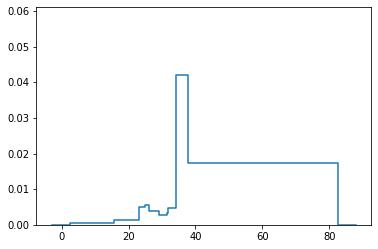
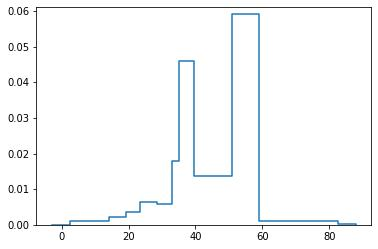
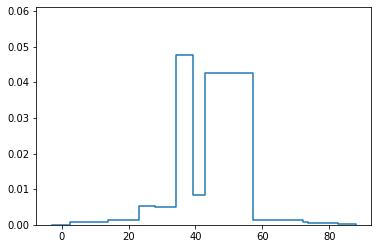
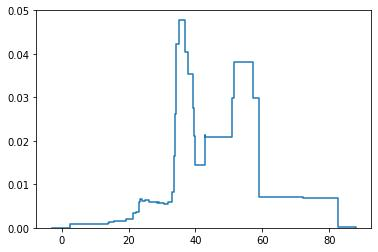
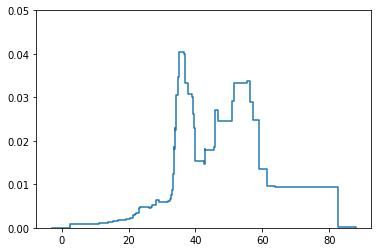
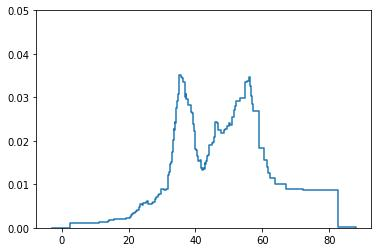
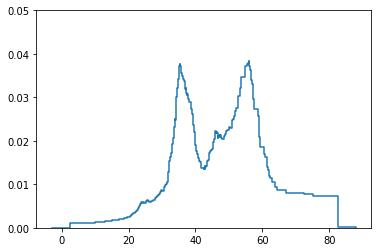
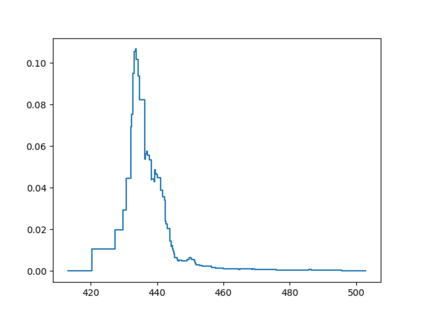
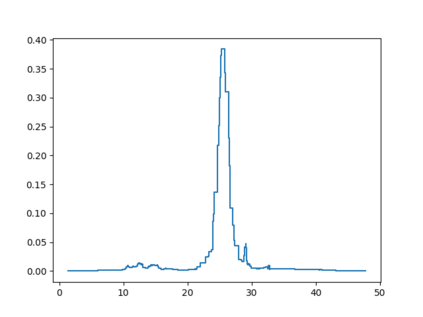
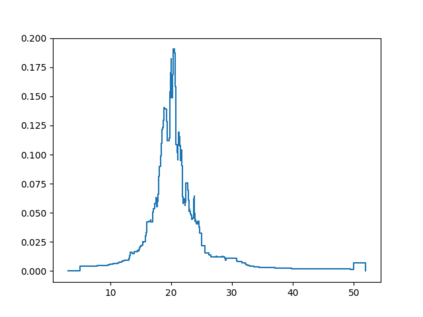
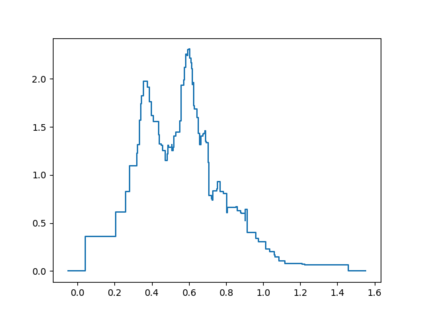
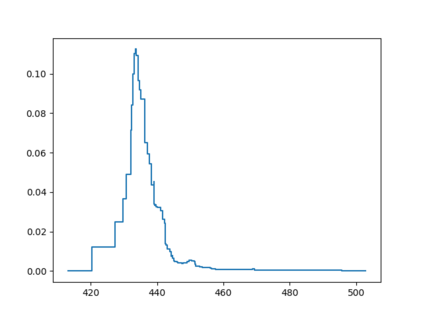
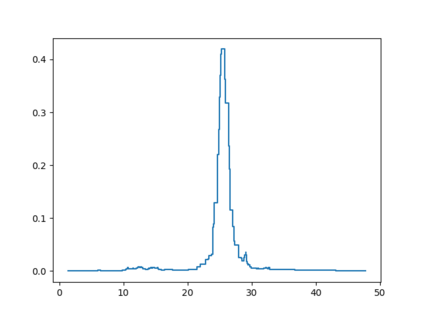
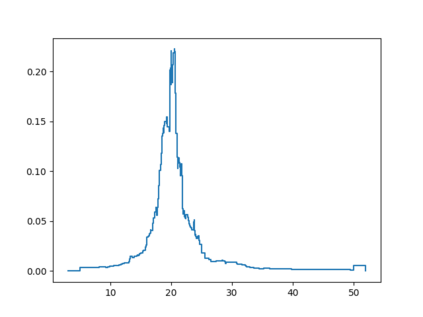
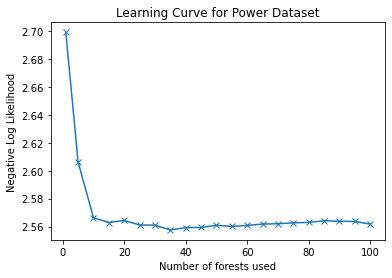
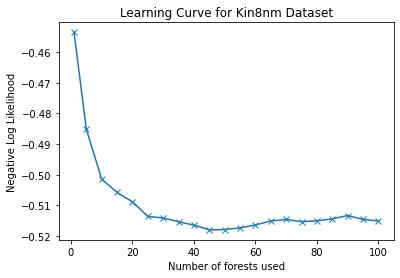
Probabilistic Regression refers to predicting a full probability density function for the target conditional on the features. We present a nonparametric approach to this problem which combines base classifiers (typically gradient boosted forests) trained on different coarsenings of the target value. By combining such classifiers and averaging the resulting densities, we are able to compute precise conditional densities with minimal assumptions on the shape or form of the density. We combine this approach with a structured cross-entropy loss function which serves to regularize and smooth the resulting densities. Prediction intervals computed from these densities are shown to have high fidelity in practice. Furthermore, examining the properties of these densities on particular observations can provide valuable insight. We demonstrate this approach on a variety of datasets and show competitive performance, particularly on larger datasets.
翻译:概率递减是指预测目标值的完全概率密度功能,以其特性为条件。我们对这一问题提出一种非参数性的方法,将接受不同目标值粗粗分析培训的基础分类器(典型梯度增强的森林)结合起来。通过合并这些分类器和平均得出的密度,我们能够计算出精确的有条件密度,同时对密度的形状或形式作出最低的假设。我们把这种方法与结构化的跨性机能损失功能结合起来,使由此产生的密度正规化和平滑。从这些密度中计算的预测间隔在实际中具有很高的忠诚性。此外,在特定观测中检查这些密度的特性可以提供宝贵的洞察力。我们在各种数据集上展示了这种方法,并展示了竞争性的性能,特别是在较大的数据集上。