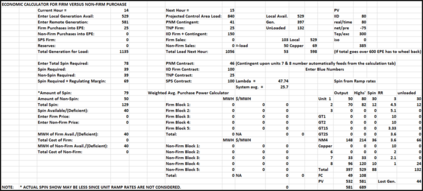
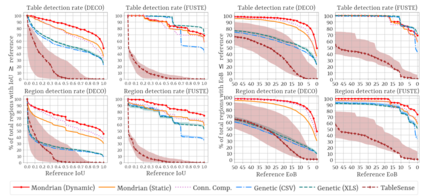
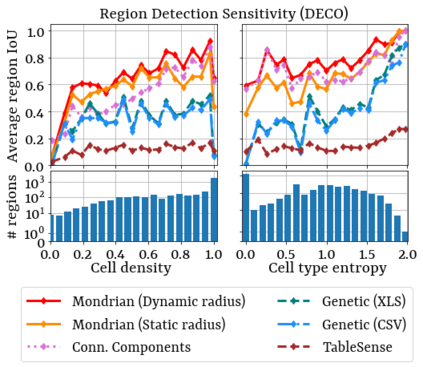
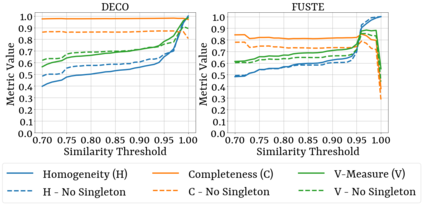
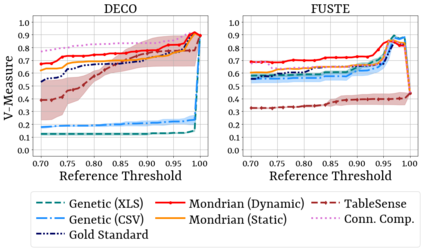
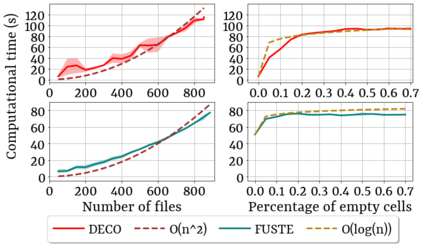
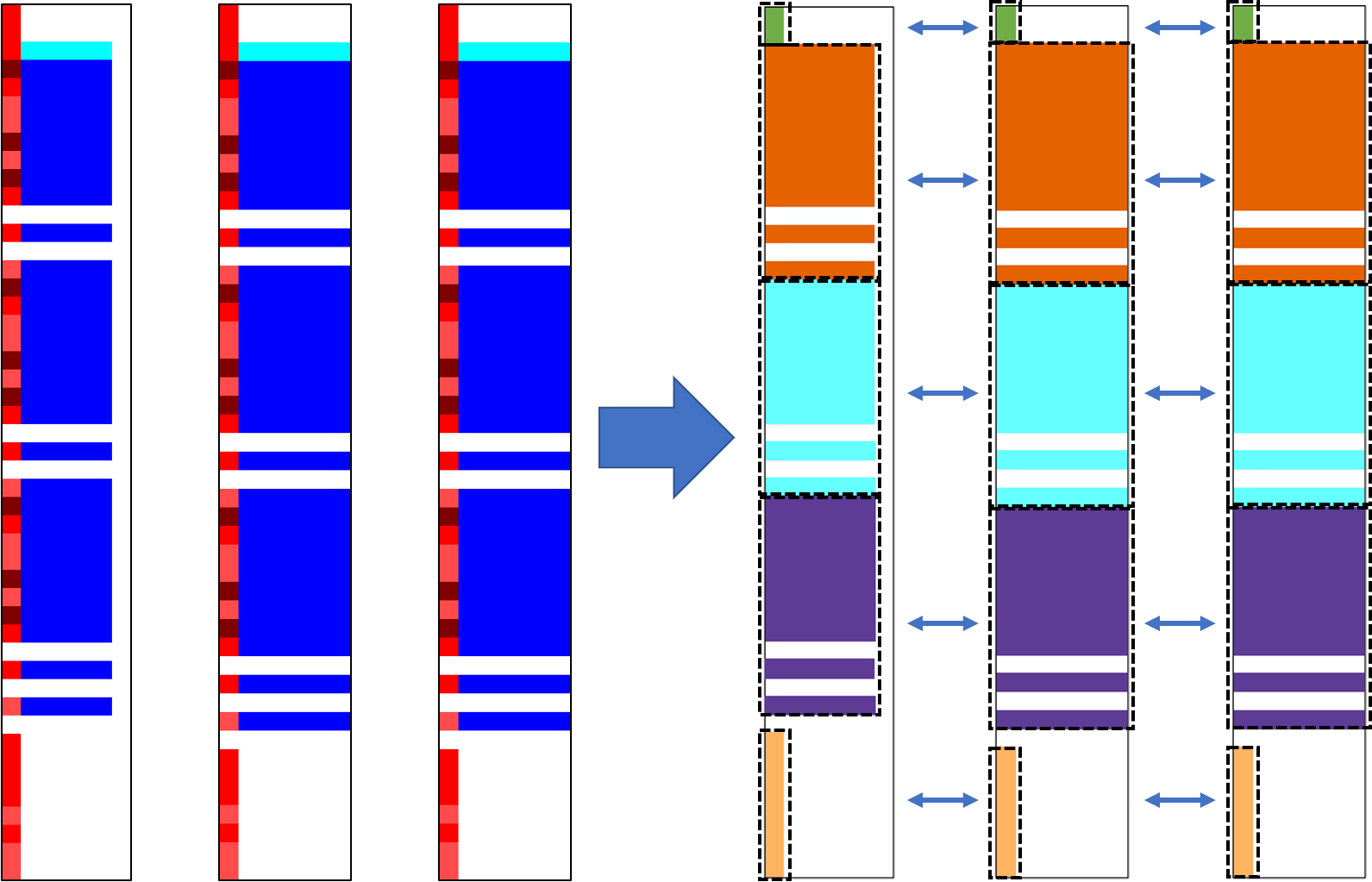
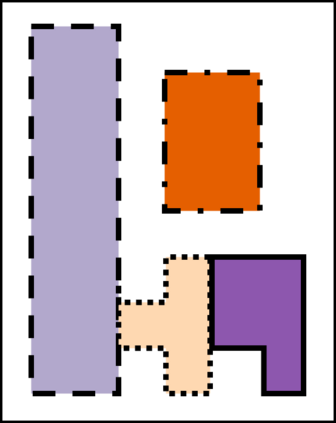Spreadsheets are among the most commonly used file formats for data management, distribution, and analysis. Their widespread employment makes it easy to gather large collections of data, but their flexible canvas-based structure makes automated analysis difficult without heavy preparation. One of the common problems that practitioners face is the presence of multiple, independent regions in a single spreadsheet, possibly separated by repeated empty cells. We define such files as "multiregion" files. In collections of various spreadsheets, we can observe that some share the same layout. We present the Mondrian approach to automatically identify layout templates across multiple files and systematically extract the