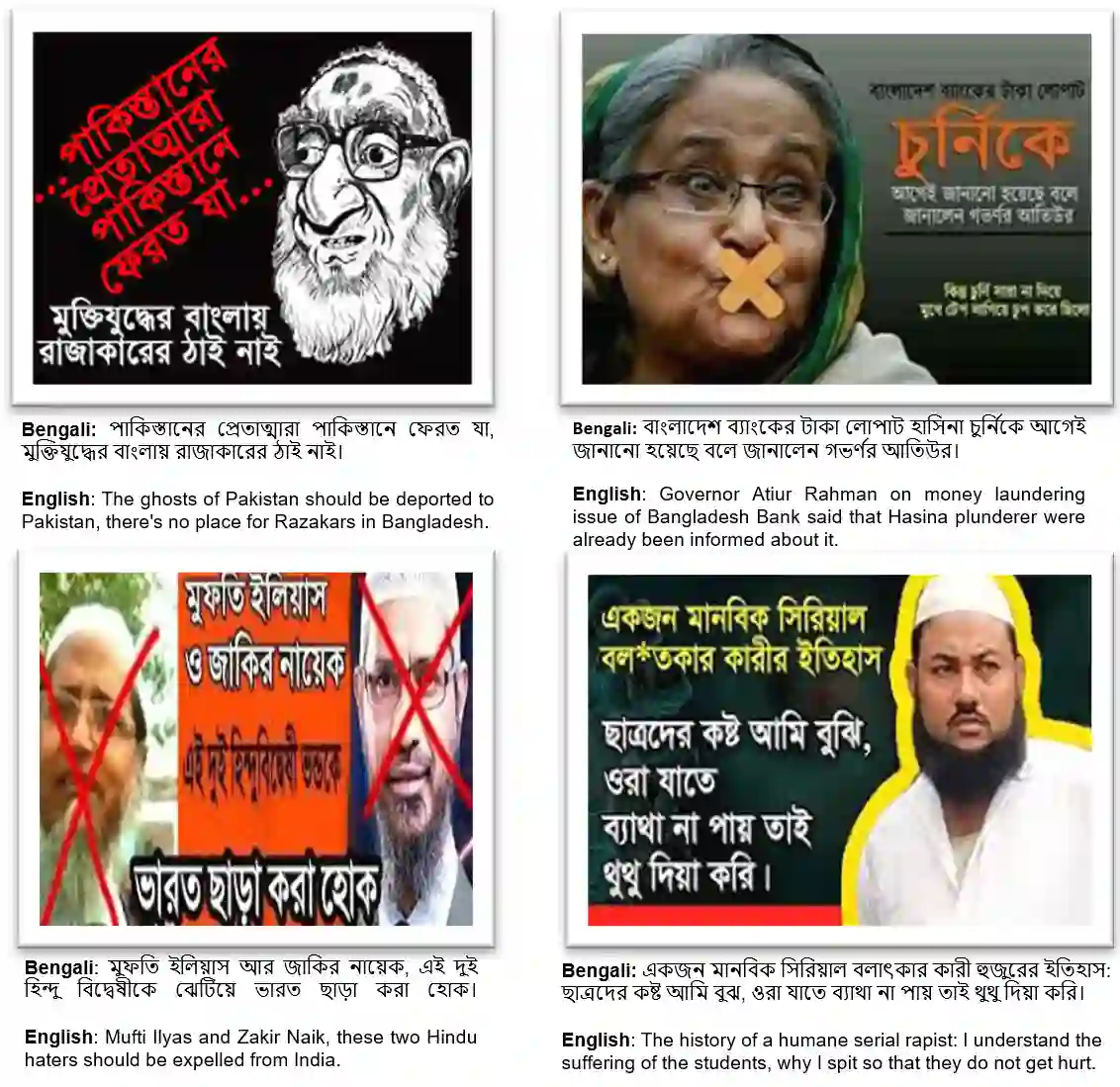
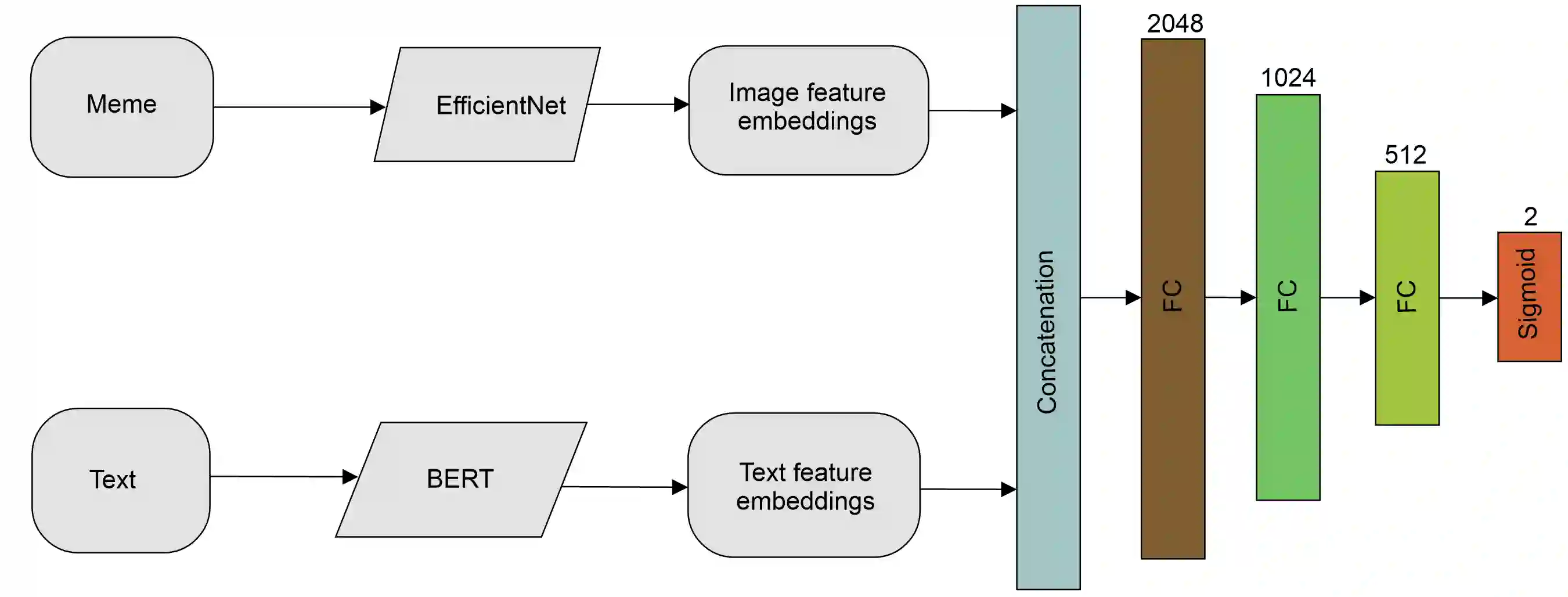
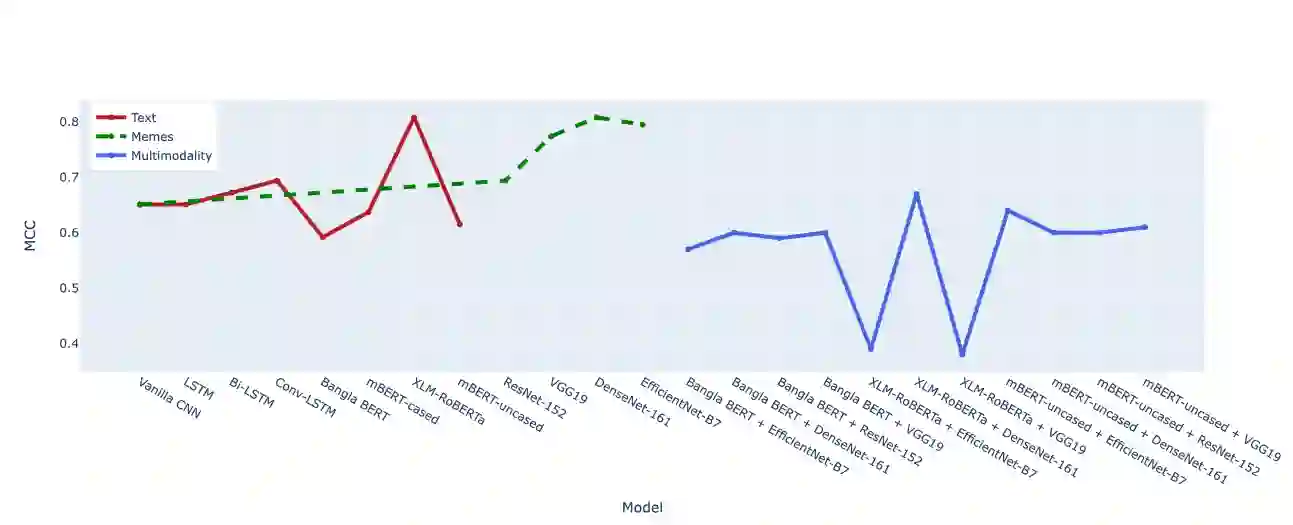
Numerous machine learning (ML) and deep learning (DL)-based approaches have been proposed to utilize textual data from social media for anti-social behavior analysis like cyberbullying, fake news detection, and identification of hate speech mainly for highly-resourced languages such as English. However, despite having a lot of diversity and millions of native speakers, some languages like Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Similar to other languages, Bengali social media contents also include images along with texts (e.g., multimodal memes are posted by embedding short texts into images on Facebook). Therefore, only