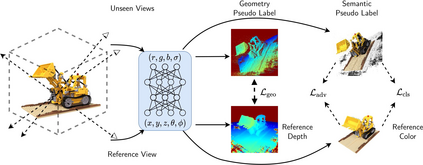
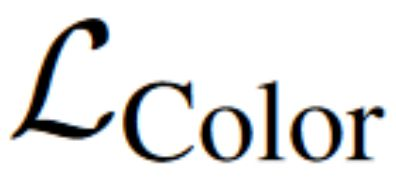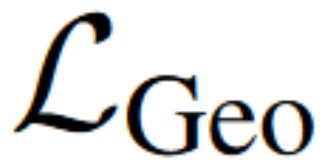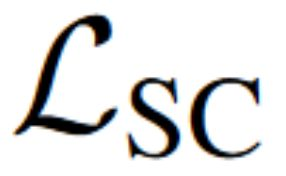We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
翻译:我们提出了一个基于神经亮度场(NERF)的360美元全景图像合成新观点的方法。 在类似环境下,先前的研究依赖于多层观感的周边内插能力,以完成封闭性造成的缺失区域,这导致在预测中出现人工制品。我们提出360FusionNERF,这是一个半监督的学习框架,我们在这个框架中引入了几何监督和语义一致性,以指导渐进式培训进程。首先,输入图像被重新投影为360 ⁇ circ$图像,而辅助深度地图则在其他摄像头位置绘制。除了 NERF 彩色指导外,深度监督还取决于多层观感的周边内插图,以完成综合观点的地理测量。此外,我们引入了一种语义一致性损失,鼓励现实地表达新观点。我们利用事先训练过的视觉摄像仪(例如SSSPS IP,一个通过自然语言监听从网络上挖掘的数千万张的2DPSPI照片的视觉变换器, 实验显示我们所提议的方法可以产生真实的- ~IM3 IM3,同时将数据转换到连续的图像,同时将SLRRRM3 。