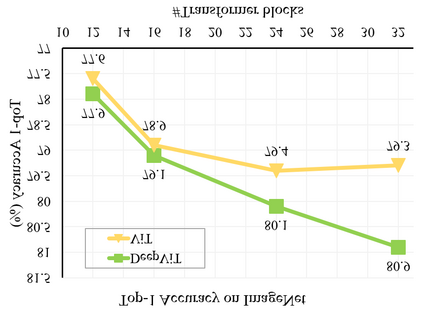
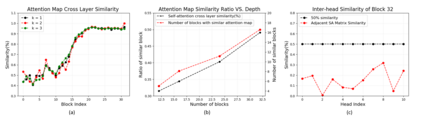
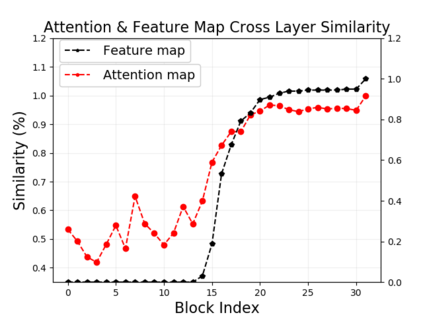
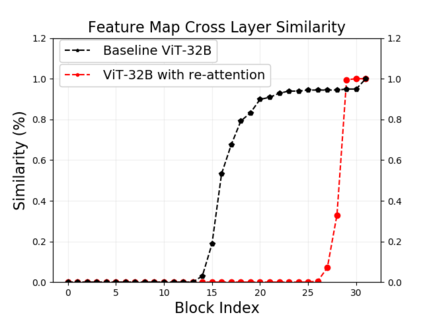
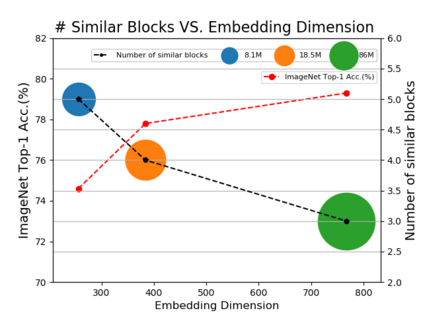
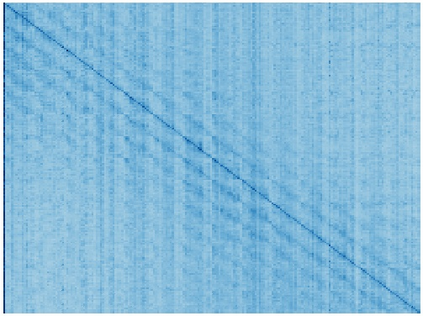
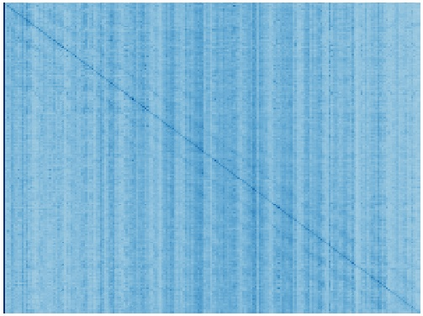
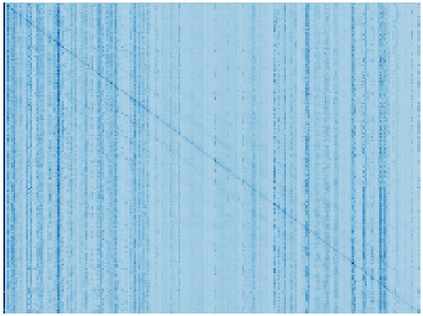
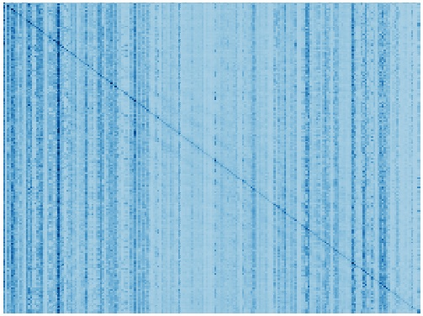
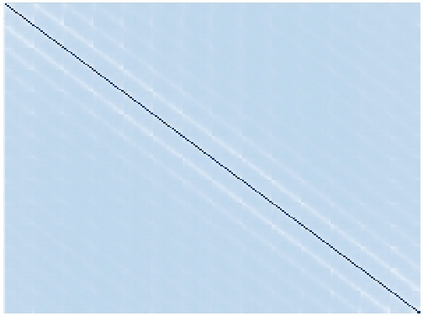
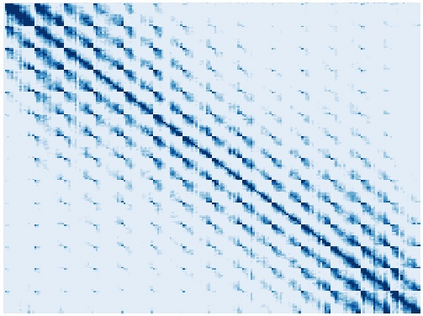
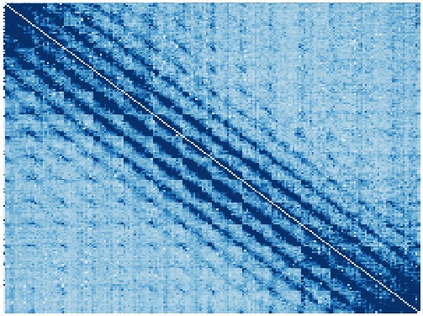
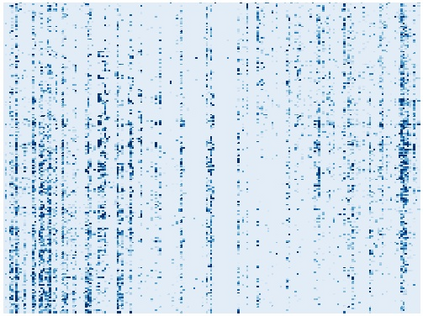
