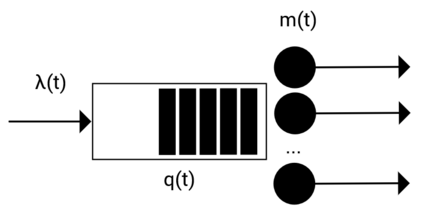
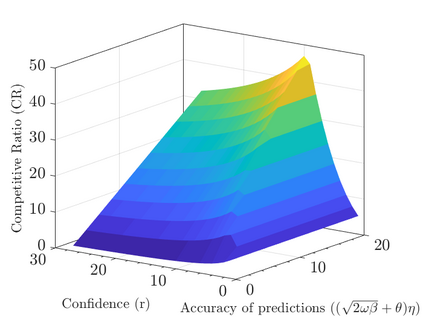
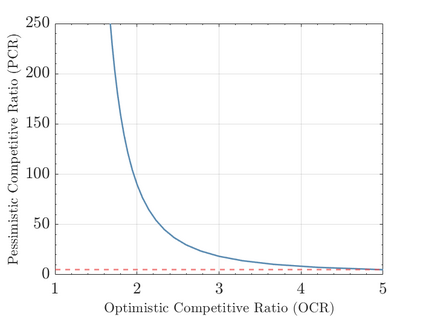
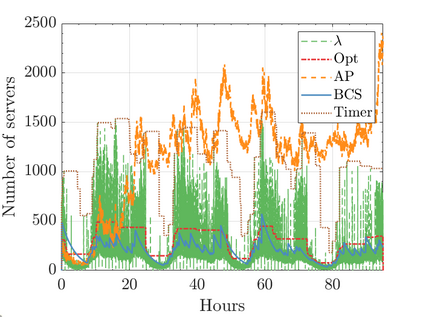
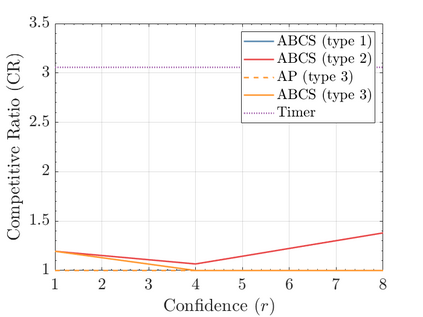
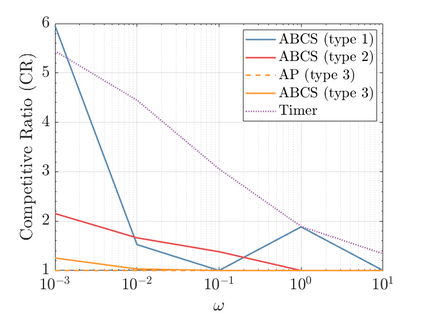
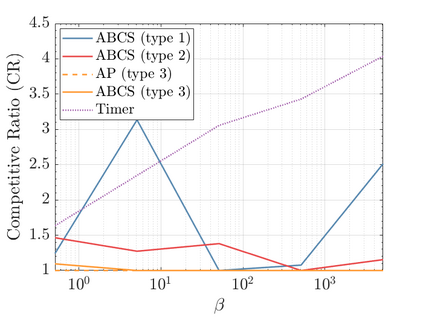
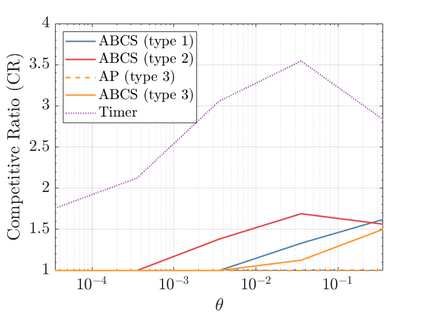
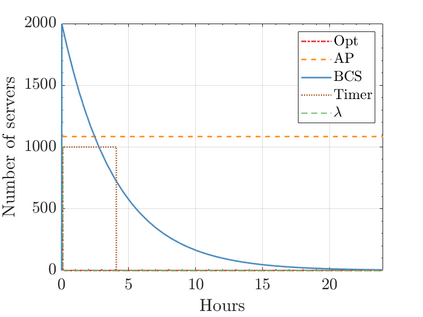
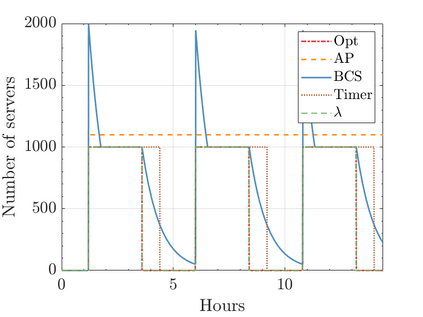
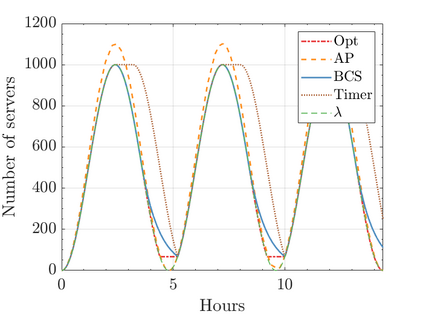
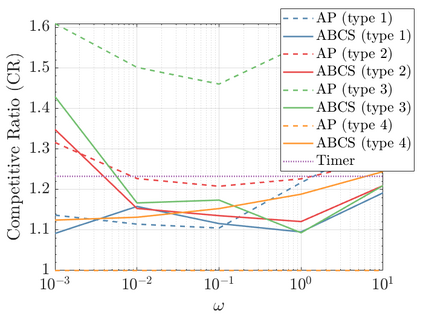
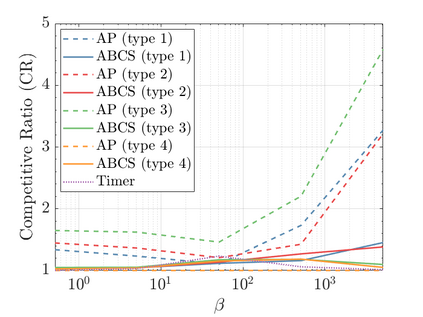
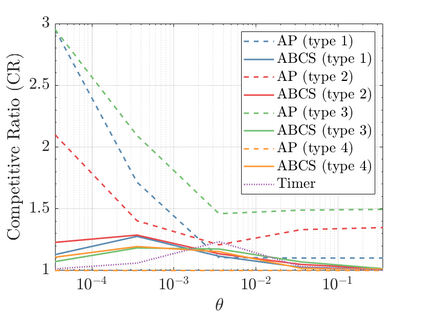
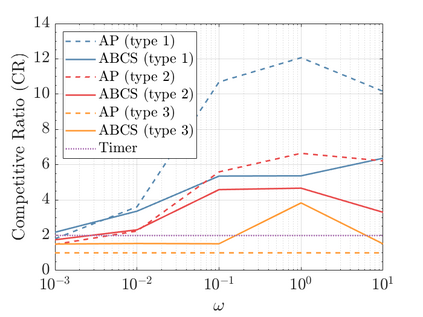
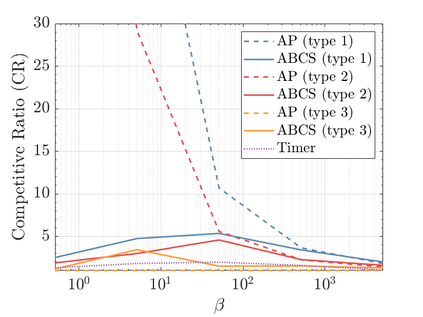
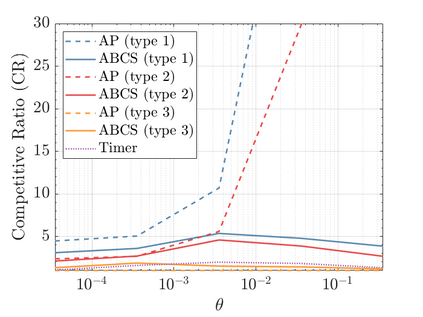
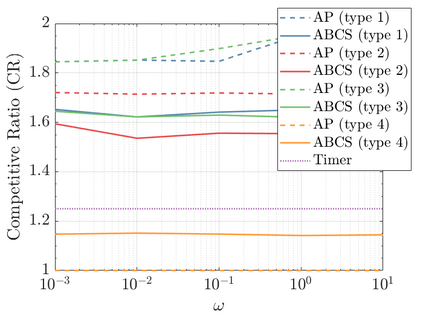
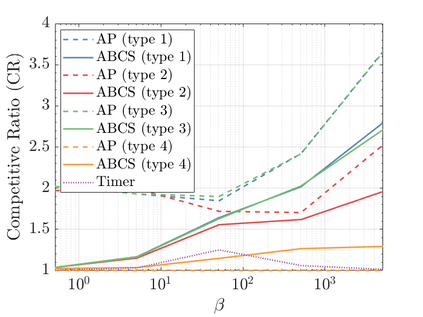
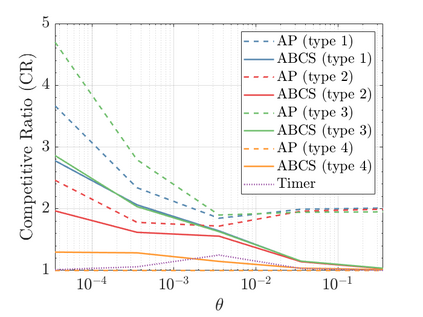
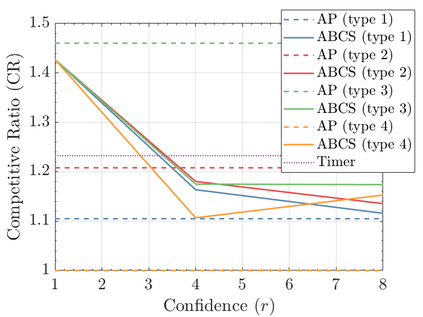
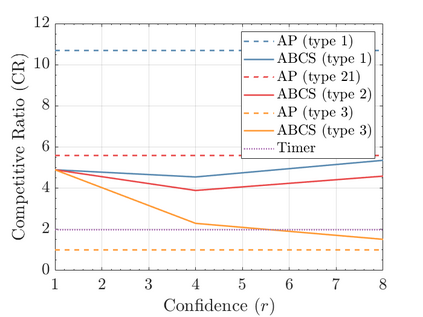
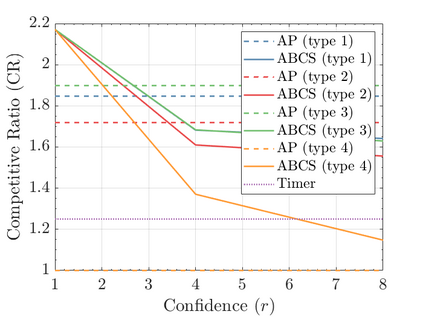
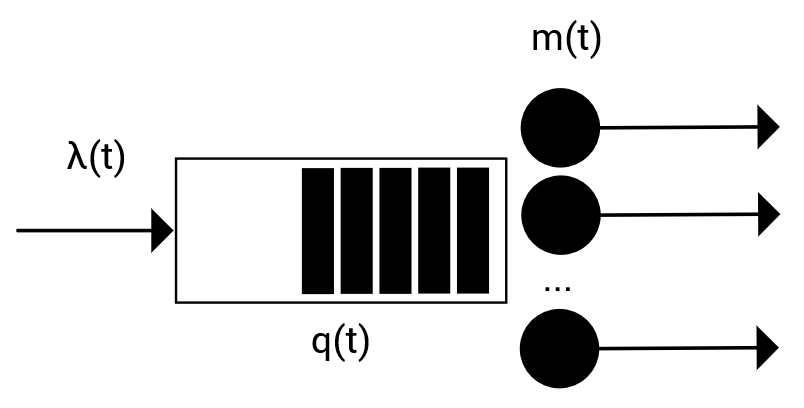
