨大成功。然而,我们生活在一个多语言的世界中,并且由于所需的成本和数据量,为每种语言训练一个大型语言模型并不是一个最优的解决方案。因此,训练一个模型来学习多语言表征而不是单语表征可能是更好的方法。
在 BERT 之前,一些研究人员已经探索了多语言表征。学习多语言表征主要有两种方法:一种是通过参数共享来学习;另一种是学习与语言无关的约束。这两种方式都使模型能够应用于多语言场景,但仅限于特定任务。
BERT 的出现表明,先对一般的自监督任务进行预训练,然后对特定的下游任务进行微调的框架是可行的。这促使研究人员设计任务来预训练具有多功能的多语言模型。根据任务目标,多语言任务可分为理解任务和生成任务。
一些理解任务首先被用在非平行多语言语料库上预训练多语言 PTM。然而,MMLM( multilingual masked language modeling )任务不能很好地利用平行语料库。
除了 TLM( translation language modeling ),还有一些其他有效的方法可以从平行语料库中学习多语言表征,如 Unicoder(Huang et al.,2019a)、ALM(Yang et al.,2020)、InfoXLM(Chi et al.,2020b)、HICTL(Wei et al.,2021)和 ERNIE-M(Ouyang et al.,2020)。
此外,该研究还广泛探索了多语言 PTM 的生成模型,如 MASS(Song et al,2019 年)、mBART(Liu et al,2020c)。
基于图像 - 文本的 PTM,目前的解决方案是采用视觉 - 语言 BERT。ViLBERT(Lu et al,2019 年)是一个学习图像和语言的 task-agnostic 联合表征模型。它使用三个预训练任务:MLM、句子 - 图像对齐(SIA)和掩码区域分类(MRC)。另一方面,VisualBERT(Li et al,2019 年)扩展了 BERT 架构。
一些多模态 PTM 设计用于解决特定任务,如 VQA。B2T2(Alberti et al,2019 年)是主要关注 VQA 的模型。LP(Zhou et al,2020a)专注于 VQA 和图像字幕。此外,UNITER(Chen et al,2020e)学习两种模式之间的统一表征。
OpenAI 的 DALLE (Ramesh et al., 2021) 、清华大学和 BAAI 的 CogView (Ding et al., 2021) 向条件零样本图像生成迈出了更大的一步。
最近,CLIP (Radford et al., 2021) 和 WenLan (Huo et al., 2021) 探索扩大网络规模数据以进行 V&L 预训练并取得了巨大成功。
结构化知识的典型形式是知识图谱。许多工作试图通过集成实体和关系嵌入或其与文本的对齐来增强 PTM。
Wang et al.(2021) 基于维基数据实体描述的预训练模型,将语言模型损失和知识嵌入损失结合在一起以获得知识增强表征。一个有趣的尝试是 OAGBERT (Liu et al., 2021a),它在 OAG(open academic graph) (Zhang et al., 2019a) 中集成了异构结构知识,并且涵盖了 7 亿个异构实体和 20 亿个关系。
与结构化知识相比,非结构化知识更完整,但噪声也更大。
在介绍了 PTM 在各种 NLP 任务上的卓越性能之外,研究者还花篇幅解释了 PTM 的行为,包括理解 PTM 的工作方式,揭示 PTM 捕获的模式。他们探索了 PTM 的几个重要属性——知识、稳健性和结构稀疏性 / 模块性,还回顾了 PTM 理论分析方面的开创性工作。
关于 PTM 的知识,PTM 捕获的隐式知识大致分为两类,分别是语言知识和世界知识。关于 PTM 的稳健性,当研究人员为现实世界的应用部署 PTM 时,稳健性已经成为了一个严重的安全威胁。
最后,研究者指出,在现有工作的基础上,未来 PTM 可以从以下几个方面得到进一步发展:
架构和预训练方法
多语言和多模态预训练
计算效率
理论基础
模型边缘学习
认知学习
新型应用。
事实上,研究社区在以上几个方向上都做了大量努力,也取得了一些最新的进展。但应看到,还有一些问题需要得到进一步解决。
https://twitter.com/ringo_ring/status/1434356217208623106
https://sci-hub.ru/donate