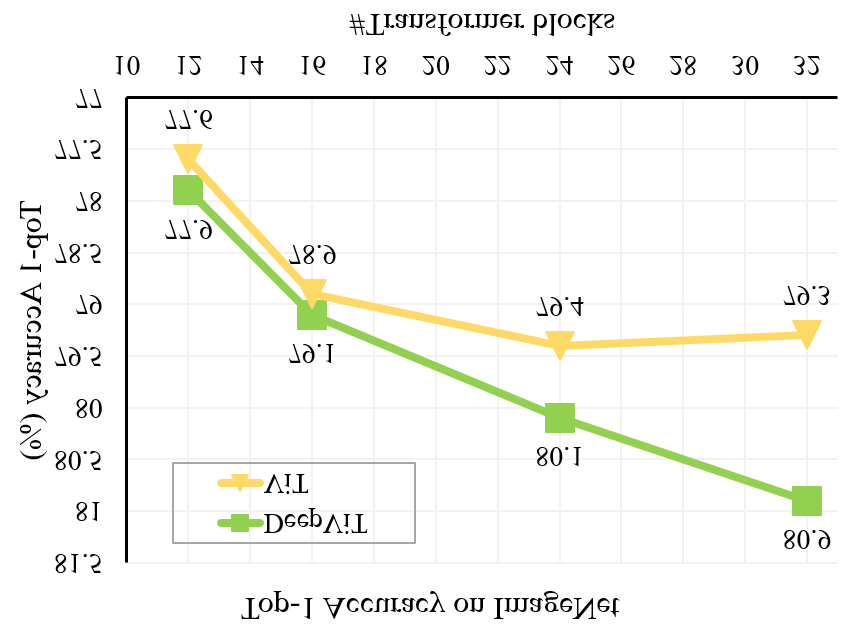
Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code will be made publicly available
翻译:最近图像分类任务中成功应用了视觉变压器(ViTs ) 。 在本文中, 我们显示, 不像通过堆叠更多变动层可以改进的神经网络( CNNs ), ViTs饱和度的性能在放大到更深的时候会很快。 更具体地说, 我们从经验中观察到, 这种缩小规模的困难是由注意力崩溃问题造成的: 当变压器变深时, 注意图逐渐变得相似, 甚至在某些层次之后也变得非常相似。 换句话说, 地貌图往往与深为ViT模型的顶层相同。 这一事实表明, 在更深层的 ViTs 中, 自我注意机制无法学习有效的代表学习概念, 并且阻碍模型取得预期的绩效增益。 基于上述观察, 我们提出了一个简单而有效的方法, 名为 Reatatattention, 重新生成关注地图, 以在不同层次上增加其多样性, 计算和记忆成本微不足道。 支持的方法使得通过对现有ViT模式进行微修改, 改进性改进工作模式。 特别是, 将可变式 格式 将 将 校正式 格式 格式改为 。