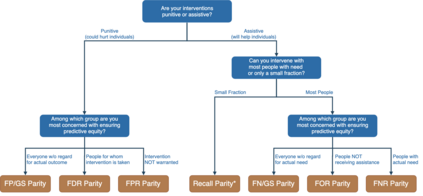
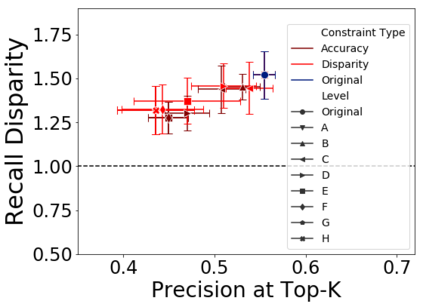
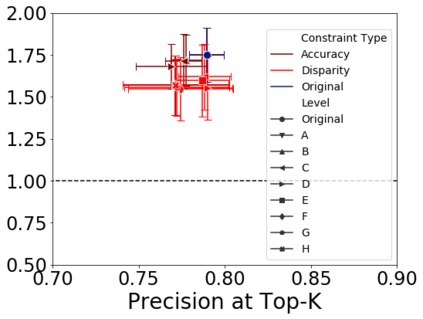
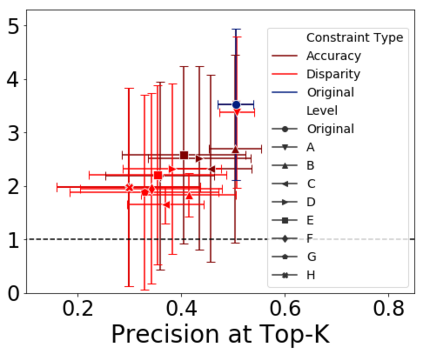
Applications of machine learning (ML) to high-stakes policy settings -- such as education, criminal justice, healthcare, and social service delivery -- have grown rapidly in recent years, sparking important conversations about how to ensure fair outcomes from these systems. The machine learning research community has responded to this challenge with a wide array of proposed fairness-enhancing strategies for ML models, but despite the large number of methods that have been developed, little empirical work exists evaluating these methods in real-world settings. Here, we seek to fill this research gap by investigating the performance of several methods that operate at different points in the ML pipeline across four real-world public policy and social good problems. Across these problems, we find a wide degree of variability and inconsistency in the ability of many of these methods to improve model fairness, but post-processing by choosing group-specific score thresholds consistently removes disparities, with important implications for both the ML research community and practitioners deploying machine learning to inform consequential policy decisions.
翻译:近些年来,机器学习应用于高度政策环境 -- -- 如教育、刑事司法、保健和社会服务提供 -- -- 的运用迅速发展,引发了关于如何确保这些系统产生公平结果的重要对话。机器学习研究界以一系列广泛的提高质量战略对这一挑战作出了反应,提出了多种促进公平模式的战略,但尽管已经开发了许多方法,但在现实世界环境中评价这些方法的经验性工作却很少。在这里,我们试图通过调查在多种实际世界公共政策和社会福利问题中多点使用的若干方法的绩效来填补这一研究差距。在这些问题中,我们发现许多这些方法在提高模型公平性的能力方面存在很大差异和不一致,但通过选择特定群体分数的阈值来不断消除差距,对多边学习研究界和运用机器学习的实践者都产生了重要影响,以告知相应的决策。