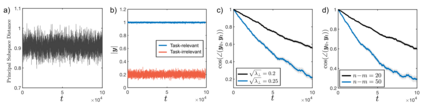
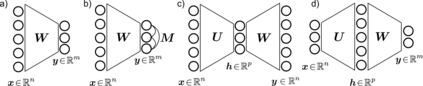
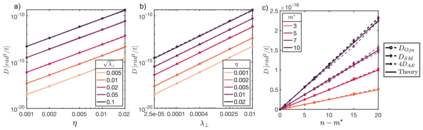
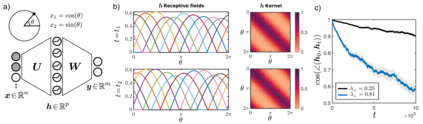
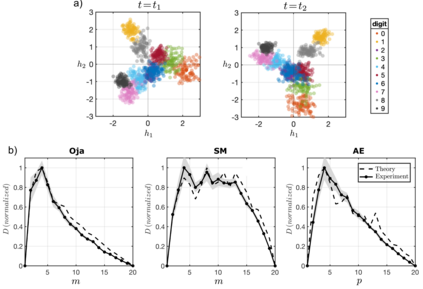
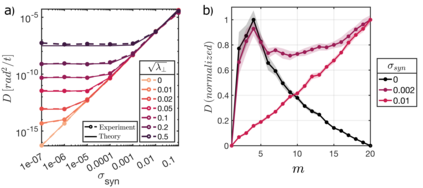
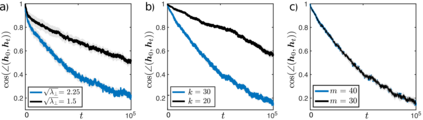
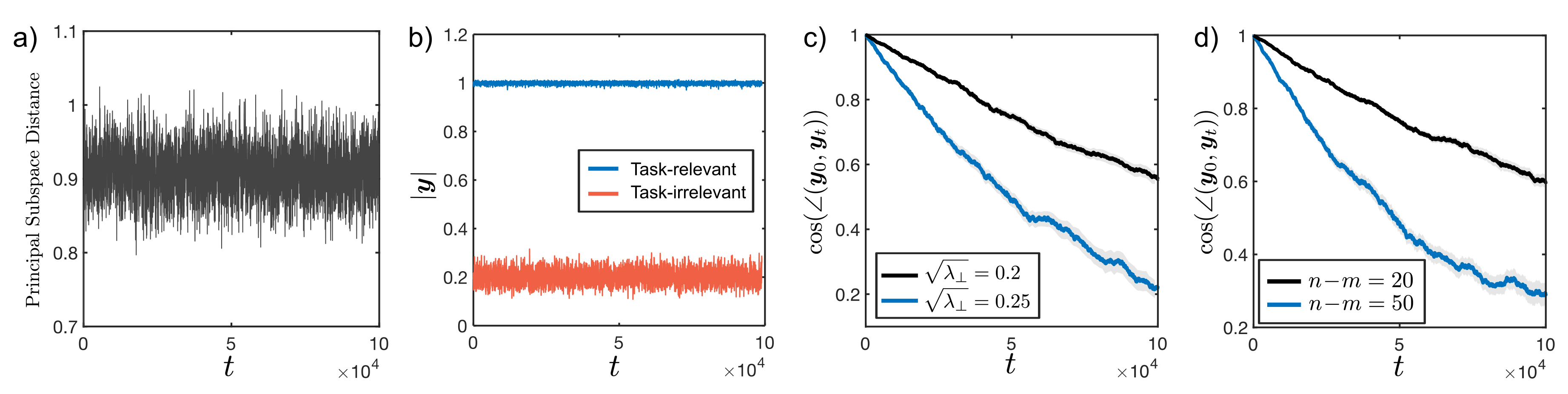
Biological and artificial learners are inherently exposed to a stream of data and experience throughout their lifetimes and must constantly adapt to, learn from, or selectively ignore the ongoing input. Recent findings reveal that, even when the performance remains stable, the underlying neural representations can change gradually over time, a phenomenon known as representational drift. Studying the different sources of data and noise that may contribute to drift is essential for understanding lifelong learning in neural systems. However, a systematic study of drift across architectures and learning rules, and the connection to task, are missing. Here, in an online learning setup, we characterize drift as a function of data distribution, and specifically show that the learning noise induced by task-irrelevant stimuli, which the agent learns to ignore in a given context, can create long-term drift in the representation of task-relevant stimuli. Using theory and simulations, we demonstrate this phenomenon both in Hebbian-based learning -- Oja's rule and Similarity Matching -- and in stochastic gradient descent applied to autoencoders and a supervised two-layer network. We consistently observe that the drift rate increases with the variance and the dimension of the data in the task-irrelevant subspace. We further show that this yields different qualitative predictions for the geometry and dimension-dependency of drift than those arising from Gaussian synaptic noise. Overall, our study links the structure of stimuli, task, and learning rule to representational drift and could pave the way for using drift as a signal for uncovering underlying computation in the brain.
翻译:暂无翻译