
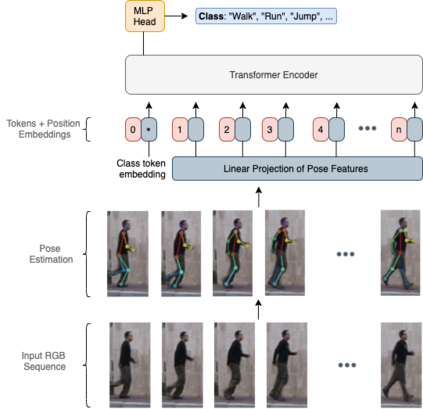
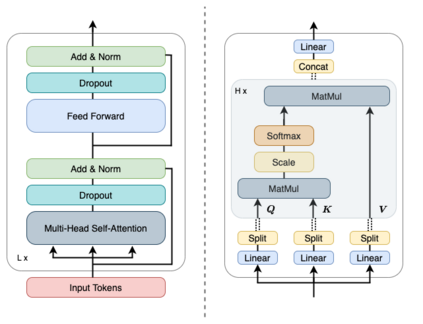
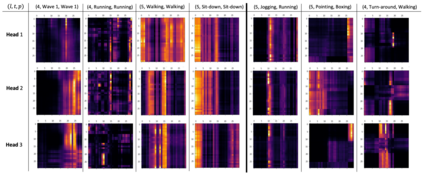
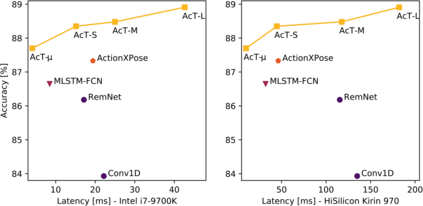
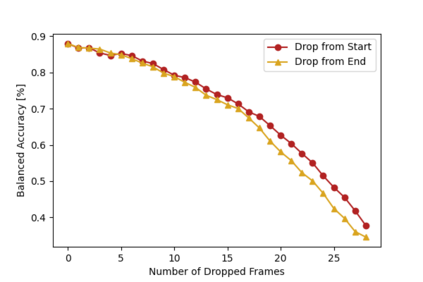
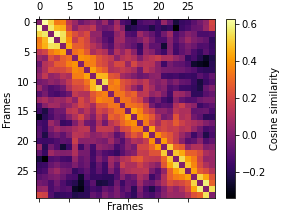
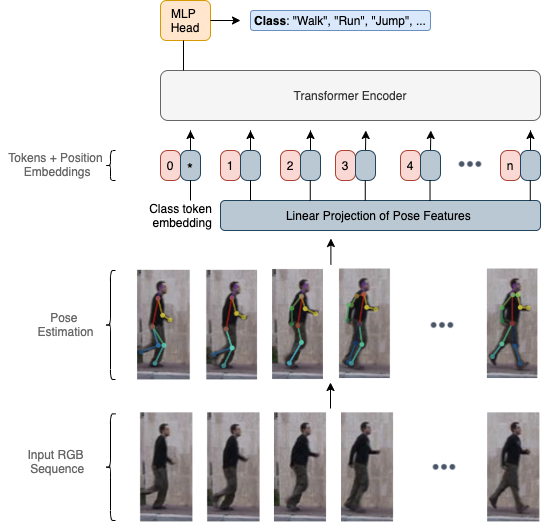
Deep neural networks based purely on attention have been successful across several domains, relying on minimal architectural priors from the designer. In Human Action Recognition (HAR), attention mechanisms have been primarily adopted on top of standard convolutional or recurrent layers, improving the overall generalization capability. In this work, we introduce Action Transformer (AcT), a simple, fully self-attentional architecture that consistently outperforms more elaborated networks that mix convolutional, recurrent, and attentive layers. In order to limit computational and energy requests, building on previous human action recognition research, the proposed approach exploits 2D pose representations over small temporal windows, providing a low latency solution for accurate and effective real-time performance. Moreover, we open-source MPOSE2021, a new large-scale dataset, as an attempt to build a formal training and evaluation benchmark for real-time short-time human action recognition. Extensive experimentation on MPOSE2021 with our proposed methodology and several previous architectural solutions proves the effectiveness of the AcT model and poses the base for future work on HAR.
翻译:在人类行动认知(HAR)中,关注机制主要在标准进化层或经常性层之上采用,提高了总体概括能力;在这项工作中,我们引入了“行动变换器”(AcT),这是一个简单、完全自我注意的架构,它一贯优于更为完善的网络,它混合了共进、经常性和专注层;为了限制计算和能源请求,在以往人类行动识别研究的基础上,拟议方法利用2D代表小型时间窗口,为准确和有效实时性能提供一种低延缓性解决方案;此外,我们开发了一个新的大规模数据组合,目的是为实时短期人类行动识别建立一个正式的培训和评估基准;对MPOSE2021进行广泛的实验,利用我们拟议的方法和以前的若干建筑解决方案,证明了AcT模式的有效性,并为今后关于HAR的工作打下了基础。

相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem



