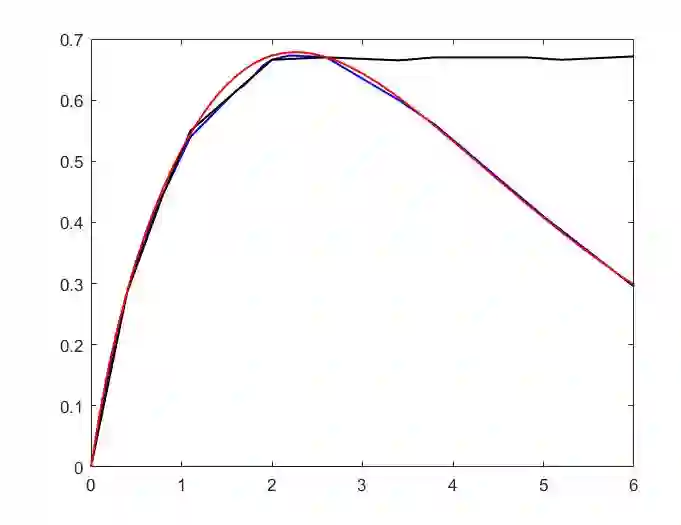
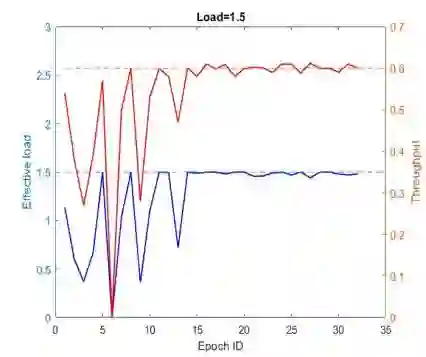
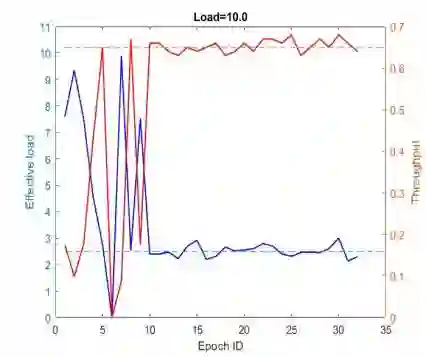
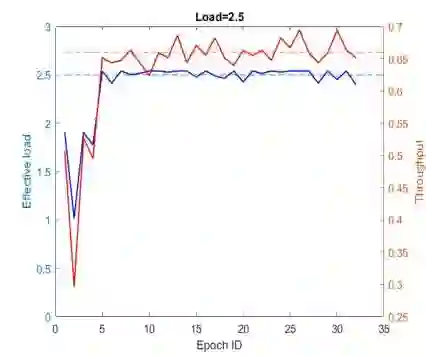
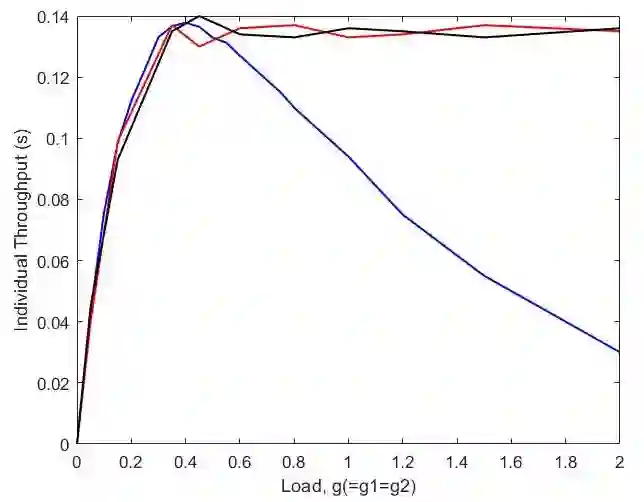
This paper proposes a multi-agent reinforcement learning based medium access framework for wireless networks. The access problem is formulated as a Markov Decision Process (MDP), and solved using reinforcement learning with every network node acting as a distributed learning agent. The solution components are developed step by step, starting from a single-node access scenario in which a node agent incrementally learns to control MAC layer packet loads for reining in self-collisions. The strategy is then scaled up for multi-node fully-connected scenarios by using more elaborate reward structures. It also demonstrates preliminary feasibility for more general partially connected topologies. It is shown that by learning to adjust MAC layer transmission probabilities, the protocol is not only able to attain theoretical maximum throughput at an optimal load, but unlike classical approaches, it can also retain that maximum throughput at higher loading conditions. Additionally, the mechanism is agnostic to heterogeneous loading while preserving that feature. It is also shown that access priorities of the protocol across nodes can be parametrically adjusted. Finally, it is also shown that the online learning feature of reinforcement learning is able to make the protocol adapt to time-varying loading conditions.
翻译:本文为无线网络提出了一个基于多剂强化学习的中位访问框架。 访问问题是作为Markov 决策程序( MDP)来拟订的, 并使用每个网络节点作为分布式学习剂的强化学习来解决。 解决方案组成部分是逐步开发的, 从单一节点访问假设开始, 节点代理逐渐学会控制MAC 层包装量, 以控制自我凝聚。 然后, 战略通过使用更精细的奖赏结构, 扩大多节完全连通的假设情景。 该战略还展示了更一般部分连通的表层统计的初步可行性。 通过学习调整MAC 层传输概率, 协议不仅能够在最佳载荷上达到理论的最大吞吐量, 而且与传统方法不同, 它也可以保留在较高负荷条件下的最大吞吐量。 此外, 机制在保存该特性的同时, 杂装量是不可知的。 它还表明, 协议在多个节点上的访问重点可以进行对准调整。 最后, 它还表明, 强化学习的在线学习特征能够使协议适应时间递增装条件。