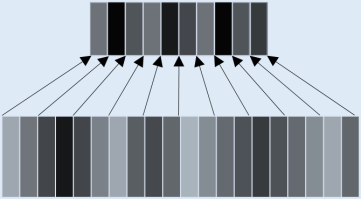
Active speaker detection and speech enhancement have become two increasingly attractive topics in audio-visual scenario understanding. According to their respective characteristics, the scheme of independently designed architecture has been widely used in correspondence to each single task. This may lead to the representation learned by the model being task-specific, and inevitably result in the lack of generalization ability of the feature based on multi-modal modeling. More recent studies have shown that establishing cross-modal relationship between auditory and visual stream is a promising solution for the challenge of audio-visual multi-task learning. Therefore, as a motivation to bridge the multi-modal associations in audio-visual tasks, a unified framework is proposed to achieve target speaker detection and speech enhancement with joint learning of audio-visual modeling in this study.
翻译:积极的语音探测和语音增强已成为视听情景理解中两个越来越有吸引力的专题:根据各自的特点,独立设计的建筑计划被广泛用于与每项任务相对应的通信中,这可能导致模型所学的代表性是特定任务,并不可避免地导致基于多模式模型的特征缺乏一般化能力;最近更多的研究表明,在视听和视觉流之间建立跨模式关系是应对视听多任务学习挑战的一个很有希望的解决办法;因此,作为在视听任务中连接多模式协会的动力,建议建立一个统一框架,通过在本研究中共同学习视听模型,实现目标演讲者的探测和语音增强。