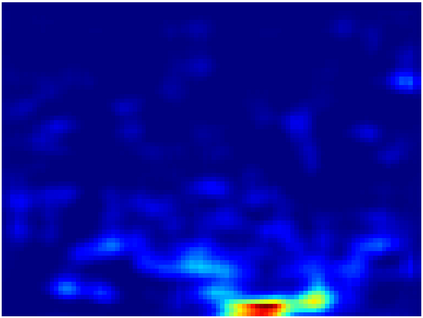
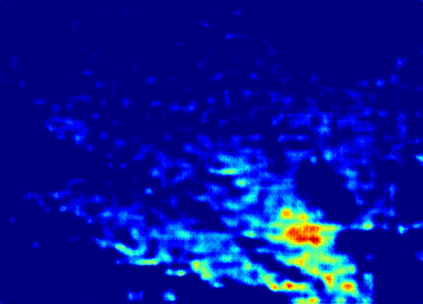
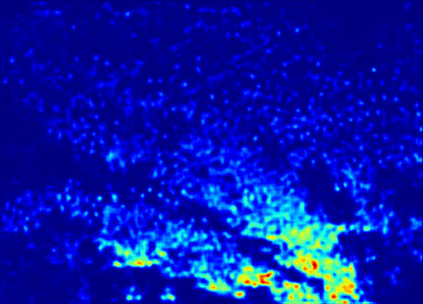
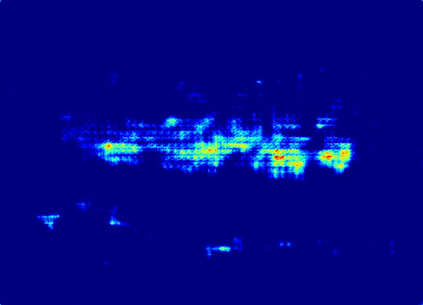
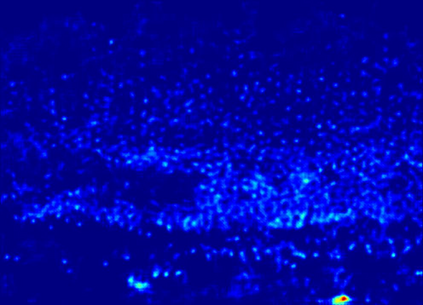
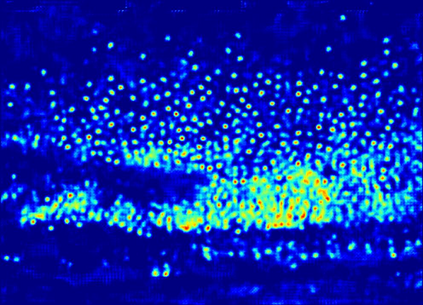
Recently, crowd counting using supervised learning achieves a remarkable improvement. Nevertheless, most counters rely on a large amount of manually labeled data. With the release of synthetic crowd data, a potential alternative is transferring knowledge from them to real data without any manual label. However, there is no method to effectively suppress domain gaps and output elaborate density maps during the transferring. To remedy the above problems, this paper proposes a Domain-Adaptive Crowd Counting (DACC) framework, which consists of a high-quality image translation and density map reconstruction. To be specific, the former focuses on translating synthetic data to realistic images, which prompts the translation quality by segregating domain-shared/independent features and designing content-aware consistency loss. The latter aims at generating pseudo labels on real scenes to improve the prediction quality. Next, we retrain a final counter using these pseudo labels. Adaptation experiments on six real-world datasets demonstrate that the proposed method outperforms the state-of-the-art methods.
翻译:最近,使用监督学习进行人群计数的工作取得了显著的改进。 然而,大多数计数器都依靠大量手工标签数据。 随着合成人群数据的发布,一个潜在的替代办法是将知识从他们那里转移到没有手工标签的真实数据中。然而,在传输过程中,没有办法有效地消除域间差距和产出详细密度图。为了解决上述问题,本文件建议采用一个域-自动计票(DACC)框架,其中包括高质量的图像翻译和密度图重建。具体地说,前者侧重于将合成数据转换为现实图像,通过分离共享域/独立功能和设计内容识别一致性损失来刺激翻译质量。后者的目的是在真实场上生成假标签,以提高预测质量。接下来,我们用这些假标签重新设置最后的反差。六个真实世界数据集的适应实验表明,拟议方法超越了最新的方法。