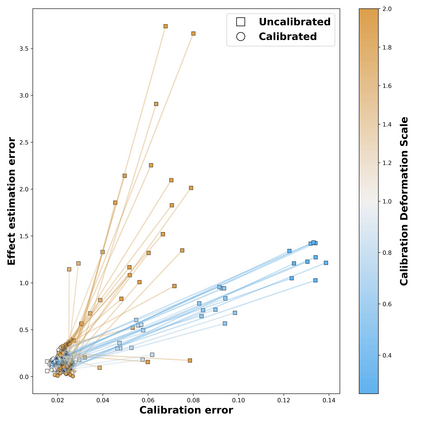
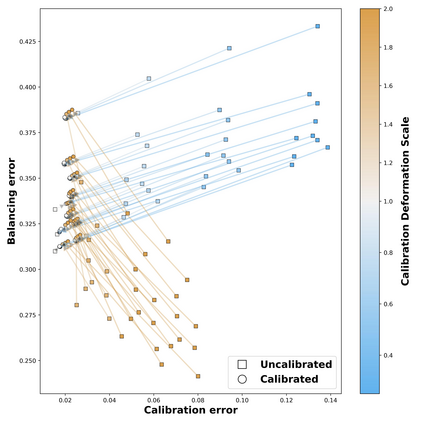
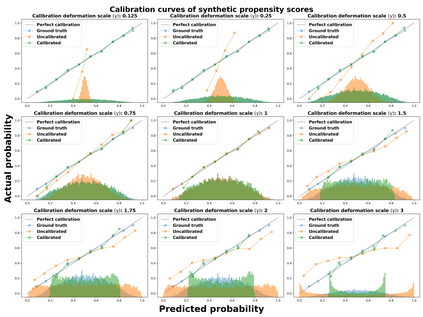
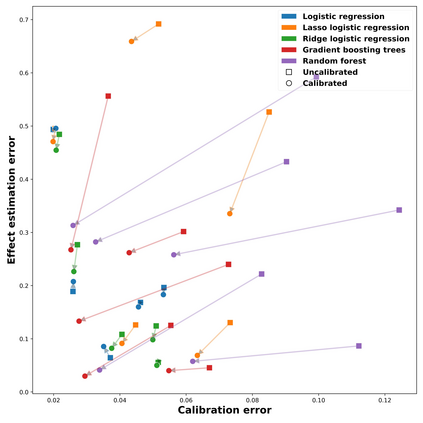
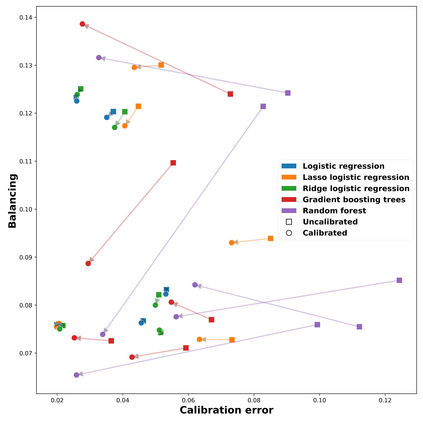
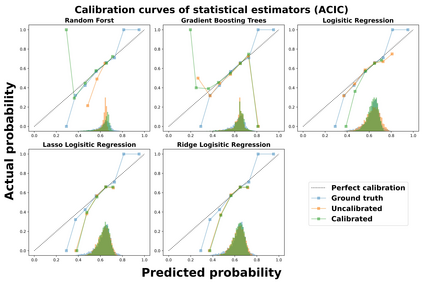
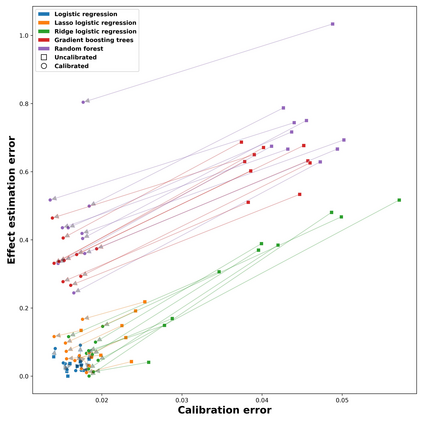
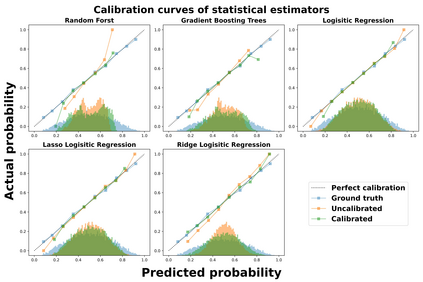
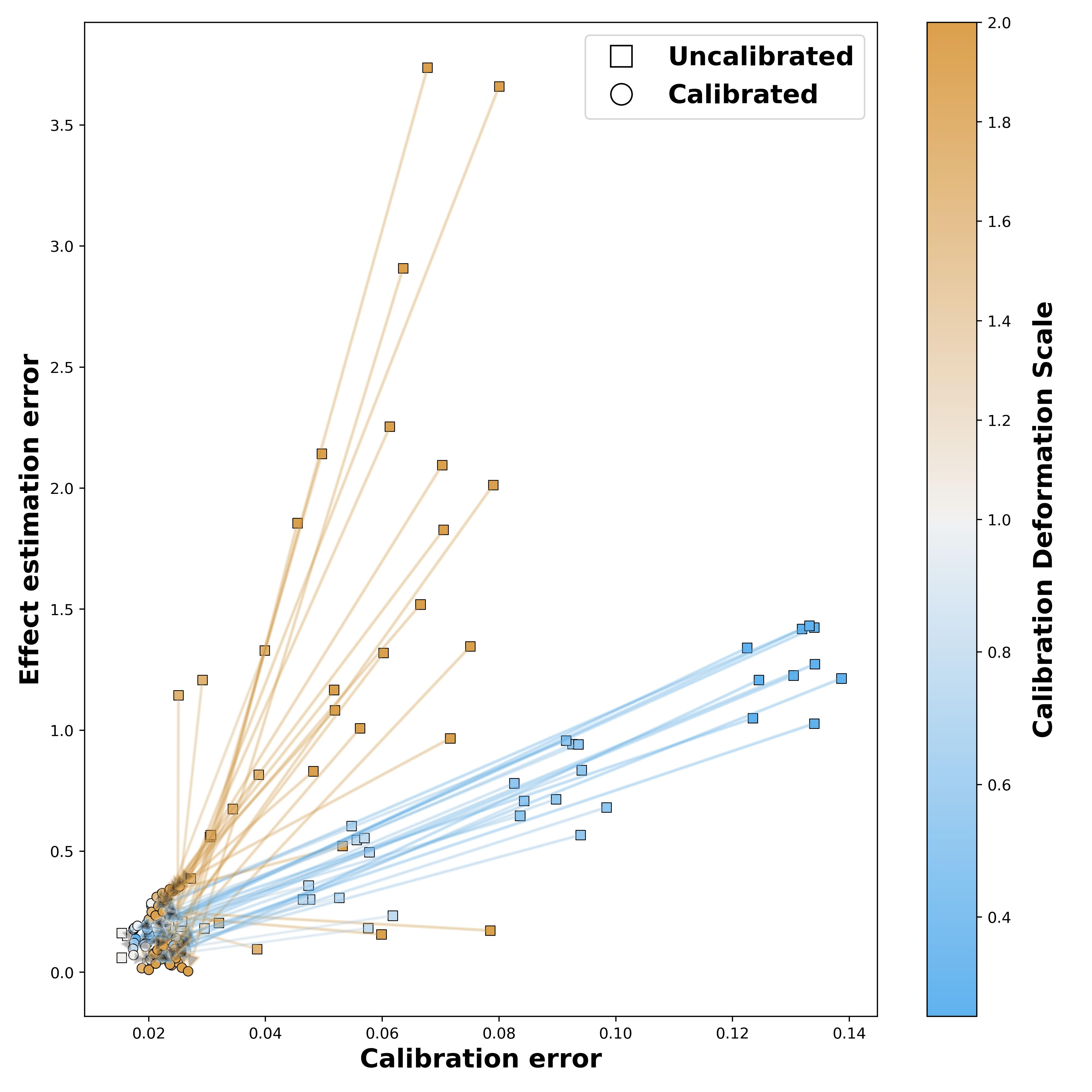
Theoretical guarantees for causal inference using propensity scores are partly based on the scores behaving like conditional probabilities. However, scores between zero and one, especially when outputted by flexible statistical estimators, do not necessarily behave like probabilities. We perform a simulation study to assess the error in estimating the average treatment effect before and after applying a simple and well-established post-processing method to calibrate the propensity scores. We find that post-calibration reduces the error in effect estimation for expressive uncalibrated statistical estimators, and that this improvement is not mediated by better balancing. The larger the initial lack of calibration, the larger the improvement in effect estimation, with the effect on already-calibrated estimators being very small. Given the improvement in effect estimation and that post-calibration is computationally cheap, we recommend it will be adopted when modelling propensity scores with expressive models.
翻译:使用偏差分数进行因果关系推论的理论保障,部分依据了分数的判断方式,如有条件的概率。然而,零和一之间的分数,特别是如果由灵活的统计估计员输出,不一定像概率一样。我们进行模拟研究,评估在应用简单和完善的后处理方法校准偏差分数之前和之后估计平均处理效果的错误。我们发现校准后,对表达式未校准统计估计数的误差进行了实际估计,而这一改进不是通过更好的平衡来调解的。最初缺乏校准的幅度越大,实际估计的改进就越大,对已经校准的估计数的影响也非常小。鉴于实际估计的改进以及校准后校准的计算成本低,我们建议在用表达模型模拟偏差分数时采用这一方法。