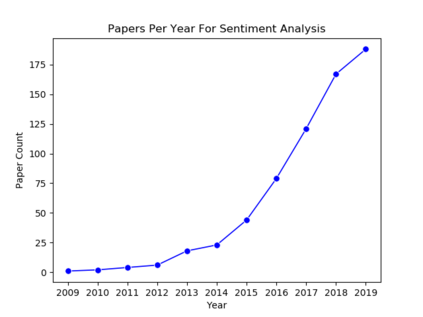
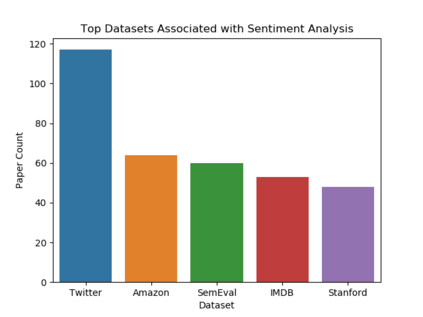
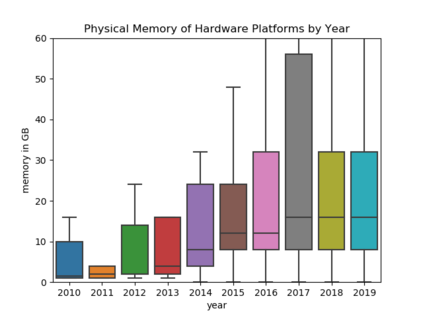
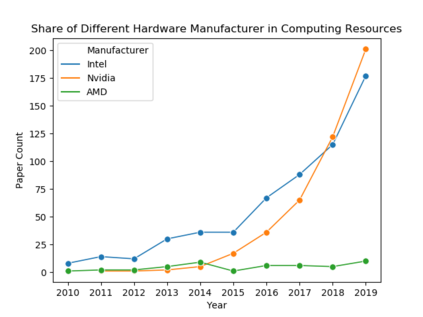
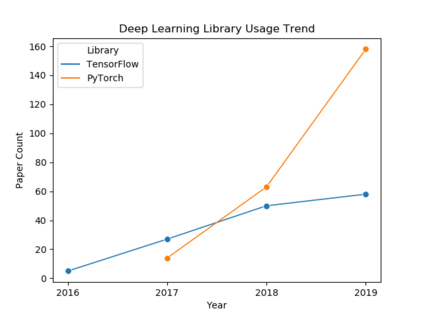
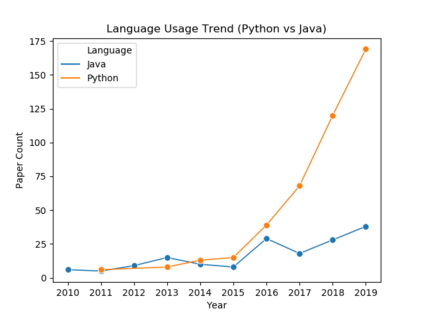
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.
翻译:理解全文学术文章的关键见解至关重要,因为它使我们能够确定有趣的趋势,深入了解研究与开发以及建立知识图表。然而,一些有趣的关键见解只有在考虑全文时才能得到。虽然研究人员在从短文中提取信息方面取得了重大进展,但从全文学术文献中提取科学实体仍然是一个具有挑战性的问题。这项工作展示了一个名为EneRex的自动端到端研究实体提取器,以提取数据集使用、客观任务、全文学术研究文章中的方法等技术方面。此外,我们从全文文章中提取了三个新颖的方面,例如与源代码的链接、计算资源、语言/图书馆的编程等。我们展示了EneRex如何从计算机科学领域的大规模数据集中提取关键见解和趋势。我们进一步测试了我们关于多个数据集的管道,发现EneRex改进了艺术模型的状态。我们着重指出了现有数据集在能力上是如何受到限制的,以及EneRex可能如何融入现有的知识图表。我们还展示了EereRex系统的详细讨论点。我们还展示了我们未来的数据代码。