the textual data is not enough to judge them since images might give extra context to make a proper judgement. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech dataset for-a-kind of problem for Bengali, which we use to train state-of-the-art neural architectures (e.g., Bi-LSTM/Conv-LSTM with word embeddings, ConvNets + pre-trained language models, e.g., monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) to jointly analyze textual and visual information for hate speech detection. Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet-152 and DenseNet-161 models yield F1 scores of 0.78 and 0.79, respectively. As for multimodal fusion, XLM-RoBERTa + DenseNet-161 performed the best, yielding an F1 score of 0.83. Our study suggests that text modality is most useful for hate speech detection, while memes are moderately useful.
翻译:许多机器学习(ML)和深层次学习(DL)都提议使用社交媒体的文字数据进行反社会行为分析,如网络欺凌、假新闻探测和识别仇恨言论,主要针对资源丰富的语言如英语。然而,尽管有许多多样性和数百万母语语言,孟加拉语等一些语言资源不足,原因是缺乏用于自然语言处理(NLP)的计算资源。 与其他语言一样,孟加拉语社交媒体的内容还包括图像和文本(例如,通过将短文本嵌入脸书,将MMMMMMMMMMMMMMMMMMRMMMMMRMRMRMRMRMMRMMRMMRMRMRMMRMRMRMRMRMRMMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRMRRMRMRMRMRMRMRMRMRM),我们分别进行BNRRRRRRRRMRMRMRRRRRMRRRRRMMMMMRRMMMMRRRRRRMMMMRRRR的文本,我们分别分别分别分别,我们为BRMMMMMMMMMMMM和MMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMM分别分别分别分别分别分别进行的图像,我们BRMMMMMMMMMMMMM和MMMMMMMMMMMMMMMMMMM的文本分别分别分别分别分别分别分别分别进行的版本,我们进行的文本,我们的文本,我们的文本, 和BRMMMMMMMMMMMMMMMMMMMMMM和BRMMMMMMMMM的文本,我们分别。我们的文本分别。我们的测试和BRMMMMMMMMMMMMMMMMMMMMMMMMMM