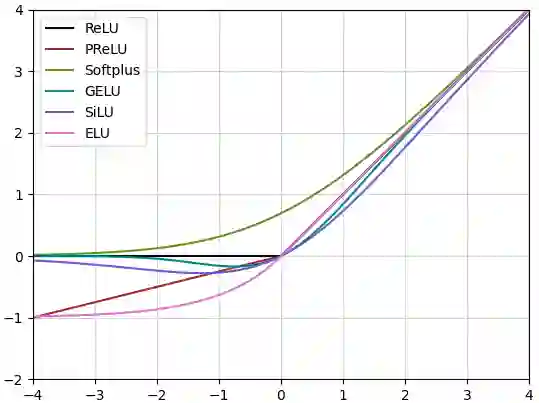
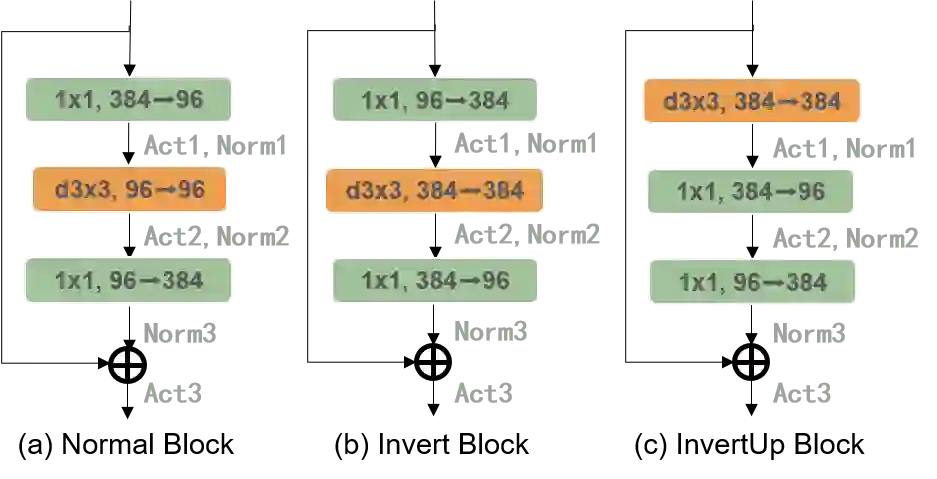
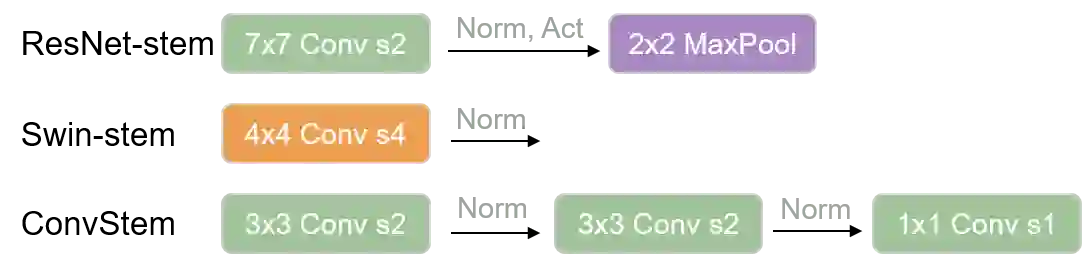
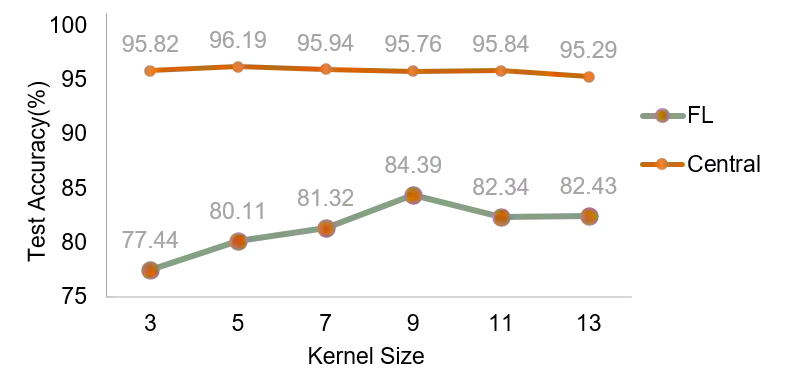
Federated learning (FL) is an emerging paradigm in machine learning, where a shared model is collaboratively learned using data from multiple devices to mitigate the risk of data leakage. While recent studies posit that Vision Transformer (ViT) outperforms Convolutional Neural Networks (CNNs) in addressing data heterogeneity in FL, the specific architectural components that underpin this advantage have yet to be elucidated. In this paper, we systematically investigate the impact of different architectural elements, such as activation functions and normalization layers, on the performance within heterogeneous FL. Through rigorous empirical analyses, we are able to offer the first-of-its-kind general guidance on micro-architecture design principles for heterogeneous FL. Intriguingly, our findings indicate that with strategic architectural modifications, pure CNNs can achieve a level of robustness that either matches or even exceeds that of ViTs when handling heterogeneous data clients in FL. Additionally, our approach is compatible with existing FL techniques and delivers state-of-the-art solutions across a broad spectrum of FL benchmarks. The code is publicly available at https://github.com/UCSC-VLAA/FedConv
翻译:暂无翻译