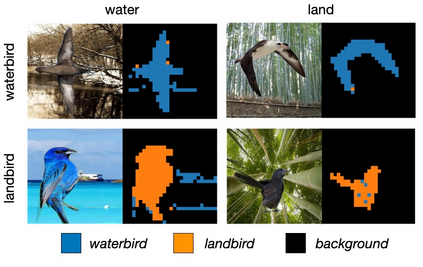
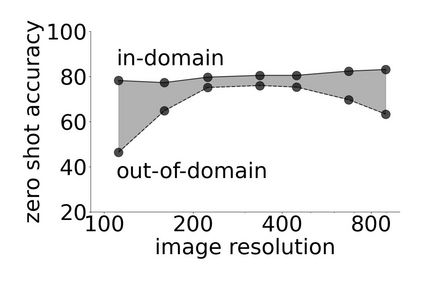
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.
翻译:近期零光图像识别方面的进展表明,视觉语言模型学会了通用直观表达方式,其精密的语义信息可能会被任意地与自然语言短语进行高层次的探测。 但是,了解图像不仅仅是了解图像中的内容所在,而且重要的是,该内容所在的位置。在这项工作中,我们审视了视觉语言模型如何很好地理解物体位于图像中的位置,并将图像中与视觉有关的部分组合在一起。我们展示了基于对比性损失和基于网络的大型数据捕获有限对象定位信息的当代视觉和语言代表学习模式是如何形成的。我们提出了一套最起码的修改,其结果为独家学习语义和空间信息的模型。我们用零弹射图像识别、不受监督的自下至下和自上至下的语义分层以及稳健性分析来衡量这一绩效。我们发现,由此形成的模型在非监视性分化方面达到了最新的结果,并表明所学的表达方式对于旨在探测视觉模型因果关系的数据集中令人怀疑的关联性非常强。