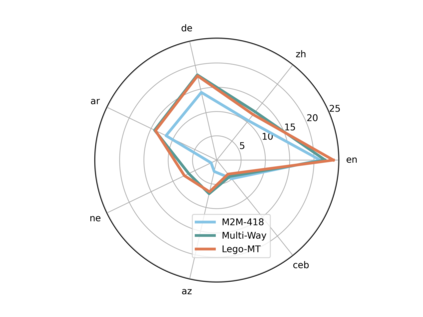
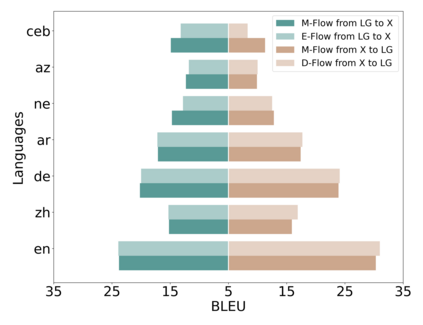
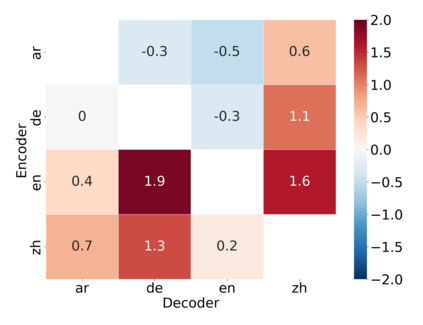
Traditional multilingual neural machine translation (MNMT) uses a single model to translate all directions. However, with the increasing scale of language pairs, simply using a single model for massive MNMT brings new challenges: parameter tension and large computations. In this paper, we revisit multi-way structures by assigning an individual branch for each language (group). Despite being a simple architecture, it is challenging to train de-centralized models due to the lack of constraints to align representations from all languages. We propose a localized training recipe to map different branches into a unified space, resulting in an efficient detachable model, Lego-MT. For a fair comparison, we collect data from OPUS and build the first large-scale open-source translation benchmark covering 7 language-centric data, each containing 445 language pairs. Experiments show that Lego-MT (1.2B) brings gains of more than 4 BLEU while outperforming M2M-100 (12B) (We will public all training data, models, and checkpoints)
翻译:传统的多语言神经机器翻译(MMMT)使用单一模型来翻译所有方向。然而,随着语言配对规模的扩大,仅仅使用大规模MMMT的单一模型就带来了新的挑战:参数紧张和大规模计算。在本文中,我们通过为每种语言指定一个分支(群体)来重新审视多条路结构。尽管这是一个简单的结构,但培训分散化模式却具有挑战性,因为没有限制将所有语言的表述方式统一起来。我们建议一种本地化的培训方法,将不同分支划入一个统一的空间,从而形成一个高效的分解模式(Lego-MT)。为了公平比较,我们从OPUS收集数据,建立第一个大型的开放源翻译基准,涵盖7个以语言为中心的数据,每个数据包含445对语言。实验显示,Lego-MT(1.2B)带来超过4个双语言的收益,而优于M2M-100(12B)(我们将公布所有培训数据、模式和检查站)