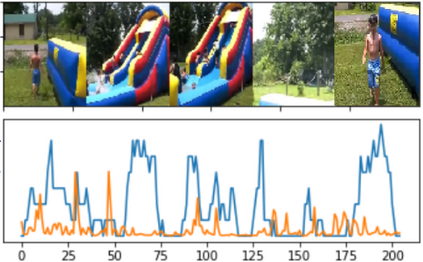
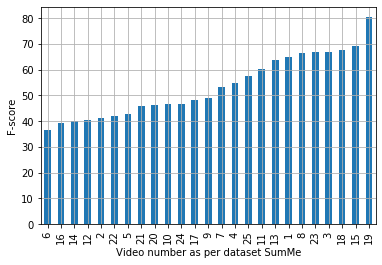
The assignment of importance scores to particular frames or (short) segments in a video is crucial for summarization, but also a difficult task. Previous work utilizes only one source of visual features. In this paper, we suggest a novel model architecture that combines three feature sets for visual content and motion to predict importance scores. The proposed architecture utilizes an attention mechanism before fusing motion features and features representing the (static) visual content, i.e., derived from an image classification model. Comprehensive experimental evaluations are reported for two well-known datasets, SumMe and TVSum. In this context, we identify methodological issues on how previous work used these benchmark datasets, and present a fair evaluation scheme with appropriate data splits that can be used in future work. When using static and motion features with parallel attention mechanism, we improve state-of-the-art results for SumMe, while being on par with the state of the art for the other dataset.
翻译:在视频中为特定框架或(短)段分配重要评分对于总结至关重要,但也是一项困难的任务。 先前的工作只使用一个视觉特征来源。 在本文中,我们建议建立一个新颖的模型结构,将视觉内容和运动的三个特征组合结合起来,以预测重要评分。 拟议的结构在使用反映(静态)视觉内容的动作特征和特征之前,先使用关注机制,即从图像分类模型中衍生出来。 报告对两个众所周知的数据集( Summe和TVSum)进行全面的实验评价。 在这方面,我们确定了关于以往工作如何使用这些基准数据集的方法问题,并提出了一个公平的评估方案,其中含有适当的数据分割,可用于今后的工作。在使用平行关注机制使用静态和运动特征时,我们改进SumMe的状态和艺术结果,同时与其他数据集的状态保持平衡。