Modern data centers suffer from immense power consumption. The erratic behavior of internet traffic forces data centers to maintain excess capacity in the form of idle servers in case the workload suddenly increases. As an idle server still consumes a significant fraction of the peak energy, data center operators have heavily invested in capacity scaling solutions. In simple terms, these aim to deactivate servers if the demand is low and to activate them again when the workload increases. To do so, an algorithm needs to strike a delicate balance between power consumption, flow-time, and switching costs. Over the last decade, the research community has developed competitive online algorithms with worst-case guarantees. In the presence of historic data patterns, prescription from Machine Learning (ML) predictions typically outperform such competitive algorithms. This, however, comes at the cost of sacrificing the robustness of performance, since unpredictable surges in the workload are not uncommon. The current work builds on the emerging paradigm of augmenting unreliable ML predictions with online algorithms to develop novel robust algorithms that enjoy the benefits of both worlds. We analyze a continuous-time model for capacity scaling, where the goal is to minimize the weighted sum of flow-time, switching cost, and power consumption in an online fashion. We propose a novel algorithm, called Adaptive Balanced Capacity Scaling (ABCS), that has access to black-box ML predictions, but is completely oblivious to the accuracy of these predictions. In particular, if the predictions turn out to be accurate in hindsight, we prove that ABCS is $(1+\varepsilon)$-competitive. Moreover, even when the predictions are inaccurate, ABCS guarantees a bounded competitive ratio. The performance of the ABCS algorithm on a real-world dataset positively support the theoretical results.
翻译:现代数据中心受到巨大的电力消耗的影响。 互联网交通中心的反复无常行为迫使数据中心在工作量突然增加的情况下以闲置服务器的形式维持过剩的能力。 由于闲置服务器仍然消耗大量峰值能源,数据中心操作员在能力规模解决方案方面投入了大量资金。 简言之, 这些目标是在需求低的情况下停止服务器,并在工作量增加时再次激活服务器。 要做到这一点, 算法就需要在电力消耗、流动时间和转换成本之间达成微妙的平衡。 在过去的十年里, 研究界开发了具有最坏保证的竞争性在线算法。 在历史数据模式的存在中, 机器学习(ML)预测的处方通常比这种竞争性算法要好得多。 但是,由于工作量的不可预测性突变,因此,它们的目标是牺牲了功能的稳健健性。 目前的工作建立在以在线算法来增加不可靠的 ML预测的模型之上, 以开发既能让两个世界都受益的新的稳健算法。 我们分析一个持续的时间模型, 以能力缩放, 目标就是将流动准确性总和不断升级的准确性计算结果, 将S 。 不断更新的S 。