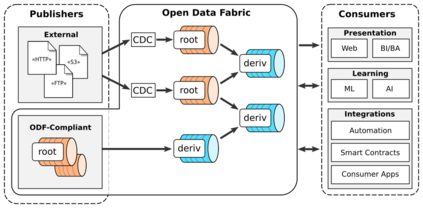
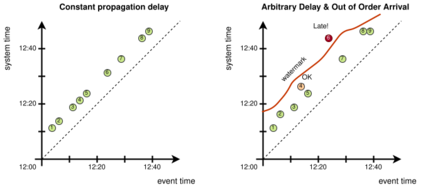
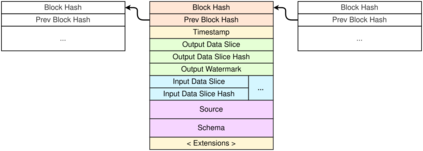
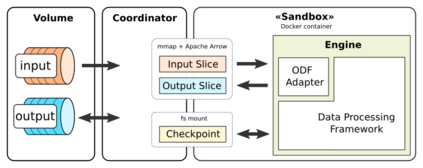
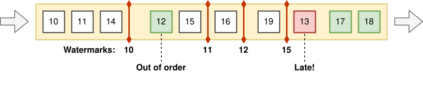
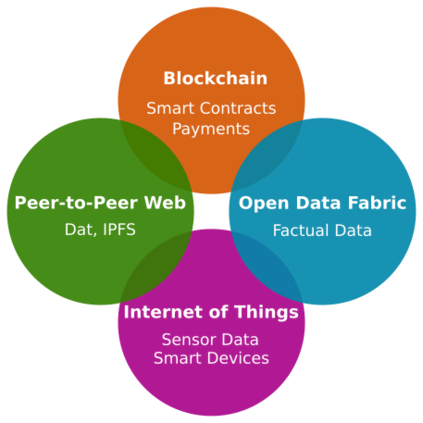
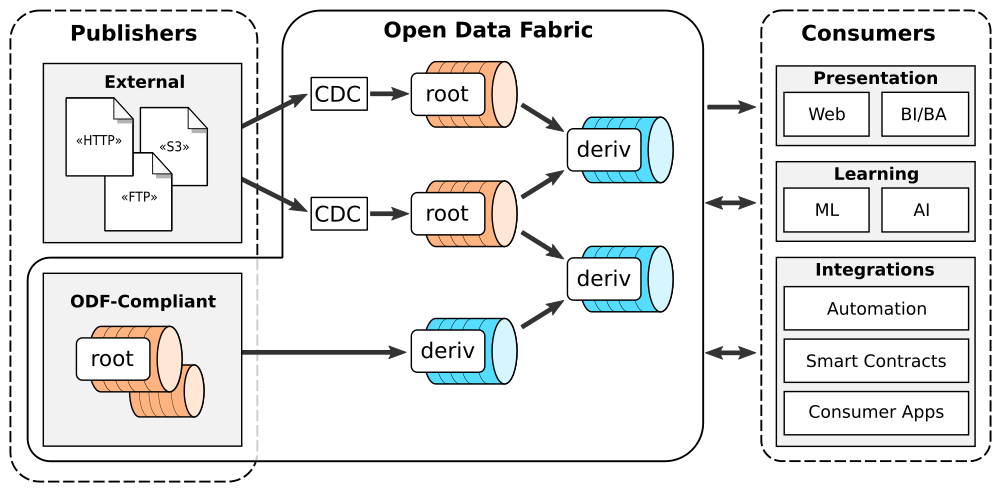
Data is the most powerful decision-making tool at our disposal. However, despite the exponentially growing volumes of data generated in the world, putting it to effective use still presents many challenges. Relevant data seems to be never there when it is needed - it remains siloed, hard to find, hard to access, outdated, and of bad quality. As a result, governments, institutions, and businesses remain largely impaired in their ability to make data-driven decisions. At the same time, data science is undergoing a reproducibility crisis. The results of the vast majority of studies cannot be replicated by other researchers, and provenance often cannot be established, even for data used in medical studies that affect lives of millions. We are losing our ability to collaborate at a time when significant improvements to data are badly needed. We believe that the fundamental reason lies in the modern data management processes being entirely at odds with the basic principles of collaboration and trust. Our field needs a fundamental shift of approach in how data is viewed, how it is shared and transformed. We must transition away from treating data as static, from exchanging it as anemic binary blobs, and instead focus on making multi-party data management more sustainable: such as reproducibility, verifiability, provenance, autonomy, and low latency. In this paper, we present the Open Data Fabric, a new decentralized data exchange and transformation protocol designed from the ground up to simplify data management and enable collaboration around data on a similar scale as currently seen in open-source software.
翻译:然而,尽管世界上生成的数据数量成倍增长,并被有效使用,但仍然存在许多挑战。相关数据在需要时似乎从未出现过,因为数据仍然分散、难以找到、难以获取、过时和质量差。因此,政府、机构和企业在作出数据驱动决策的能力方面仍然大为受损。与此同时,数据科学正在经历一种可复制的危机。绝大多数开放的软件研究的结果无法被其他研究人员复制,即使用于影响数百万人生活的医学研究的数据也往往无法建立来源。在数据急需显著改进的时候,我们正在丧失合作能力。我们认为,根本原因在于现代数据管理过程完全不符合合作和信任的基本原则。我们的领域需要从根本上改变如何看待数据、如何共享和改变数据的方法。我们必须从将目前将数据视为静态,从将数据作为原始数据交换,而将数据作为影响数百万人的医学研究使用。我们正文正在丧失合作能力,而是侧重于使多方的简化数据管理变得更可持续。 如此简单化的数据管理,我们不得不将数据转换为可变现的可变化和可变化的数据,也就是以易变现的可变化的数据管理。