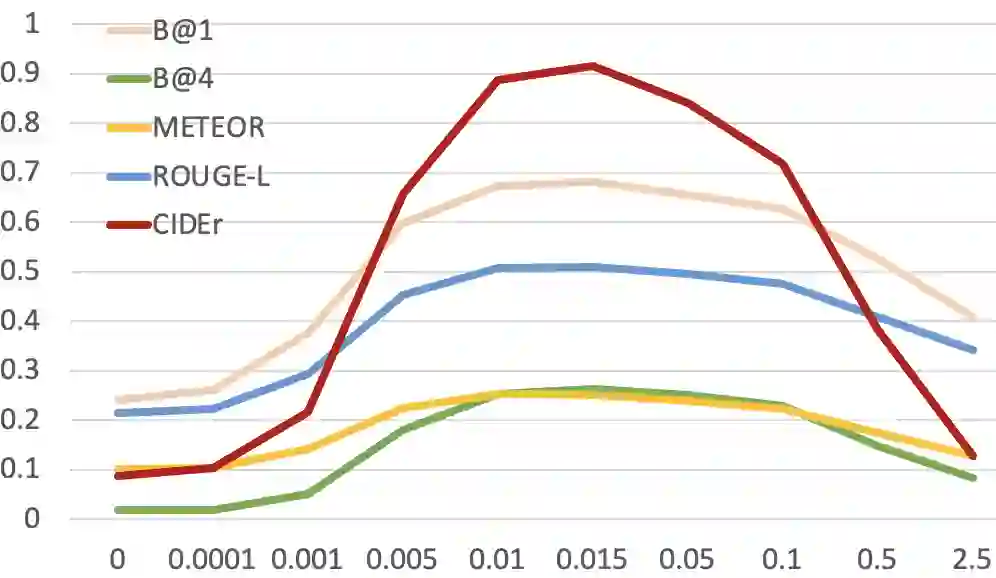
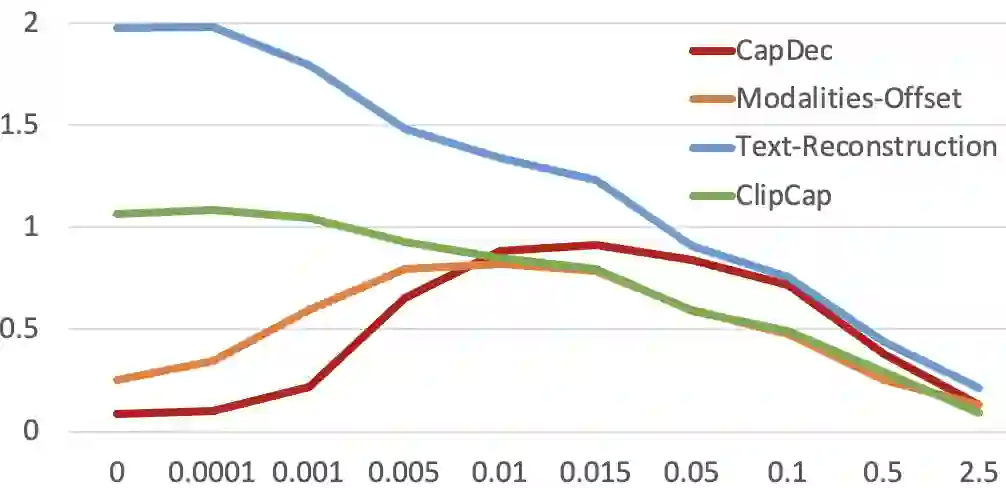
We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
翻译:我们只使用CLIP模型和额外文本数据来考虑图像显示任务,没有附加字幕图像。 我们的方法取决于CLIP是否受过类似视觉和文字嵌入的训练。 因此, 我们只需要学习如何将 CLIP 文本嵌入内容翻译回文字, 我们可以学习如何做到这一点, 只需用文字来学习冷冻 CLIP 文本编码器的解码器。 我们争辩说, 这种直觉是“ 几乎正确的 ”, 因为嵌入空间之间存在差距, 并提议在训练期间通过注入噪音来纠正这一点。 我们通过展示SOTA零光图像说明, 包括风格转换在内的四个基准, 我们展示了我们的方法的有效性 。 在 GitHub 上可以找到代码、 数据和模型 。