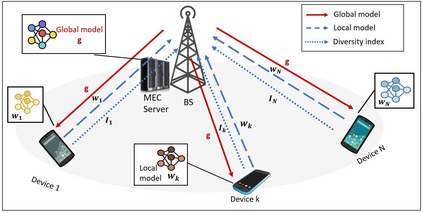
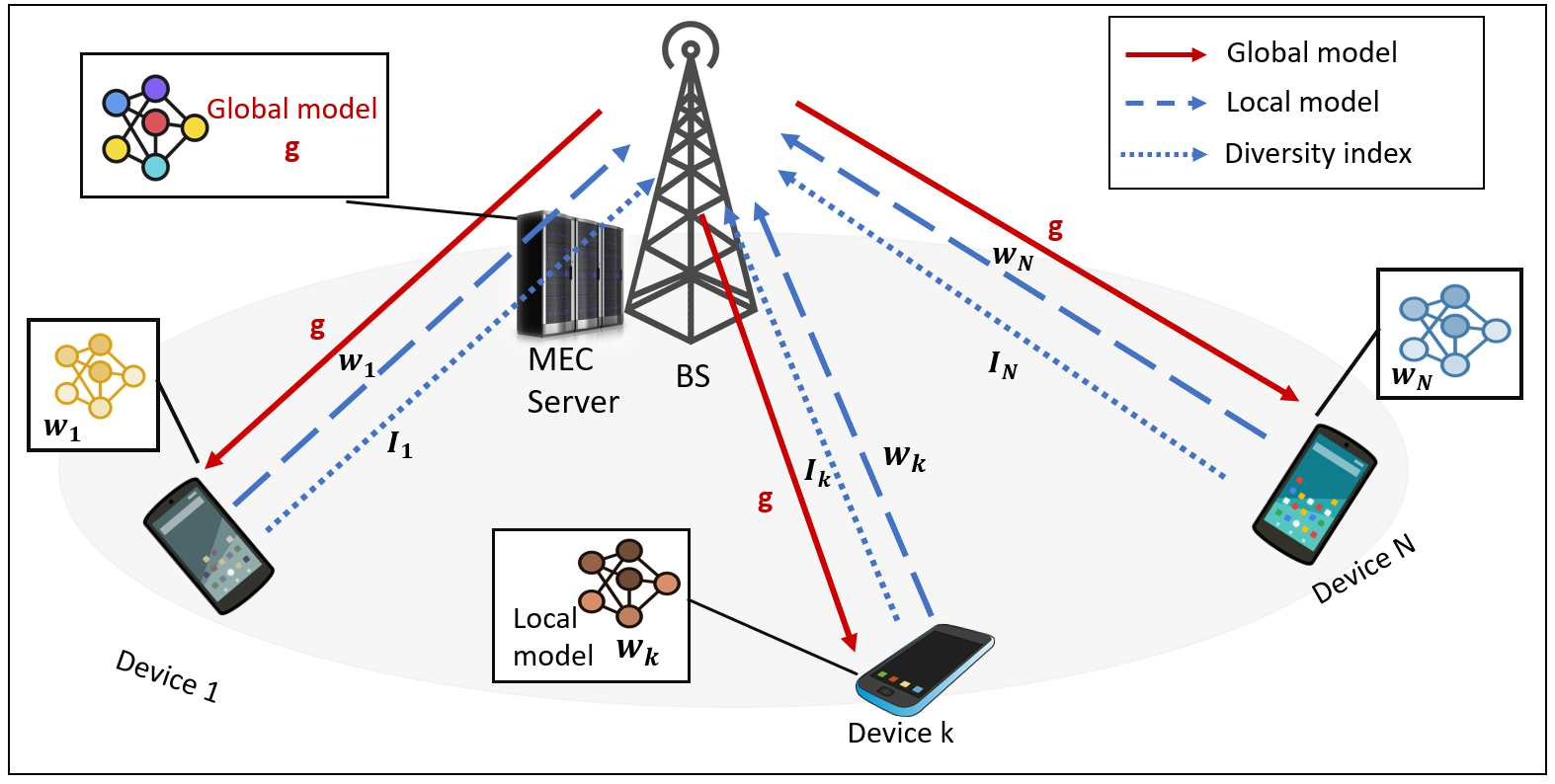
Federated Edge Learning (FEEL) involves the collaborative training of machine learning models among edge devices, with the orchestration of a server in a wireless edge network. Due to frequent model updates, FEEL needs to be adapted to the limited communication bandwidth, scarce energy of edge devices, and the statistical heterogeneity of edge devices' data distributions. Therefore, a careful scheduling of a subset of devices for training and uploading models is necessary. In contrast to previous work in FEEL where the data aspects are under-explored, we consider data properties at the heart of the proposed scheduling algorithm. To this end, we propose a new scheduling scheme for non-independent and-identically-distributed (non-IID) and unbalanced datasets in FEEL. As the data is the key component of the learning, we propose a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. In fact, the data collected by the devices depends on the local environment and usage pattern. Thus, the datasets vary in size and distributions among the devices. In the proposed algorithm, we consider both data and resource perspectives. In addition to minimizing the completion time of FEEL as well as the transmission energy of the participating devices, the algorithm prioritizes devices with rich and diverse datasets. We first define a general framework for the data-aware scheduling and the main axes and requirements for diversity evaluation. Then, we discuss diversity aspects and some exploitable techniques and metrics. Next, we formulate the problem and present our FEEL scheduling algorithm. Evaluations in different scenarios show that our proposed FEEL scheduling algorithm can help achieve high accuracy in few rounds with a reduced cost.
翻译:联邦边缘学习(FEEL) 涉及在边缘设备之间对机器学习模型进行协作培训,在无线边缘网络中安排服务器。由于频繁的模型更新,需要使感觉适应通信带宽有限、边缘设备能量稀少以及边缘设备数据分布的统计差异性。因此,有必要仔细安排一组用于培训和上传模型的设备。与以往在数据方面探索不足的感知方面开展的工作不同,我们考虑数据属性是拟议列表算法的核心。为此,我们建议为不独立和身份上分布的服务器(非IID)和感知中不平衡的数据集制定新的时间安排方案。由于数据是学习的关键组成部分,我们提出了一套关于无线调度算法中数据特性的新考虑因素。事实上,这些装置所收集的数据取决于当地环境和使用模式。因此,在拟议的算法中,数据集在规模和结构分配方面各不相同。我们考虑的数据和资源视角,在不独立和识别高度分布中,除了将数据排序的当前数据排序和排序中,我们还将数据排序的排序和排序的排序过程也缩小了我们当前数据排序的顺序,然后将数据排序中,我们将数据排序作为数据排序的排序的排序中,然后将数据用于数据排序。