
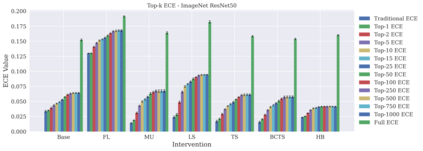
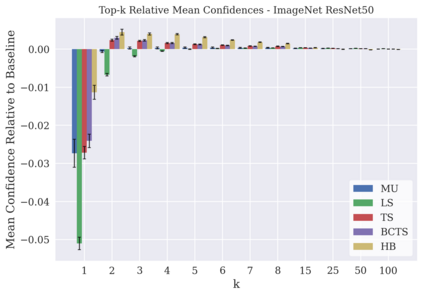
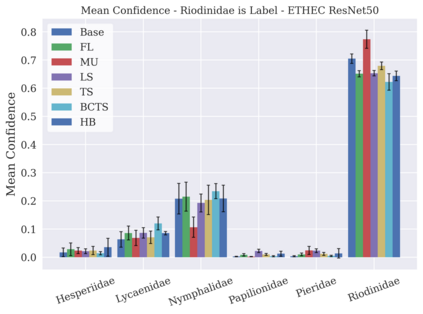
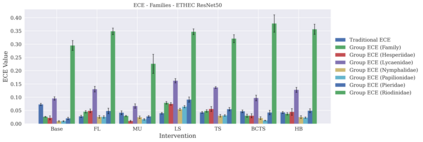
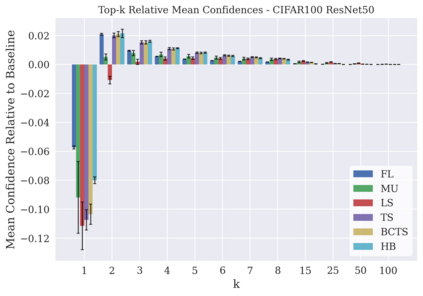
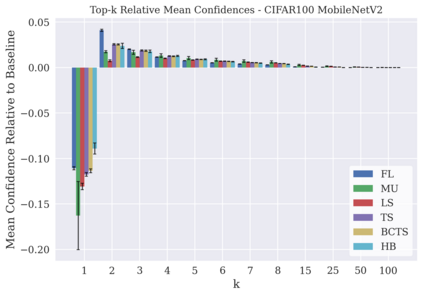
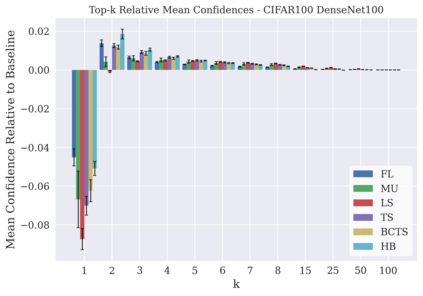
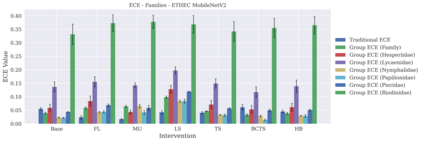
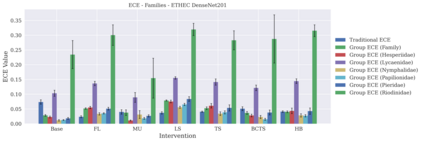
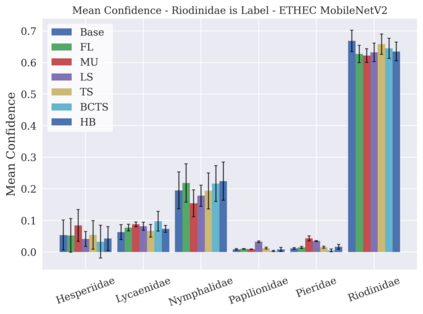
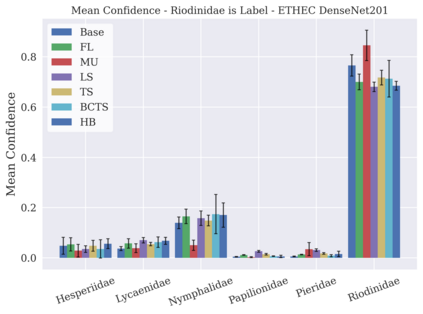
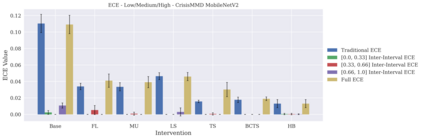
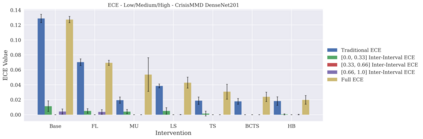
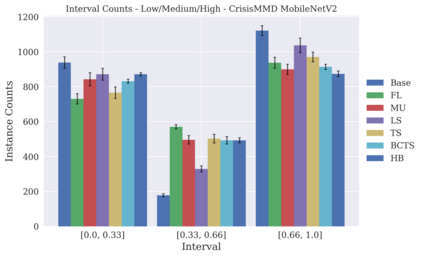
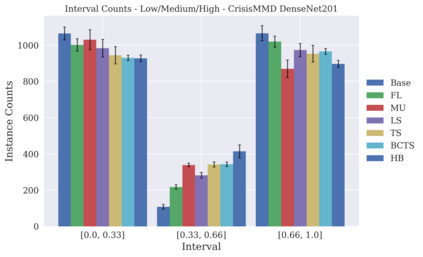
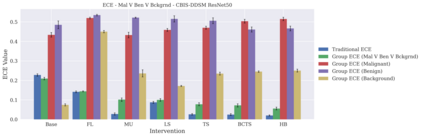
Classifier calibration has received recent attention from the machine learning community due both to its practical utility in facilitating decision making, as well as the observation that modern neural network classifiers are poorly calibrated. Much of this focus has been towards the goal of learning classifiers such that their output with largest magnitude (the "predicted class") is calibrated. However, this narrow interpretation of classifier outputs does not adequately capture the variety of practical use cases in which classifiers can aid in decision making. In this work, we argue that more expressive metrics must be developed that accurately measure calibration error