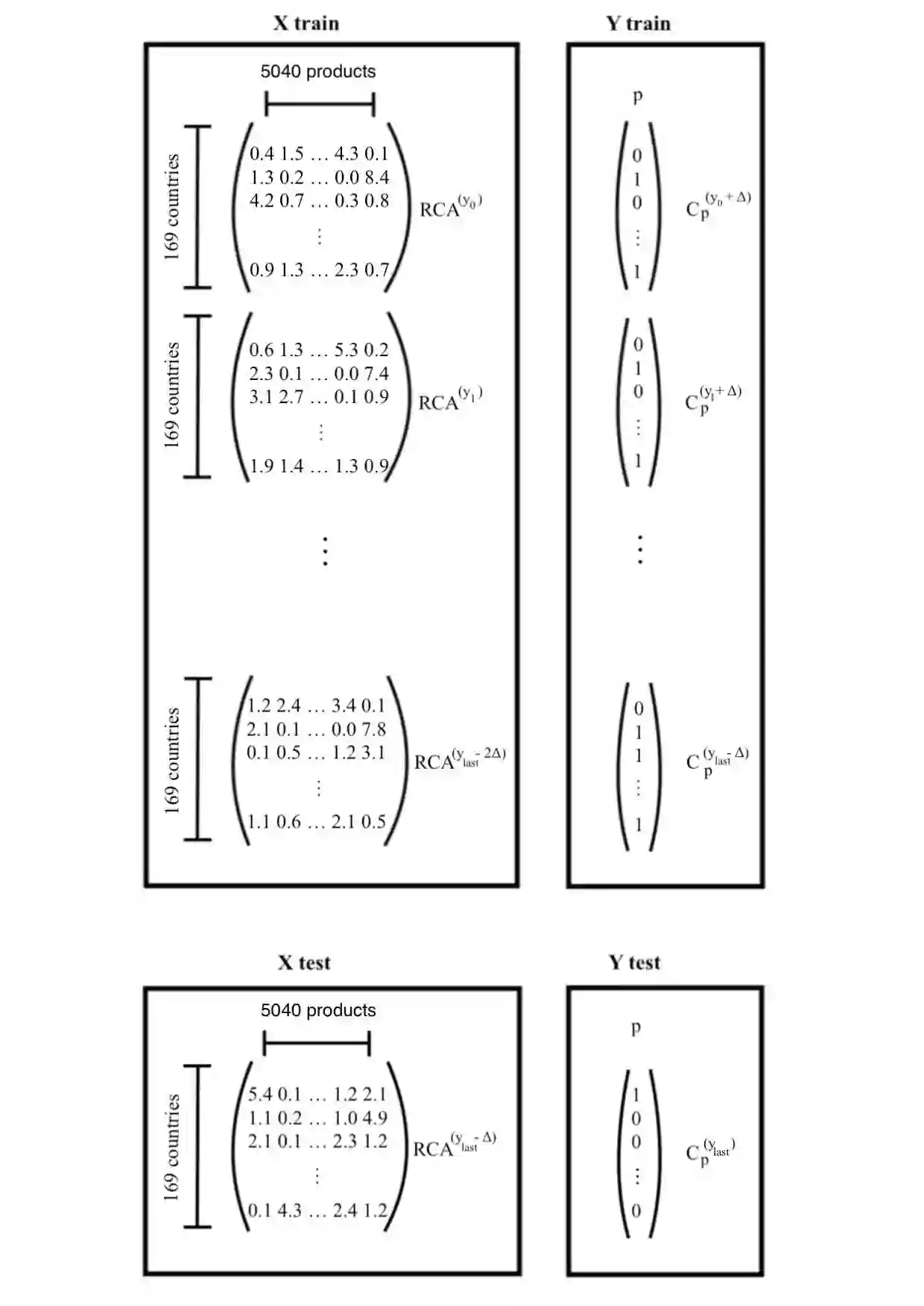
Economic complexity methods, and in particular relatedness measures, lack a systematic evaluation and comparison framework. We argue that out-of-sample forecast exercises should play this role, and we compare various machine learning models to set the prediction benchmark. We find that the key object to forecast is the activation of new products, and that tree-based algorithms clearly overperform both the quite strong auto-correlation benchmark and the other supervised algorithms. Interestingly, we find that the best results are obtained in a cross-validation setting, when data about the predicted country was excluded from the training set. Our approach has direct policy implications, providing a quantitative and scientifically tested measure of the feasibility of introducing a new product in a given country.
翻译:经济复杂性方法,特别是关联性衡量方法,缺乏系统的评估和比较框架。我们认为,超模预测工作应该发挥这一作用,我们比较各种机器学习模型以设定预测基准。我们发现,预测的关键目标是激活新产品,而基于树木的算法显然超过强大的自动连接基准和其他受监督的算法。有趣的是,我们发现,最佳结果是在交叉验证环境下取得的,而关于预测国家的数据被排除在成套培训之外。我们的方法具有直接的政策影响,为在特定国家引进新产品的可行性提供了定量和经过科学检验的衡量标准。