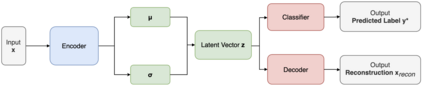
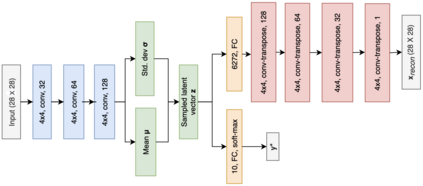
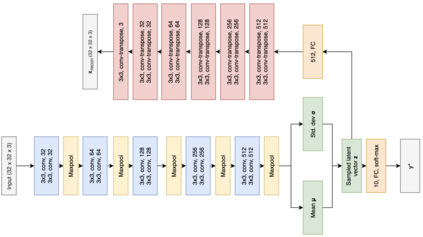
Due to the over-emphasize of the quantity of data, the data quality has often been overlooked. However, not all training data points contribute equally to learning. In particular, if mislabeled, it might actively damage the performance of the model and the ability to generalize out of distribution, as the model might end up learning spurious artifacts present in the dataset. This problem gets compounded by the prevalence of heavily parameterized and complex deep neural networks, which can, with their high capacity, end up memorizing the noise present in the dataset. This paper proposes a novel statistic -- noise score, as a measure for the quality of each data point to identify such mislabeled samples based on the variations in the latent space representation. In our work, we use the representations derived by the inference network of data quality supervised variational autoencoder (AQUAVS). Our method leverages the fact that samples belonging to the same class will have similar latent representations. Therefore, by identifying the outliers in the latent space, we can find the mislabeled samples. We validate our proposed statistic through experimentation by corrupting MNIST, FashionMNIST, and CIFAR10/100 datasets in different noise settings for the task of identifying mislabelled samples. We further show significant improvements in accuracy for the classification task for each dataset.
翻译:由于过分强调数据数量,数据质量往往被忽视。然而,并非所有培训数据点都同样有助于学习。特别是,如果贴错标签,则可能会积极损害模型的性能和普及分布的能力,因为模型最终可能学习数据集中存在的虚假文物。由于大量参数化和复杂的深层神经网络的普遍存在,问题更为严重,因为这些网络的功能性能高,最终会记忆数据集中存在的噪音。本文提出了一个新的统计 -- -- 噪音评分,作为每个数据点质量的衡量标准,以根据潜在空间代表的变异确定此类标签错误的样本。我们在工作中,使用数据质量推断网络监测变异自动编码器(AQUAVSS)得出的表述方法。我们的方法利用同一类的样品具有类似潜在代表性的事实。因此,通过查明潜在空间的外层,我们能找到错误的标定样本。我们通过对每个数据点进行实验来验证我们提议的统计,即通过腐蚀的MINIS、FASONIMIS和CIFAR的精确度来确定不同数据的等级。