for the specific context in which a classifier will be deployed. To this end, we derive a number of different metrics using a generalization of Expected Calibration Error (ECE) that measure calibration error under different definitions of reliability. We then provide an extensive empirical evaluation of commonly used neural network architectures and calibration techniques with respect to these metrics. We find that: 1) definitions of ECE that focus solely on the predicted class fail to accurately measure calibration error under a selection of practically useful definitions of reliability and 2) many common calibration techniques fail to improve calibration performance uniformly across ECE metrics derived from these diverse definitions of reliability.
翻译:分类校准最近受到机器学习界的注意,这既是因为其在促进决策方面的实际效用,也因为其认为现代神经网络分类器的校准差强,而且认为现代神经网络分类器的校准差强弱,其中很多重点都是为了学习分类器的目标,这样就可以校准其最大范围的输出(“预测类”)。然而,这种对分类器产出的狭义解释并不能充分反映分类器能够帮助决策的各种实际使用案例。在这项工作中,我们认为,必须制定更清晰的衡量标准,准确测量分类器将部署的具体环境的校准差错。为此,我们利用预期校准错误(欧洲经委会)的概括化来得出若干不同的计量标准,根据不同的可靠性定义来测量校准差错。我们随后对常用的神经网络结构和校准技术进行广泛的实证评价。我们发现:(1) 仅侧重于预测等级的欧洲经委会的定义无法根据可靠和2许多通用校准技术从欧洲经委会的这些指标中得出统一校准性定义。
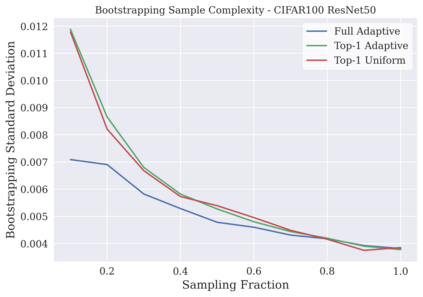
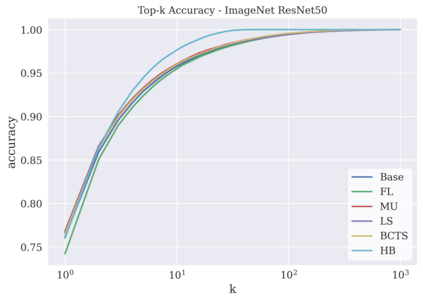
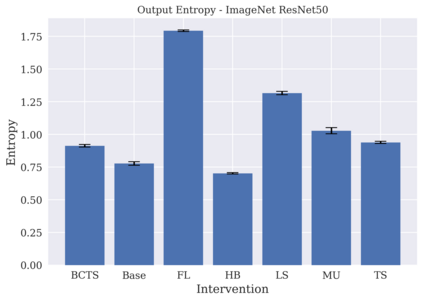
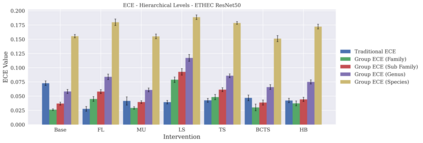
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


