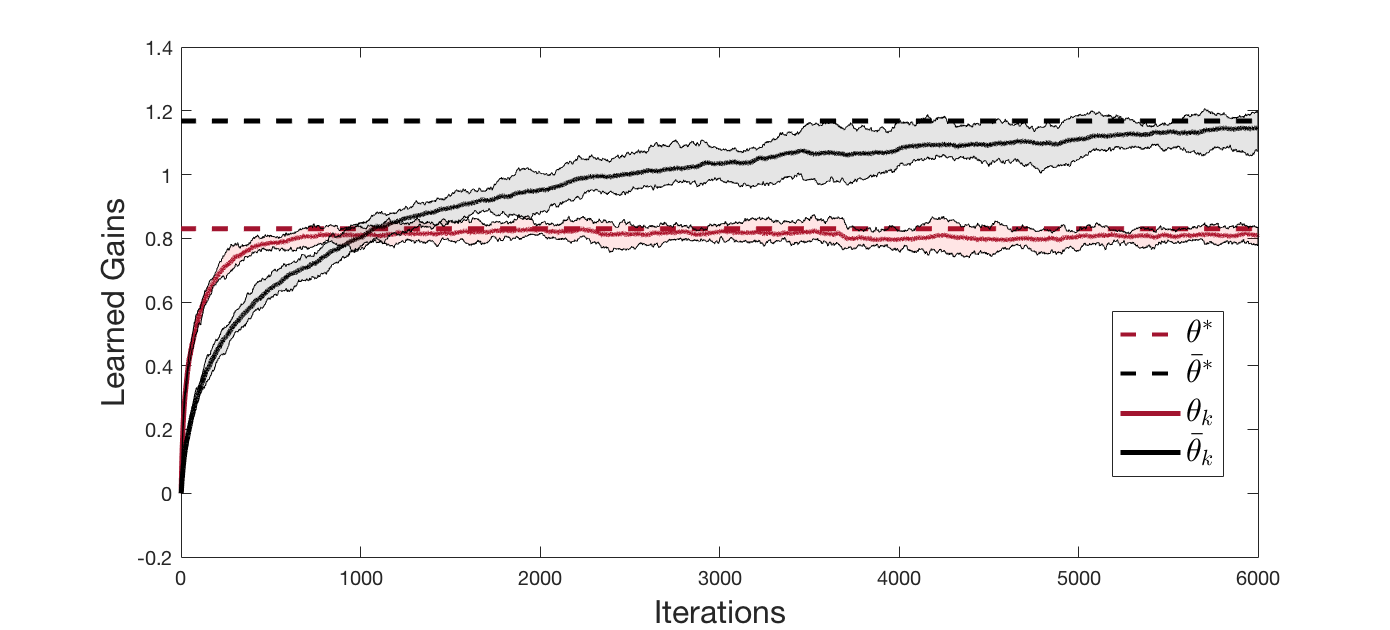
We study model-based and model-free policy optimization in a class of nonzero-sum stochastic dynamic games called linear quadratic (LQ) deep structured games. In such games, players interact with each other through a set of weighted averages (linear regressions) of the states and actions. In this paper, we focus our attention to homogeneous weights; however, for the special case of infinite population, the obtained results extend to asymptotically vanishing weights wherein the players learn the sequential weighted mean-field equilibrium. Despite the non-convexity of the optimization in policy space and the fact that policy optimization does not generally converge in game setting, we prove that the proposed model-based and model-free policy gradient descent and natural policy gradient descent algorithms globally converge to the sub-game perfect Nash equilibrium. To the best of our knowledge, this is the first result that provides a global convergence proof of policy optimization in a nonzero-sum LQ game. One of the salient features of the proposed algorithms is that their parameter space is independent of the number of players, and when the dimension of state space is significantly larger than that of the action space, they provide a more efficient way of computation compared to those algorithms that plan and learn in the action space. Finally, some simulations are provided to numerically verify the obtained theoretical results.
翻译:我们在一个称为线性二次(LQ)深层次结构化游戏的非零和随机动态游戏中研究基于模型和无模式的政策优化。在这样的游戏中,玩家通过一组国家和行动的加权平均值(线性回归)相互互动。在本文中,我们集中关注同质加权;然而,对于无限人口的特殊情况,所获得的结果扩大到无零和不模式消散重量,让玩家学习顺序加权平均场平衡。尽管政策空间优化不协调,而且政策优化一般并不在游戏设置中趋同,但我们证明,拟议的基于模型和无模式的政策梯度梯度下降和自然政策梯度下降算法在全球与一组次组合的加权平均数(线性回归)相融合。据我们所知,这是在非零和累加LQ游戏中为政策优化提供全球趋同证据的第一个结果。提议的算法的一个突出特征是,它们的参数空间参数空间是独立于玩家人数的,当国家空间空间的维度比空间行动最终的计算方法要大得多时,在空间的计算方法上,将空间的数值比空间的计算结果最终的计算结果要大得多。