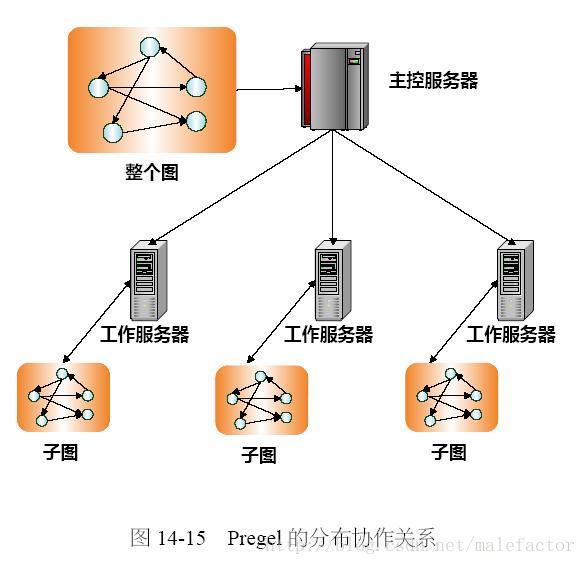
The initial adoption of knowledge graphs by Google and later by big companies has increased their adoption and popularity. In this paper we present a formal model for three different types of knowledge graphs which we call RDF-based graphs, property graphs and wikibase graphs. In order to increase the quality of Knowledge Graphs, several approaches have appeared to describe and validate their contents. Shape Expressions (ShEx) has been proposed as concise language for RDF validation. We give a brief introduction to ShEx and present two extensions that can also be used to describe and validate property graphs (PShEx) and wikibase graphs (WShEx). One problem of knowledge graphs is the large amount of data they contain, which jeopardizes their practical application. In order to palliate this problem, one approach is to create subsets of those knowledge graphs for some domains. We propose the following approaches to generate those subsets: Entity-matching, simple matching, ShEx matching, ShEx plus Slurp and ShEx plus Pregel which are based on declaratively defining the subsets by either matching some content or by Shape Expressions. The last approach is based on a novel validation algorithm for ShEx based on the Pregel algorithm that can handle big data graphs and has been implemented on Apache Spark GraphX.
翻译:Google和大公司最初采用知识图表的做法提高了它们的采用率和受欢迎度。在本文中,我们为三种不同类型的知识图表提供了一个正式模型,我们称之为RDF的图形、属性图和维基数据库图。为了提高知识图表的质量,似乎有几种方法可以描述和验证其内容。形状表达(ShEx)已被提议为RDF验证的简明语言。我们向 ShEx 简要介绍并提供了两个扩展,这些扩展也可用于描述和验证属性图表(PshEx)和维基数据库图表(WashEx) 。一个知识图表的问题在于它们所包含的大量数据,这危及它们的实际应用。为了勾画这一问题,一种方法是为某些领域创建这些知识图表的子集。我们建议了以下方法来生成这些子集:实体匹配、简单匹配、ShEx匹配、ShEx加Slurrp和ShEx加Pregel,这些扩展也可以用来描述和校验属性图(Pregel)。一个知识图表的问题是它们所包含的数据是大量数据图,它们中含有某些内容,或者由ShapeX Preal Ex 分析算法,这是基于S realalalalalalal的Sligal 进行的最新验证。最后的Sex Ex 和Slippalalalgalalal 。根据一个基于一个基于SHR Ex 和Appalus的Slippalalalalalalalal 。