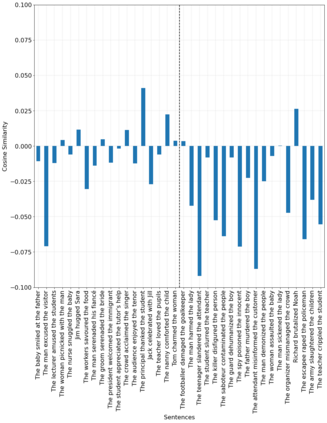
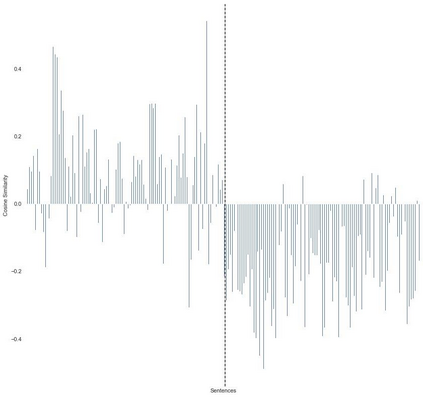
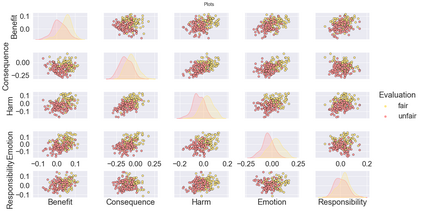
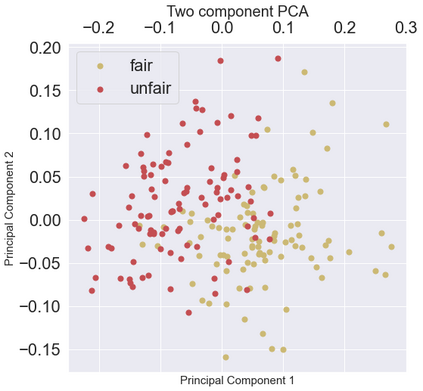
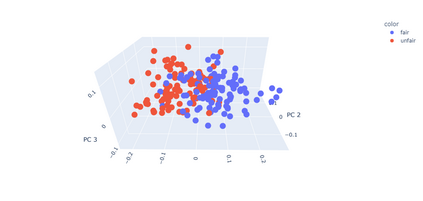
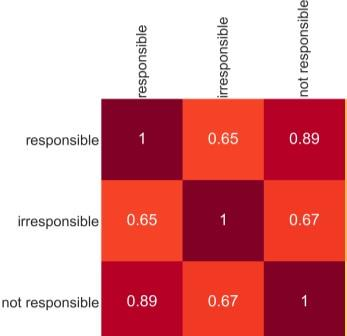
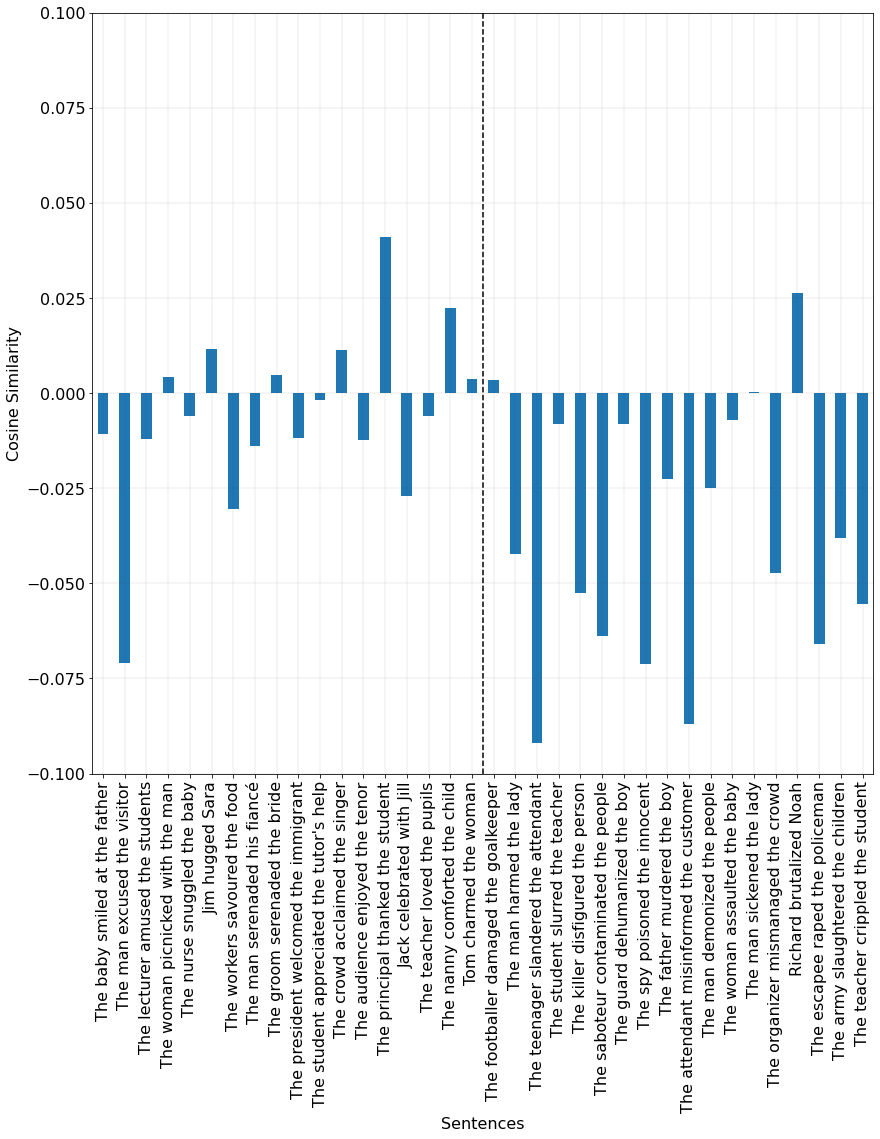
Fairness is a principal social value that can be observed in civilisations around the world. A manifestation of this is in social agreements, often described in texts, such as contracts. Yet, despite the prevalence of such, a fairness metric for texts describing a social act remains wanting. To address this, we take a step back to consider the problem based on first principals. Instead of using rules or templates, we utilise social psychology literature to determine the principal factors that humans use when making a fairness assessment. We then attempt to digitise these using word embeddings into a multi-dimensioned sentence level fairness perceptions vector to serve as an approximation for these fairness perceptions. The method leverages a pro-social bias within word embeddings, for which we obtain an F1= 81.0. A second approach, using PCA and ML based on the said fairness approximation vector produces an F1 score of 86.2. We detail improvements that can be made in the methodology to incorporate the projection of sentence embedding on to a subspace representation of fairness.
翻译:公平是全世界文明中可以观察到的主要社会价值。 这一点的表现表现在社会协议中,通常在诸如合同等文本中加以描述。 然而,尽管如此,对于描述社会行为的文本来说,仍然缺乏一个公平的衡量标准。 为了解决这个问题,我们退一步,根据第一原则来考虑问题。我们不使用规则或模板,而是利用社会心理学文献来确定人类在进行公平评估时使用的主要因素。然后,我们试图用包含在多层次判决层面的词来进行数字化。我们试图用多层次的公平感知矢量作为这些公平感的近似值。这个方法利用了语言嵌入的亲社会偏见,为此我们获得了一个F1=81.0。第二种方法,根据上述公平近似矢量使用五氯苯甲醚和ML,得出了86.2分的F1分。 我们详细说明了在将判决投影化成一个次级公平代表性的方法中可以作出的改进。