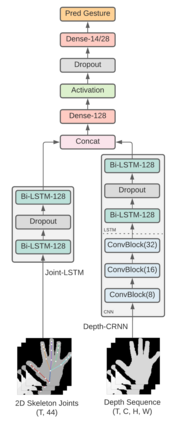
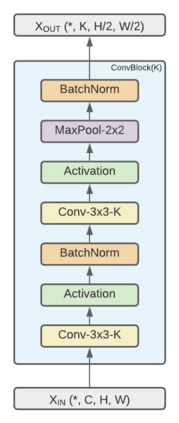
The dynamic hand gesture recognition task has seen studies on various unimodal and multimodal methods. Previously, researchers have explored depth and 2D-skeleton-based multimodal fusion CRNNs (Convolutional Recurrent Neural Networks) but have had limitations in getting expected recognition results. In this paper, we revisit this approach to hand gesture recognition and suggest several improvements. We observe that raw depth images possess low contrast in the hand regions of interest (ROI). They do not highlight important fine details, such as finger orientation, overlap between the finger and palm, or overlap between multiple fingers. We thus propose quantizing the depth values into several discrete regions, to create a higher contrast between several key parts of the hand. In addition, we suggest several ways to tackle the high variance problem in existing multimodal fusion CRNN architectures. We evaluate our method on two benchmarks: the DHG-14/28 dataset and the SHREC'17 track dataset. Our approach shows a significant improvement in accuracy and parameter efficiency over previous similar multimodal methods, with a comparable result to the state-of-the-art.
翻译:动态手势识别任务已经看到关于各种单一方式和多式联运方法的研究。以前,研究人员已经探索了深度和基于2D-skeleton的多式聚合CRNNs(革命常态神经网络),但在获得预期的识别结果方面有局限性。在本文件中,我们重新审视了这一方法以手势识别并提出若干改进意见。我们发现,原始深度图像在感兴趣的手部区域(ROI)中差异不大。它们并不突出重要的细小细节,如手指取向、手指和手掌之间重叠或多个手指之间重叠。因此,我们建议将深度值量化为几个离散区域,从而在手部的几个关键部分之间形成更大的对比。此外,我们提出了解决现有多式聚合CRNNN结构中差异很大的问题的若干方法。我们根据两个基准评估我们的方法:DHG-14/28数据集和SHREC'17轨道数据集。我们的方法表明,比以往类似的多式联运方法的准确性和参数效率有了显著提高,其结果与目前的情况相似。