corresponding regions. Our approach is composed of three phases: first, each file is rendered as an image and inspected for elements that could form regions; then, using a clustering algorithm, the identified elements are grouped to form regions; finally, every file layout is represented as a graph and compared with others to find layout templates. We compare our method to state-of-the-art table recognition algorithms on two corpora of real-world enterprise spreadsheets. Our approach shows the best performances in detecting reliable region boundaries within each file and can correctly identify recurring layouts across files.
翻译:电子表格是数据管理、分发和分析最常用的文件格式。 电子表格是数据管理、分发和分析最常用的文件格式之一。 它们的广泛使用使得收集大量数据变得容易, 但其灵活的布局结构使得自动分析难于进行大量准备。 实践者面临的常见问题之一是在单一的电子表格中存在多个独立的区域, 可能由重复的空格分隔。 我们定义了这样的文件“ 多区域” 文件。 在收集各种电子表格时, 我们可以看到一些共享相同的布局。 我们展示了蒙德里安方法, 以自动识别多个文件的布局模板, 并系统地提取相应的区域。 我们的方法由三个阶段组成: 首先, 每个文件以图像形式制作, 并检查可形成区域的元素; 然后, 使用组合算法, 将所识别的元素分组成区域; 最后, 每个文件布局都以图表形式出现, 并与其他文件的模板作比较。 我们比较了我们如何在两个实体企业电子表格的组合中进行最先进的表识别算法。 我们的方法显示每个文件内可靠区域边界的最佳表现, 并可以正确识别跨文件的重复布局。