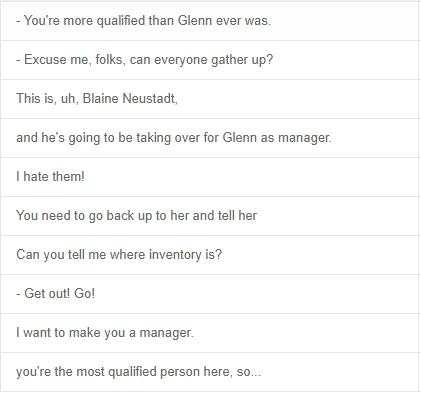
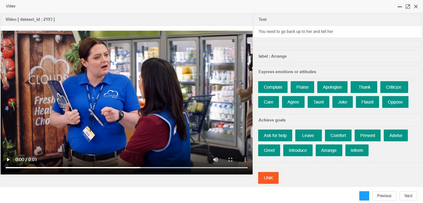
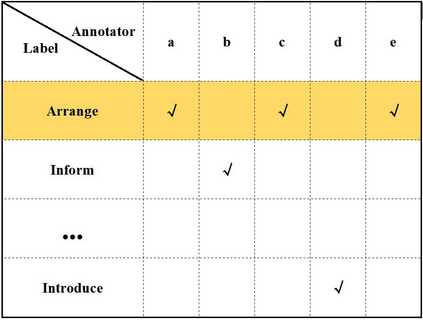
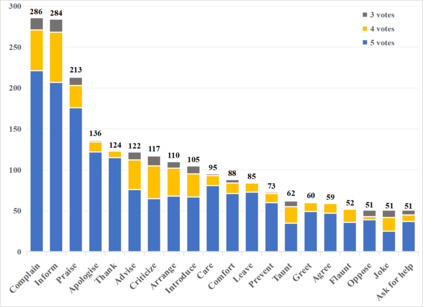
Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
翻译:在现实世界多式联运场景中,多式意向承认是理解人文的一项重要任务。由于基准数据集中只有文本信息,大多数现有意向承认方法在利用多式联运信息方面具有局限性,因为基准数据集中只有文本信息,本文件介绍了一套用于多式联运意向确认的新数据集(MIntRec),以解决这一问题。根据从电视系列《超级商店》中收集的数据,我们从每种模式中提取粗微和细微的混合意图分类;数据集由2 224个高质量的样本组成,包括文本、视频和音频模式,并在20个意向类别中提供多式说明。此外,我们在每个视频部分中提供一组附加说明的演讲者,并实现演讲者注解的自动程序。MIntRetarc有助于研究人员利用不同模式之间的关系来增强识别意向的能力。我们从每种模式中提取特征和模式的跨式互动,为此调整了三种强大的多式联运组合方法以建立基线。广泛的实验表明,采用非语言模式与只文本模式相比,取得了实质性的改进,显示了使用多式信息来确认意向的有效性。MontRetreal Reguils 和Mistratal 之间的差距表明最佳/humax